-
-

home page
-
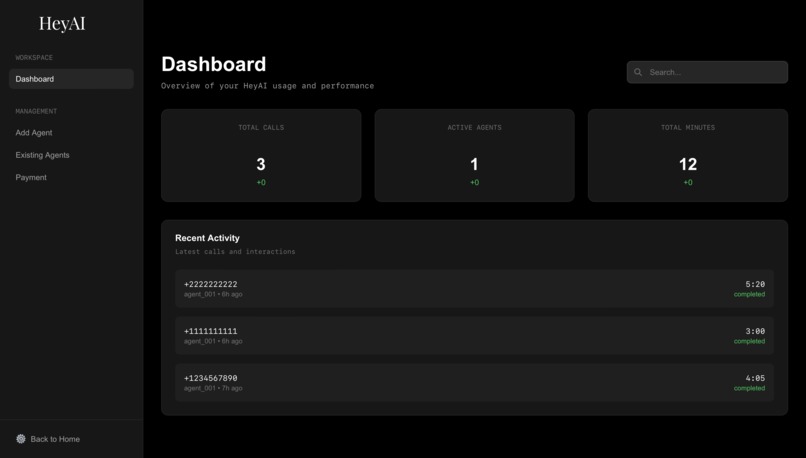
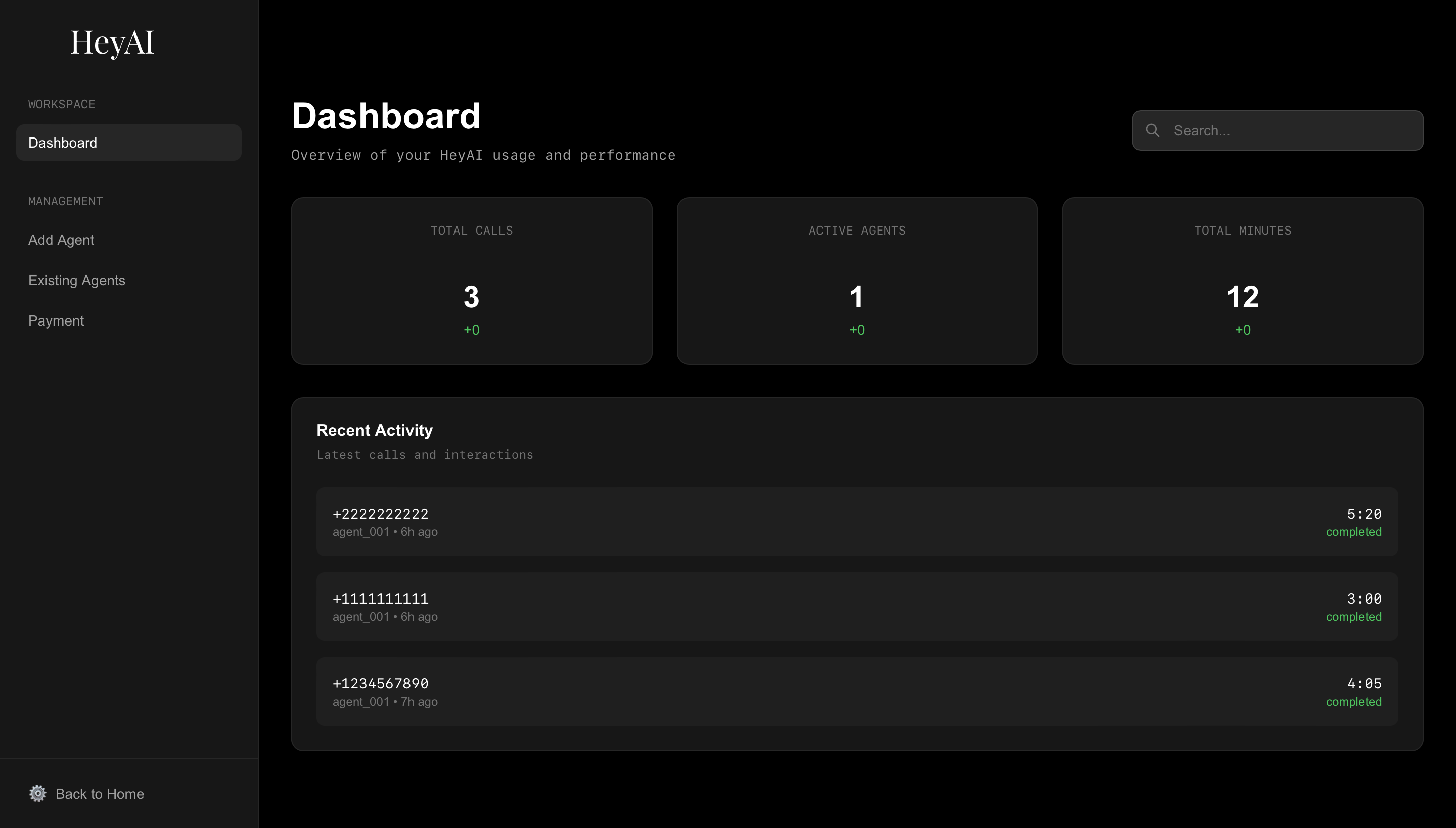
dashboard page
-
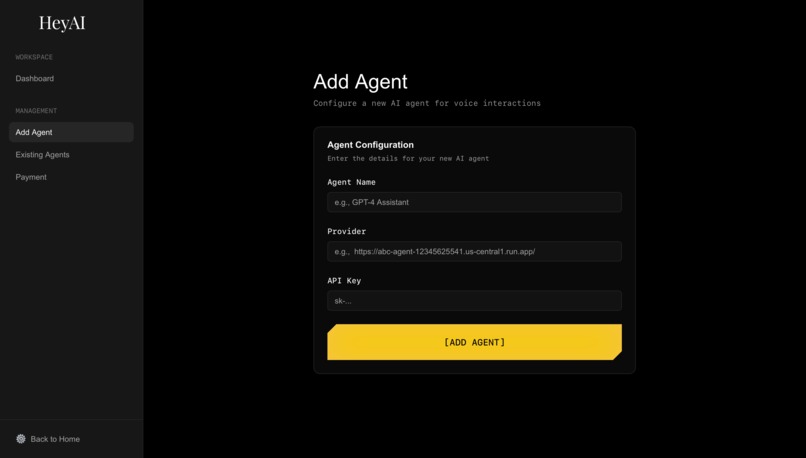
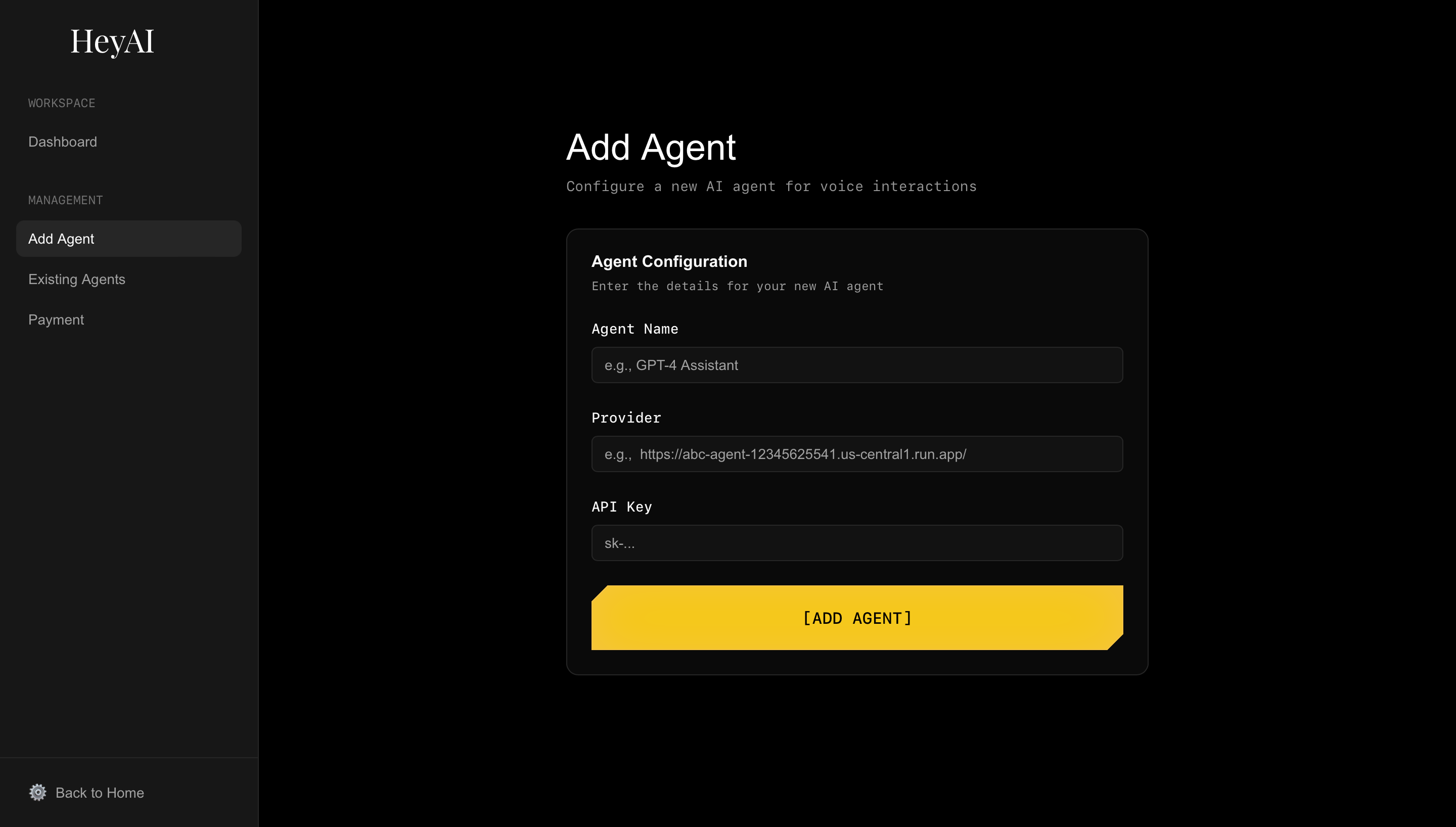
add agent page
-

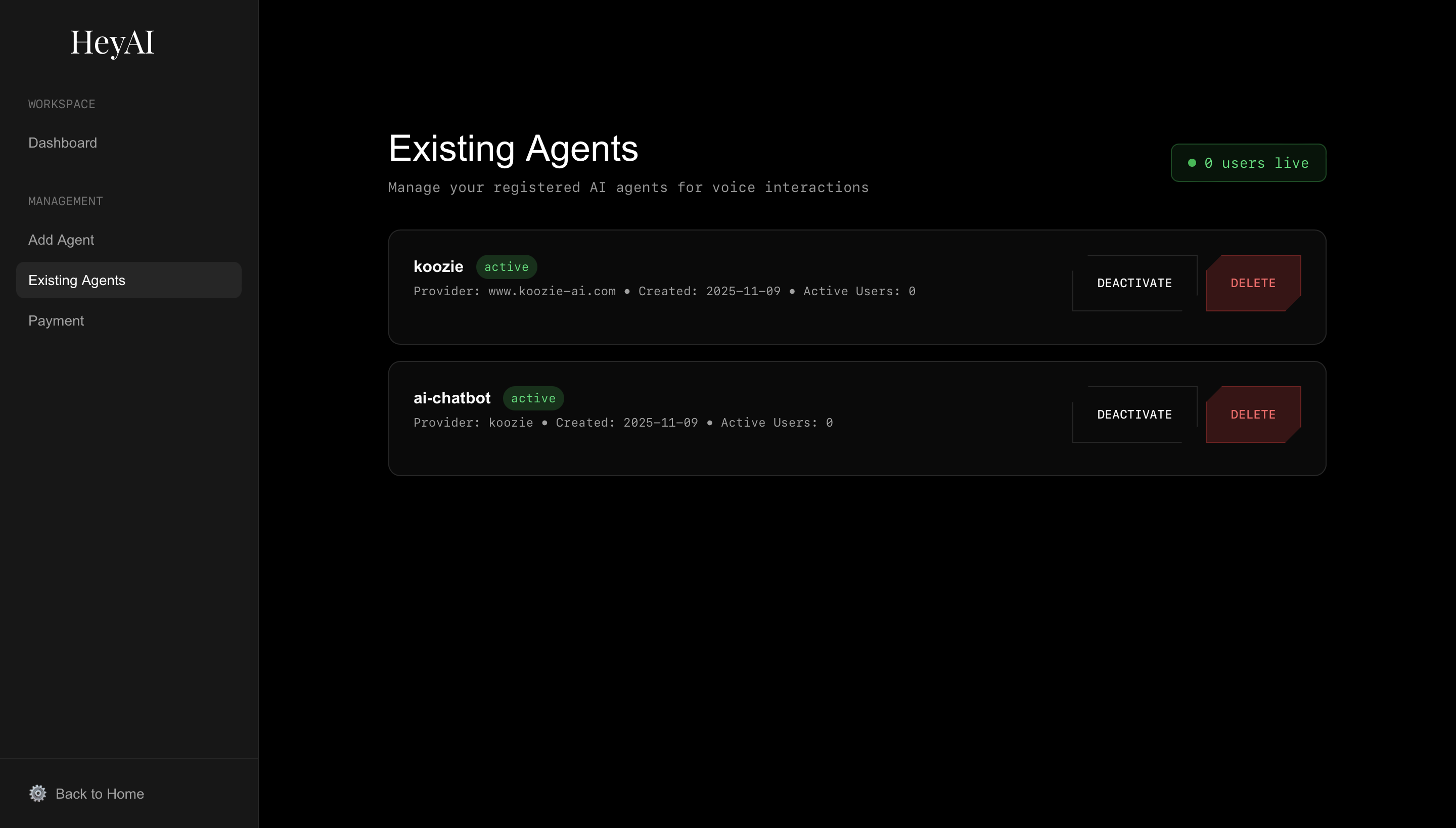
existing agents page
-
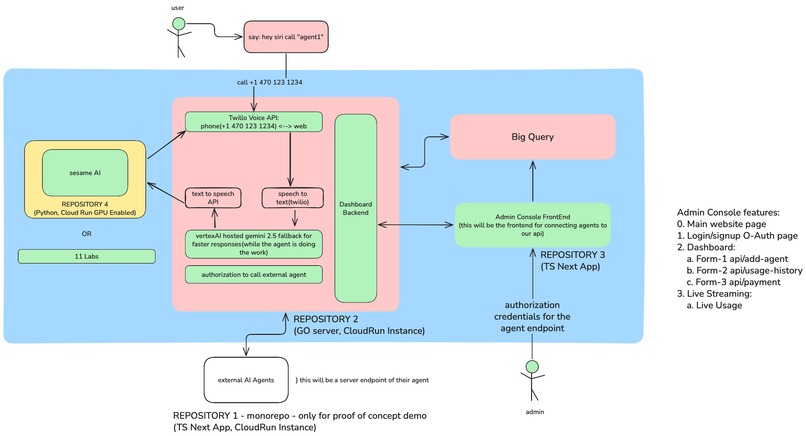
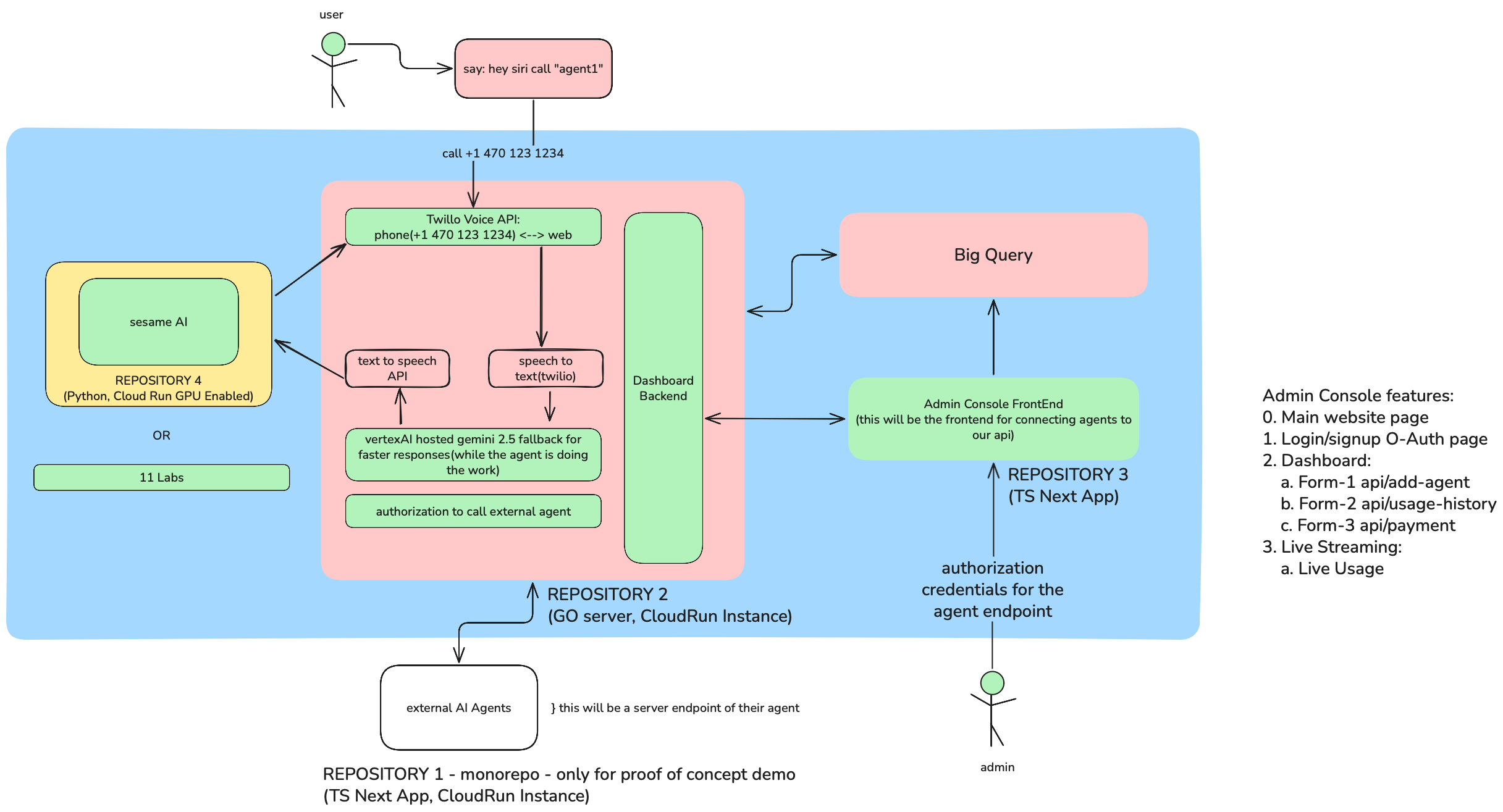
system architecture

Inspiration
In today's AI driven world, AI agents are everywhere. But these chatbots, virtual assistants, customer service bots are all trapped behind screens and keyboards. We asked: what if all AI agents could talk on the phone, with humans like identity? What if businesses could give their existing AI agents a voice without rebuilding everything? Hence, HeyAI was born as an idea to bridge this gap, making AI agents accessible through the most universal interface: a phone call.
What it does
HeyAI handles end-to-end voice infrastructure for AI agents! It's a complete platform that transforms any AI agent into a voice-powered assistant accessible via phone call:
Core Voice Pipeline:
- Receives phone calls through Twilio Voice API
- Converts caller's speech to text using real-time transcription
- Routes requests to any AI agent (we demo with Google Gemini 2.5 Flash)
- Converts AI responses to natural speech via ElevenLabs TTS
- Streams audio back to caller with minimal latency
- Maintains multi-turn conversation context
Admin Dashboard:
- Real-time monitoring of active calls per agent
- Analytics dashboard with success rates, call duration, and usage metrics
- Agent management interface for creating and configuring multiple AI agents
- Live user tracking showing exactly how many people are talking to each agent
- Call history and usage analytics powered by BigQuery
How we built it
Backend (Go): High-performance Go server handling Twilio webhooks Orchestrates the entire voice pipeline with concurrent request handling Streams responses for minimal latency Tracks active calls and per-agent usage in real-time Deployed on Google Cloud Run for auto-scaling Speech Processing:
Speech-to-Text: Twilio's built-in speech recognition Text-to-Speech: ElevenLabs API with Turbo v2.5 for natural voice synthesis Audio streaming with proper MP3 encoding and chunked delivery AI Integration:
Google Gemini 2.5 Flash via Vertex AI for lightning-fast inference Server-Sent Events (SSE) for streaming AI responses Stateless architecture for scalability Admin Console (Next.js):
Next.js 15 with TypeScript and Tailwind CSS Real-time dashboard with live user counts per agent BigQuery integration for analytics and data persistence 3D particle system landing page with WebGL Siri-like voice animation for visual feedback Infrastructure:
Telephony: Twilio Voice API with TwiML for call control Database: Google BigQuery for scalable analytics Deployment: Containerized on Google Cloud Run CI/CD: Automated builds with Cloud Build
Challenges we ran into
Latency Issues - Initial response time was 8+ seconds. We optimized by streaming, re-using Gemini context between request cycles, and reducing timeouts to get at 3-5 seconds.
TwiML Learning Curve - Twilio's XML-based response format was new to us. Understanding the webhook flow and proper TwiML structure took iteration.
Audio Streaming - Getting MP3 audio to stream properly through Twilio without buffering issues required careful header management and chunked responses.
Context Management - Maintaining conversation state across multiple webhook calls without a database was tricky. We solved it by keeping conversations stateless for the MVP.
Error Handling - Network failures, API timeouts, and edge cases (user says nothing, API down) required robust fallback mechanisms.
Accomplishments that we're proud of
- Built a working voice pipeline in 36 hours that sounds natural
- Achieved <5 second latency from speech to response
- Made it work on literally any phone worldwide
- Natural conversation flow with multi-turn support
- Clean, maintainable codebase that's easy to extend
- Solved a real accessibility problem. AI for everyone, not just smartphone users.
What we learned
Telephony Systems: Deep dive into Twilio Voice API, webhooks, TwiML, and the complexities of real-time voice communication. Audio Processing: MP3 streaming, codec handling, chunked transfer encoding, and real-time audio delivery over HTTP. Latency Optimization: Every millisecond matters in voice conversations. We learned to profile, optimize, and make architectural decisions based on latency requirements. Go for Real-Time Systems: Go's concurrency model and performance characteristics make it perfect for handling multiple simultaneous calls with minimal overhead. Multi-Service API Orchestration: Coordinating Twilio, Gemini, ElevenLabs, and BigQuery seamlessly while handling failures gracefully. Voice UX Design: Conversation flow is completely different from chat interfaces. Timing, pacing, and error handling require different approaches. BigQuery at Scale: Understanding streaming buffers, query optimization, and schema design for analytics workloads. Full-Stack Integration: Building a cohesive system where backend, frontend, database, and external APIs all work together seamlessly.
What's next for HeyAI
Short-term:
WebSocket Streaming - Reduce latency to <500ms. Multi-Agent Dashboard - Web interface to manage multiple AI agents and phone numbers Call Analytics - Track usage, conversation quality, and performance metrics Long-term:
Agent Marketplace - Let anyone deploy their AI agent with voice in one click Voice Cloning - Custom voices for brand consistency Multi-Language Support - Support 50+ languages automatically Enterprise Features - Call recording, transcription, sentiment analysis SDK Release - npm/pip packages for easy integration: heyai.connect(myAgent) Interrupt Handling - Let users interrupt the AI mid-sentence for more natural conversations
Built With
- bff
- elevenlabs
- golang
- google-bigquery
- google-cloud
- twilio
- twiml
- typescript
- vercel
- vertex-ai








Log in or sign up for Devpost to join the conversation.