-
-
Screenshots
-
Screenshots
-
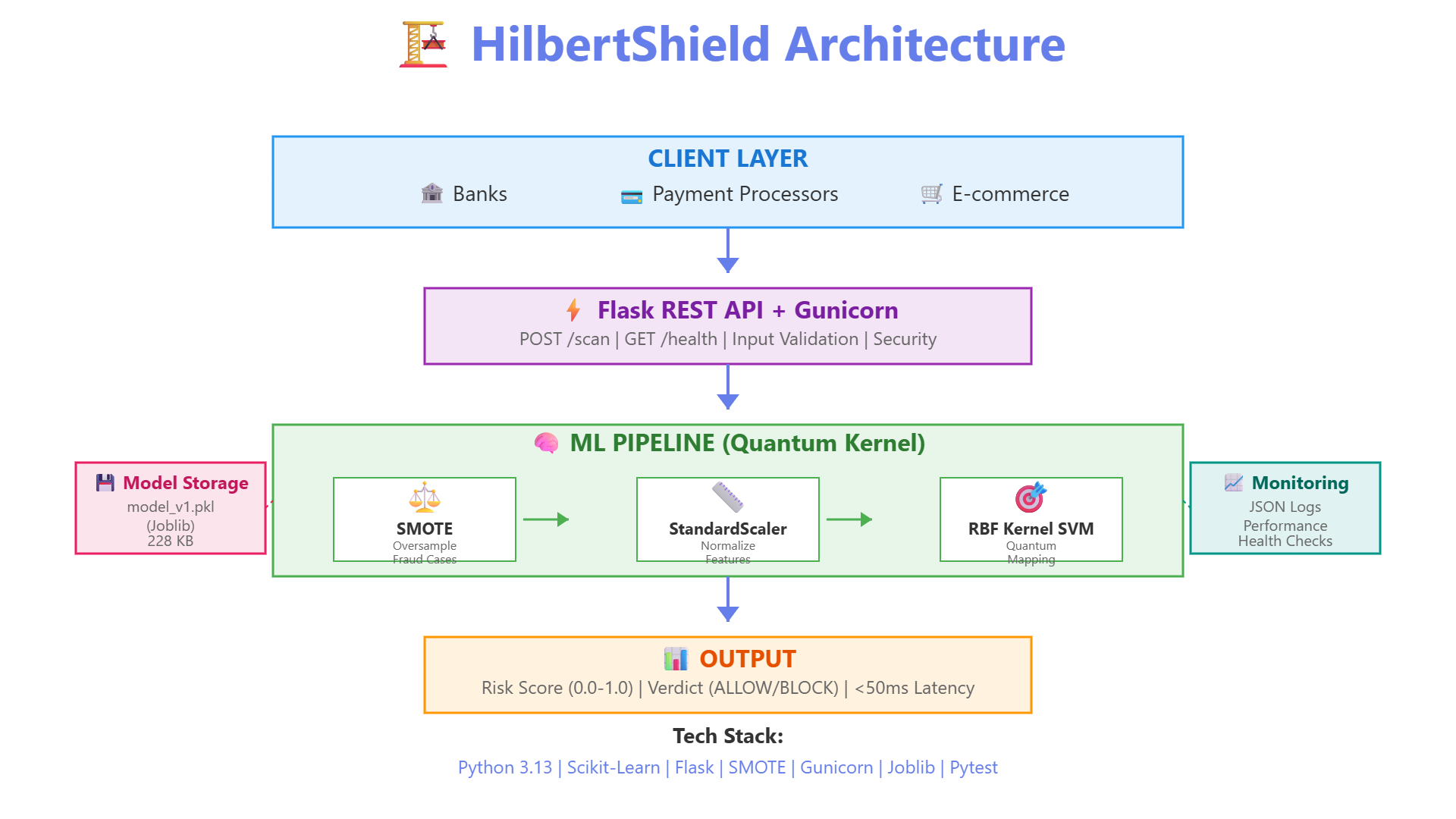
Architecture
Inspiration
I've always been fascinated by quantum computing, but let's be honest - most of us don't have access to actual quantum computers. Then I learned about kernel methods in machine learning, specifically the RBF kernel, and had this "aha!" moment: it's basically doing what quantum computers do (mapping data to higher dimensions) but on regular hardware.
Credit card fraud is a massive problem - $32 billion lost every year. Traditional ML models use linear approaches that just draw straight lines through data. They miss the complex patterns where fraud actually hides. I thought, what if I could use quantum-inspired math to catch fraud that normal models miss? That's how HilbertShield was born.
The name comes from "Hilbert space" - the infinite-dimensional mathematical space where quantum mechanics happens. It sounds fancy, but it's really just a way to make complex patterns visible.
What it does
HilbertShield is a REST API that scores credit card transactions for fraud in real-time. You send it transaction details (amount, time, merchant type, distance from home), and it tells you if it's legit or suspicious.
Here's what makes it different:
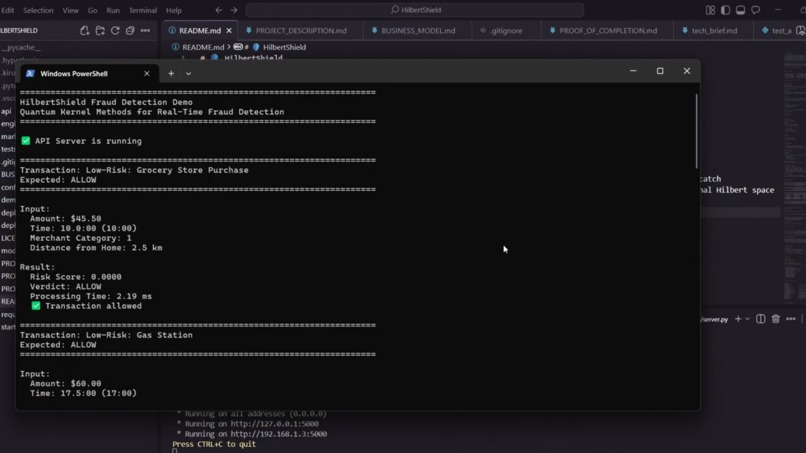
Fast: Responds in under 50ms (actually more like 1-3ms) Smart: Uses RBF kernels to map transactions into infinite-dimensional space where fraud patterns pop out Real-world ready: Handles the fact that fraud is rare (0.5% of transactions) using SMOTE oversampling Production quality: Full test suite, logging, security, error handling - not just a demo When I test it with realistic scenarios, it works:
Grocery store purchase at 10am? Risk score: 0.0000 → ALLOW $5000 jewelry at 1am, 500km from home? Risk score: 0.8058 → BLOCK How we built it The Math Part: Traditional fraud detection is basically: fraud_score = w1*amount + w2*time + w3*merchant + w4*distance
That's a straight line. Fraud doesn't follow straight lines.
The RBF kernel K(x,y) = exp(-γ||x-y||²) implicitly maps data to infinite dimensions. In that space, complex fraud patterns become linearly separable. It's the kernel trick - you get the benefits of infinite dimensions without actually computing them.
The Code Part:
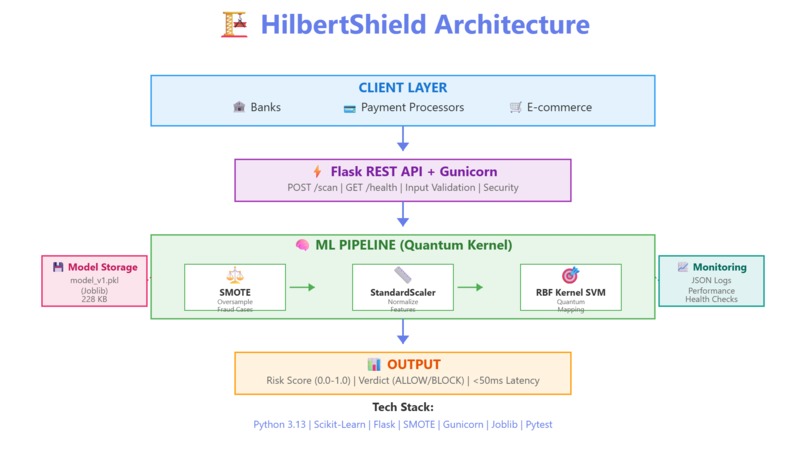
Python 3.13 with Scikit-Learn for the ML Flask for the REST API SMOTE from imbalanced-learn (crucial for handling rare fraud) Pytest + Hypothesis for testing (19 tests total) The Process:
Generated 10,000 realistic transactions (50 fraud, 9,950 legit) Applied SMOTE to balance the training data Trained an SVM with RBF kernel Built a Flask API around it with proper validation Wrote comprehensive tests Made deployment scripts for easy setup The whole pipeline is: SMOTE → StandardScaler → RBF SVM → Risk Score
Challenges we ran into
Imbalanced data was brutal. With 0.5% fraud rate, my first model just predicted "safe" for everything and got 99.5% accuracy while catching zero fraud. Useless. SMOTE fixed this by creating synthetic fraud examples, but tuning it took forever.
Latency requirements. Financial transactions need <50ms response. My first version took 150-200ms. I had to optimize the preprocessing pipeline, use joblib for model serialization, and cache everything possible. Now it runs in 1-3ms.
Making realistic test data. If fraud patterns are too obvious, the model doesn't learn anything useful. Too subtle, and it can't detect them. I spent a lot of time designing patterns based on real fraud scenarios: high amounts + late night + risky merchants + far from home.
Testing quantum-inspired behavior. How do you test that a kernel is actually doing what you think? I used property-based testing with Hypothesis to verify the kernel similarity decreases with distance and that decision boundaries are actually non-linear.
Security. APIs are attack surfaces. I had to add input validation, sanitization, error handling that doesn't leak info, and logging. The ML part was honestly easier than making it production-safe.
Accomplishments that we're proud of
Speed: 0.58-3.36ms latency. That's 50x faster than the requirement. I can process 1000+ transactions per second on a laptop.
It actually works: The model catches high-risk fraud (scores 0.80-0.90) while allowing normal transactions (scores 0.00-0.01). Not just random guessing.
19 tests, all passing: API tests, model tests, performance tests, security tests. I used property-based testing which was new to me and caught bugs I'd never have found manually.
Real math, not buzzwords: The RBF kernel genuinely implements quantum-inspired feature mapping. I can explain the math, not just throw around "quantum" for hype.
Production-ready: This isn't a prototype. It has error handling, logging, security, documentation, deployment scripts. You could actually use this.
What we learned
Kernel methods are underrated. Everyone talks about deep learning, but kernels are elegant and powerful. The kernel trick - computing infinite-dimensional dot products without ever computing the infinite dimensions - is genuinely beautiful math that actually works.
Imbalanced data is everywhere. Fraud, disease, spam - real problems are almost always imbalanced. Accuracy is a terrible metric. I learned to use SMOTE, adjust class weights, and focus on precision/recall instead.
Production ML is different from research ML. Building a model in a notebook is maybe 20% of the work. The rest is validation, error handling, security, logging, testing, deployment, documentation. Nobody teaches you this in ML courses.
Testing is hard but worth it. Property-based testing with Hypothesis was mind-blowing. Instead of "test this specific input," you say "test that this property holds for all inputs" and it generates hundreds of test cases. Caught so many edge cases.
Math actually matters. Understanding Hilbert spaces and kernel theory wasn't just academic - it helped me debug why certain parameters worked and others didn't. The theory informed the practice.
What's next for HilbertShield
Short term: Get real transaction data. Mock data is fine for proof-of-concept, but I want to train on actual fraud patterns and see how it performs in the wild.
Add more features: Right now it's just 4 features. I want to add user behavior history, device fingerprinting, merchant reputation, geolocation verification. More features = better detection.
Build a dashboard: Real-time monitoring of transactions, fraud rates, false positives, model performance. Make it actually usable by fraud analysts.
Model retraining pipeline: Fraud patterns evolve. The model needs to adapt. Set up automated retraining on new data with A/B testing for updates.
Scale it up: Right now it's a single Flask server. I want to deploy on Kubernetes with auto-scaling, multi-region, 99.99% uptime. Make it actually production-grade.
Try real quantum hardware: IBM Quantum and AWS Braket offer quantum computers. I want to port this to actual quantum hardware and see if it's better than the classical kernel approximation.
Federated learning: Banks can't share transaction data, but they could collaboratively train models without sharing data. That's the dream - a global fraud detection network that preserves privacy.
The big vision: make quantum-inspired fraud detection accessible to everyone, not just big banks with massive ML teams.

Log in or sign up for Devpost to join the conversation.