-
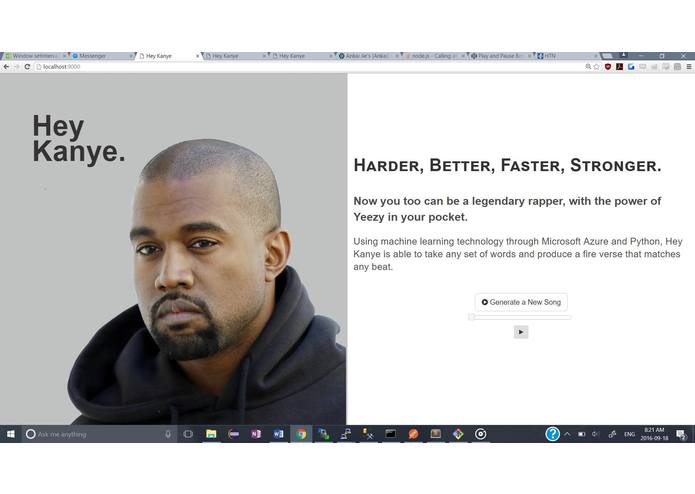
Website
-
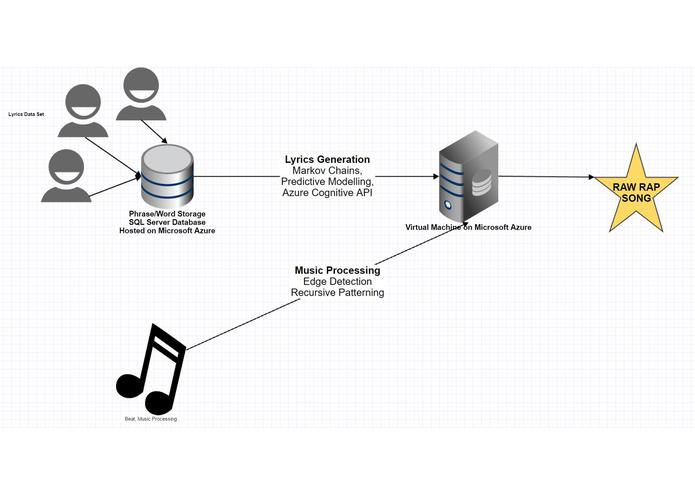
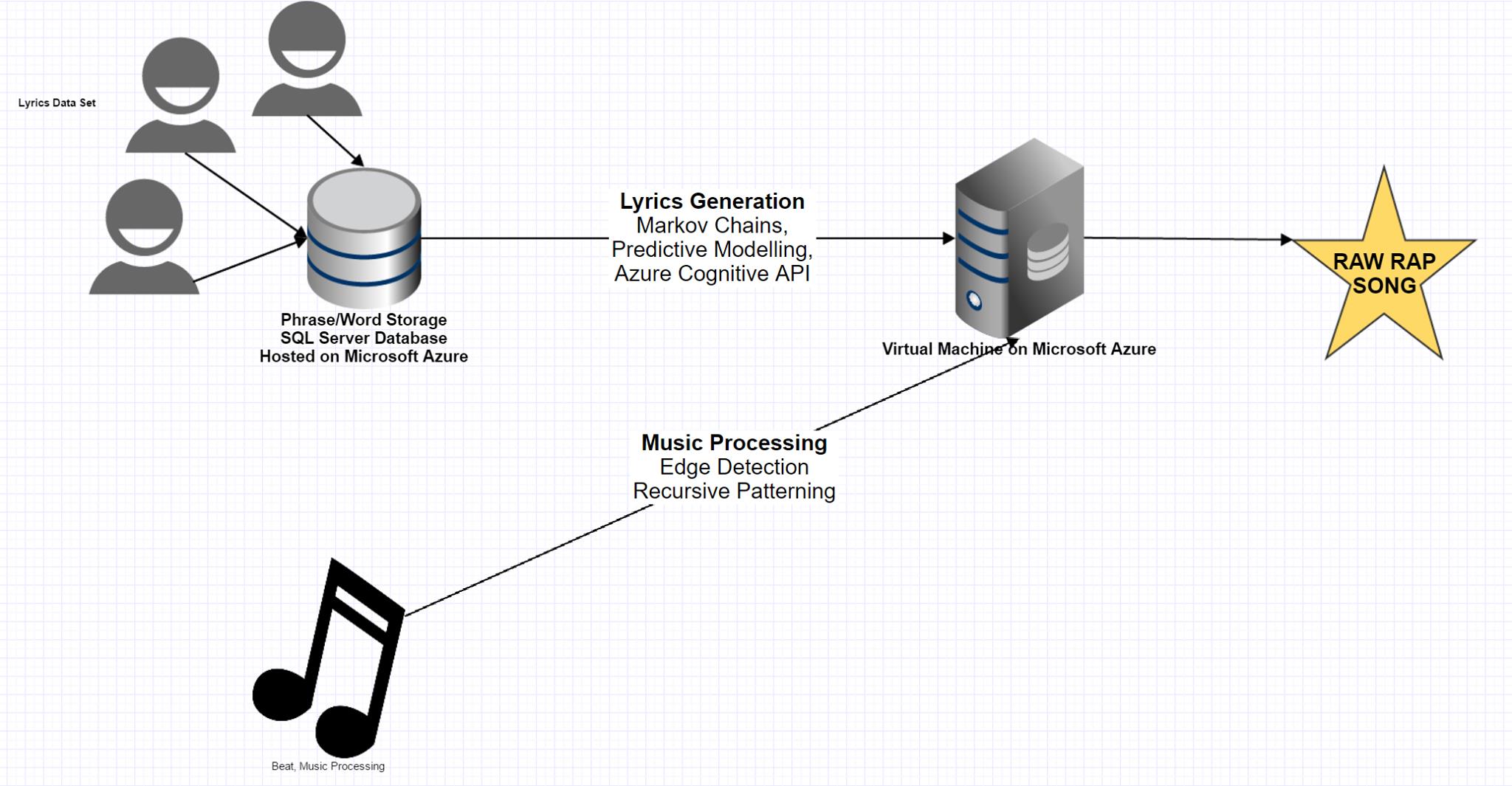
Visual representation of the process to generate a song
-

kanye.
-

kanye.
-

kanye.
-

kanye?!




Inspiration
We wanted to see what kind of things we can produce with structured grammar, synced to a beat.
What it does
HeyKanye takes song lyrics with valid grammar (eg. an artist's album, not necessarily yeezy) and an instrumental to generate a new song based on the inputs, with an artificial voice.
Features:
- sync lyrics to beats and proper chorus-verse structure for a structurally accurate song
- use multiple rhyme sequences to generate an accurate song
- detect the parts of beat with repetitive patterns
- use the grammar of the text file to generate a song with a similar style.
How we built it
We used music lyrics APIs to pull in bulk lyrics data to the database. We then further established database tables to map word relationships and line relationships. For example, our database stored data on common word pairs, common words in preceding lines of a word, common sentence structures, etc.
We used python to build Markov chains that likelihood of certain words following other words, similar to Swiftkey’s predictive text. By feeding our Azure SQL database the lyrics of the artists with which we want to base our rap on, our Markov chains become unique to that set of lyrics.
We defined the grammar used for the songs using parse trees (an ordered collection of Nouns, Verbs and Adjectives) built on top of the nltk library and connected our algorithm to Microsoft Azure's Web Language Model API. We also used common parse trees that were found in our dataset. We generated rap lines by conforming our Markov chains to valid parse trees.
From there, we seeded Azure’s algorithm with our generated sentences to add more vocabulary from the internet in the same style. Azure’s API was also used for validation and ensured only the sentences that made the most sense were used in our rap.
As for syncing the lyrics to the music, we used librosa to extract onset (key pitch and beat changes) features from the track. Using this data, we used an edge detecting algorithm and found the time differences between each onset in order to identify the timestamps chorus and the verses. Using that data, we use linux’s espeak to write the text-to-speech of our lyrics into .wav files with their timestamps as their filename. The speed of the speech was determined by the length of the verse relative to the timestamp it was allocated to. Once completed, we grafted every generated text-to-speech .wav onto the base beat to generate a new overlaid wav file which we converted to mp3.
Challenges we ran into
- Database issues... (as always)
- We went through many implementations of the HMM model to produce structurally correct data. We chose to construct the model based off word by word rather than line by line so we can have a truly random song implementation using grammar rules and parse trees.
- A lot of dirty things generated by words
- Connecting the back-end to the front-end
Accomplishments that we're proud of
None of us really had any experience with the stack before the hackathon and tried something new.
- entire audio detecting process / text-to-speech reproduction
- web-stack for our front end website
- HMM's to determine lyric generation
What we learned
- features of Azure's database as well as their multiple libraries for machine learning and nlp
- HMM models from scratch, with optimization through Microsoft Azure
- edge detecting algos with audio inspecting libraries.
What's next for HeyKanye
- Dynamic generation of different styles of songs based on user input
- Create different databases to store lyrics of different groups (i.e. different genres, different eras etc) that can be used to produce different styled songs
- Create a more full scale web application that permits sharing of music
- Any new text-to-speech libraries if they are made for different voices



Log in or sign up for Devpost to join the conversation.