-
-

-
Dashboard

(Disclaimer about the YouTube video. The second half of the video is an in-depth explanation of every single tool. Please don't be alarmed by the length, and you can speed it up)
Inspiration
Our original interest behind token optimization was piqued by news articles talking about how Mandarin was the "language of the future", and that they could prompt 40% more efficiently to AIs in Mandarin. This initially led us to look at the recent research that we eventually applied in this project. While brainstorming, we realized something that led us to decide that the research we did could definitely be applied to a specific use case...
Let's be real, everyone is trying to cram AI into their apps right now. But doing that usually leads to two giant headaches: your app gets hacked instantly by a prompt injection, or you get a massive API bill at the end of the month. We wanted to build a "bouncer" and an "accountant" for AI models. We named it Hermes, like the Greek messenger god, because it safely and cheaply delivers messages between users and the AI without losing the actual plot.
What it does
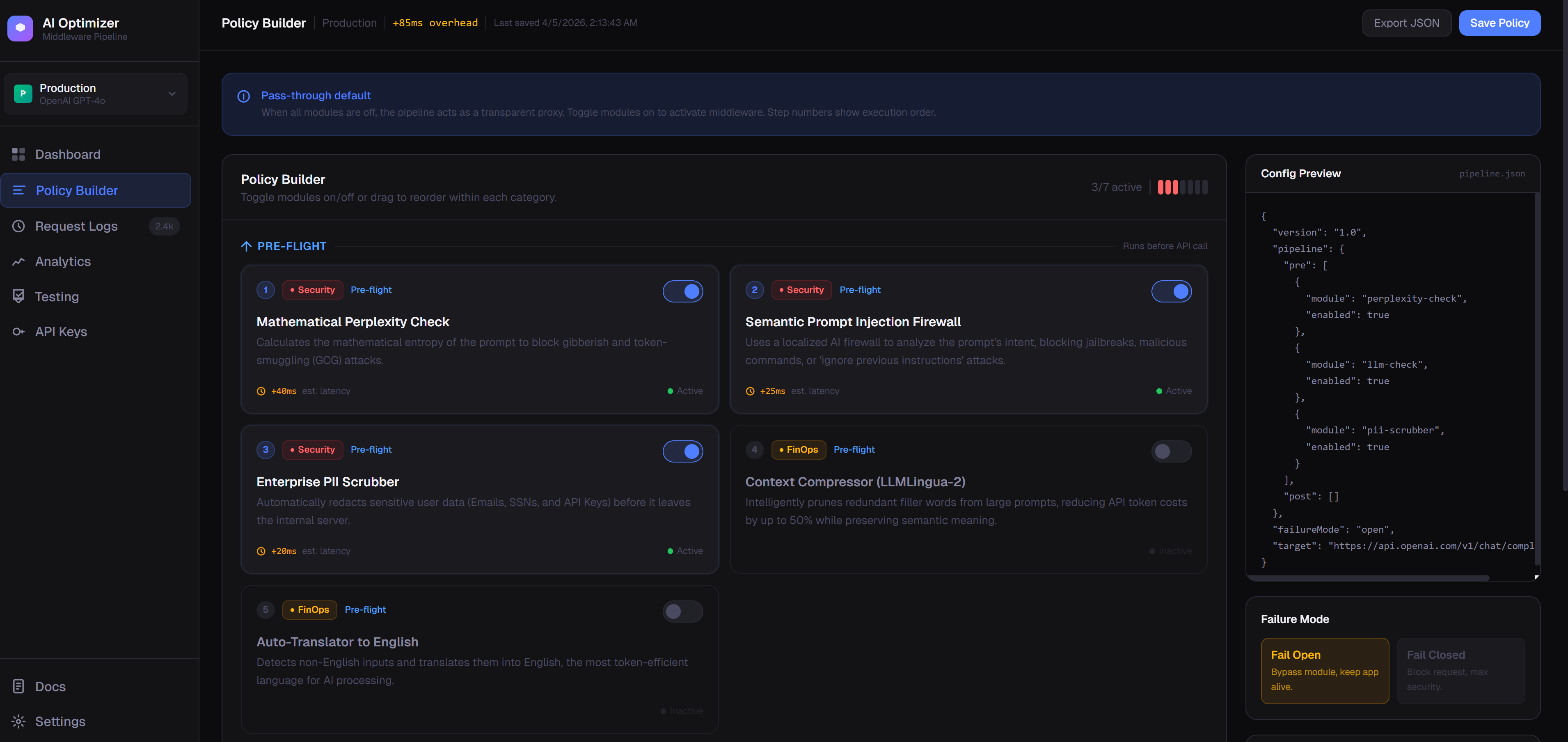
Hermes is a middleman that sits directly between our Next.js frontend and the main AI model.
Before the AI sees the prompt:
- Security: It runs math checks to see if someone is trying to sneak in a jailbreak attack. It also scrubs out sensitive stuff like emails and SSNs using Regex so that data never leaves the server.
- Cost Savings: It auto-translates foreign languages into English, which is way cheaper for the AI to read. Then it uses LLMLingua-2 to squeeze out useless filler words, cutting token sizes in half.
After the AI responds:
- Safety & Polish: It translates the English response back to the user's original language. It also runs a final check on the output just to make sure the AI didn't get tricked into leaking raw code or passwords.
How we built it
We built the frontend with Next.js so it looks clean and has nice toggles for all our features. The heavy lifting happens on a Python FastAPI backend. Instead of loading a bunch of giant models and completely frying our GPU, we got smart. We used Microsoft's LLMLingua-2 to compress the text and a tiny local Qwen model to handle the security firewall. We also used pure Python Regex for the PII scrubber and some lightweight libraries to handle the translating.
Challenges we ran into
We definitely hit some walls. Our biggest issue was prompt compression. At first, we used the original version of LLMLingua, which just deletes words it thinks are predictable. It absolutely butchered the grammar to the point where the AI thought we were feeding it a secret cipher. We had to completely pivot to the newer LLMLingua-2 to keep the text readable. Also, copying and pasting text from the internet brings in a lot of invisible, broken characters. We had to write a custom text cleaner just to keep the server from panicking every time we pasted something weird.
Accomplishments that we're proud of
We are super proud of how we managed the GPU memory. By having the compression model load first and then basically "stealing" its brain to run our security checks, we fit an entire multi-stage pipeline onto a normal consumer graphics card. It was also just really cool to see pure math, like calculating token entropy, successfully block a prompt injection attack in real time.
What we learned
We learned a ton about how AI actually charges you. For example, typing the exact same sentence in Japanese or Korean can cost three to four times as many tokens as English just because of how the AI reads it. Translating it locally first saves so much money. We also learned that AI tokenizers are surprisingly fragile when you feed them raw, uncleaned text (with how many times it broke, we were definitely more than a bit frustrated).
What's next for Hermes
For the next version, we want to add native prompt caching and a reranker so it can handle huge PDF documents even better. We also want to build a real-time analytics dashboard on the frontend so people can actually see the exact dollar amount they are saving and how many attacks Hermes blocked while they were sleeping.
Built With
- asyncio
- cuda
- fastapi
- fastapi-ai-&-machine-learning:-pytorch
- javascript
- javascript/typescript-frameworks:-next.js
- langdetect
- llmlingua-2-(xlm-roberta)-apis-&-utilities:-deep-translator-(google-translate-api)
- llmlingua-models:-qwen2.5-0.5b-instruct
- python
- pytorch
- regex
- regex-hardware/environment:-cuda-(gpu-acceleration)
- typescript

Log in or sign up for Devpost to join the conversation.