-
-

Logo
-
-
-
-
-

-


Inspiration
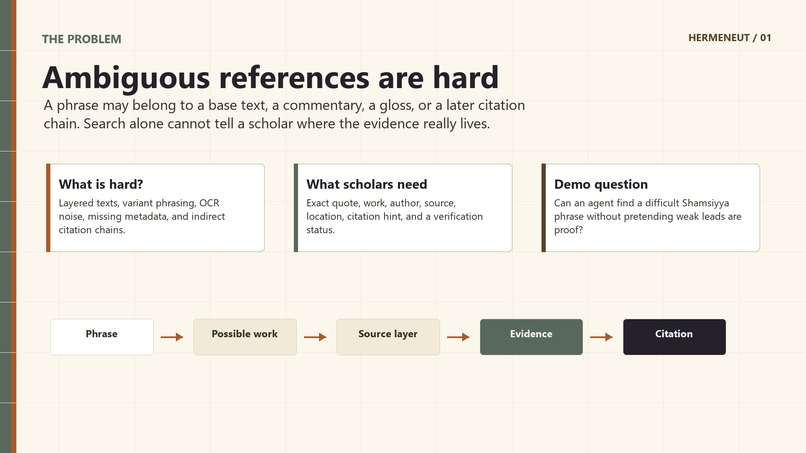
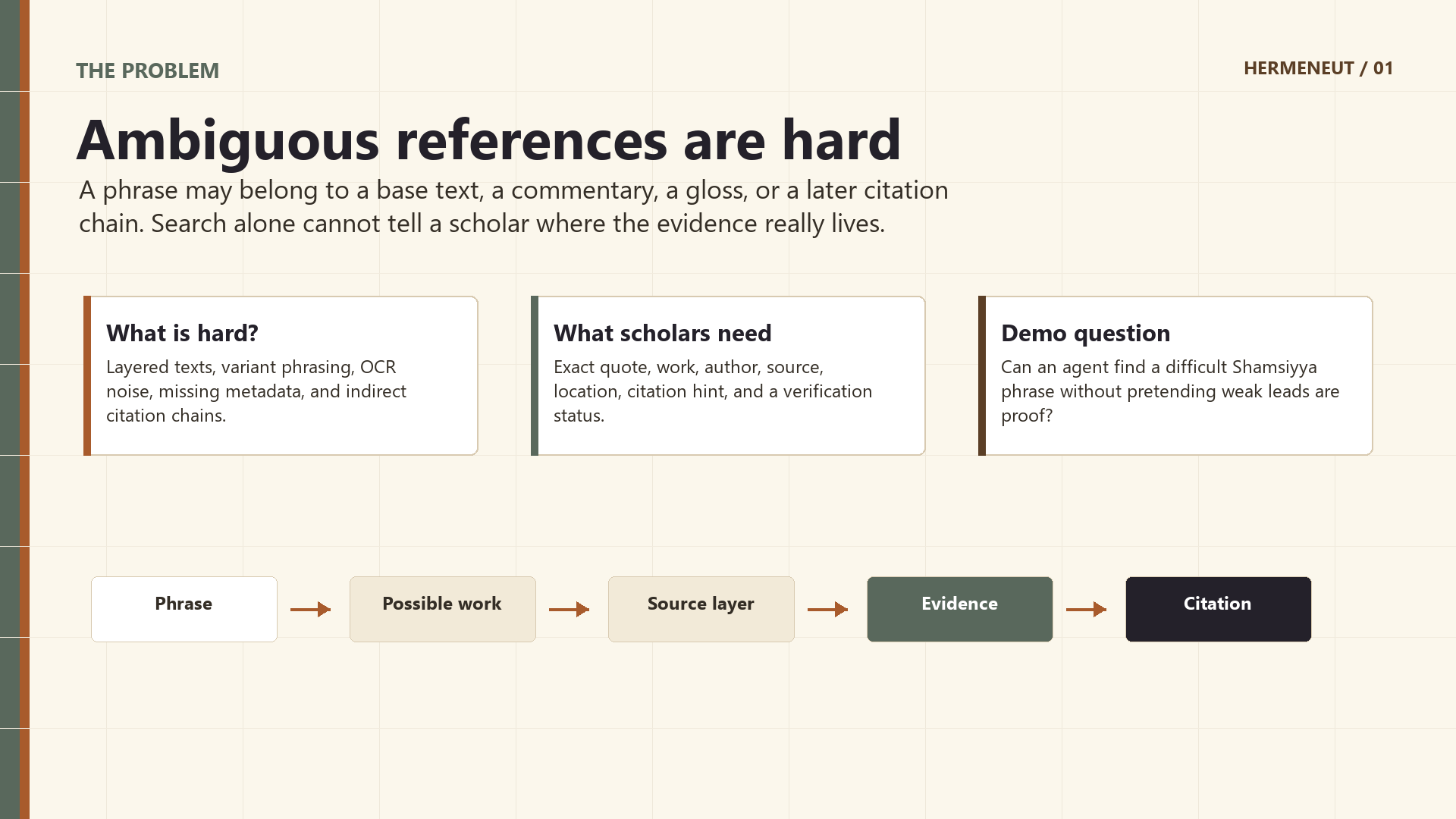
Classical scholarly texts are full of layered references: a phrase may belong to a base text, a commentary, a gloss, or a later citation chain. For researchers, the hard part is not only finding a similar phrase, but proving where it appears, in which work, by which author, in which source, and with what level of confidence.
Hermeneut was inspired by this problem: scholars need evidence-first research tools, not just generated answers.
What it does
Hermeneut is an evidence-first AI research agent for ambiguous references in classical texts.
It helps a researcher:
- search a curated library of OCR/indexed sources,
- find exact or near-exact textual evidence,
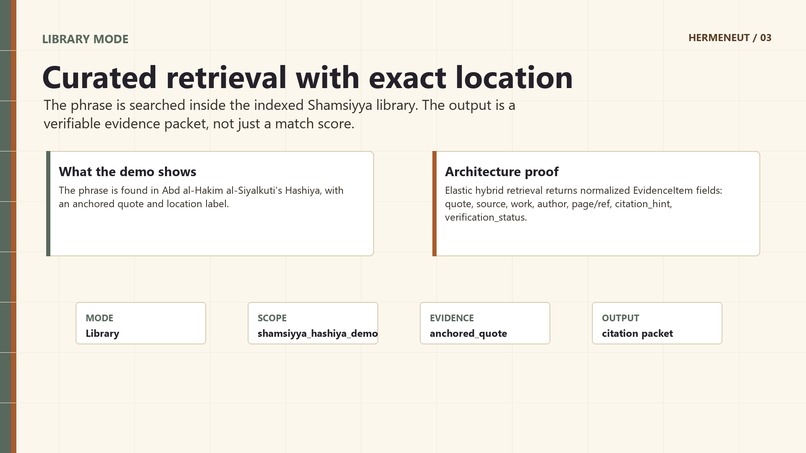
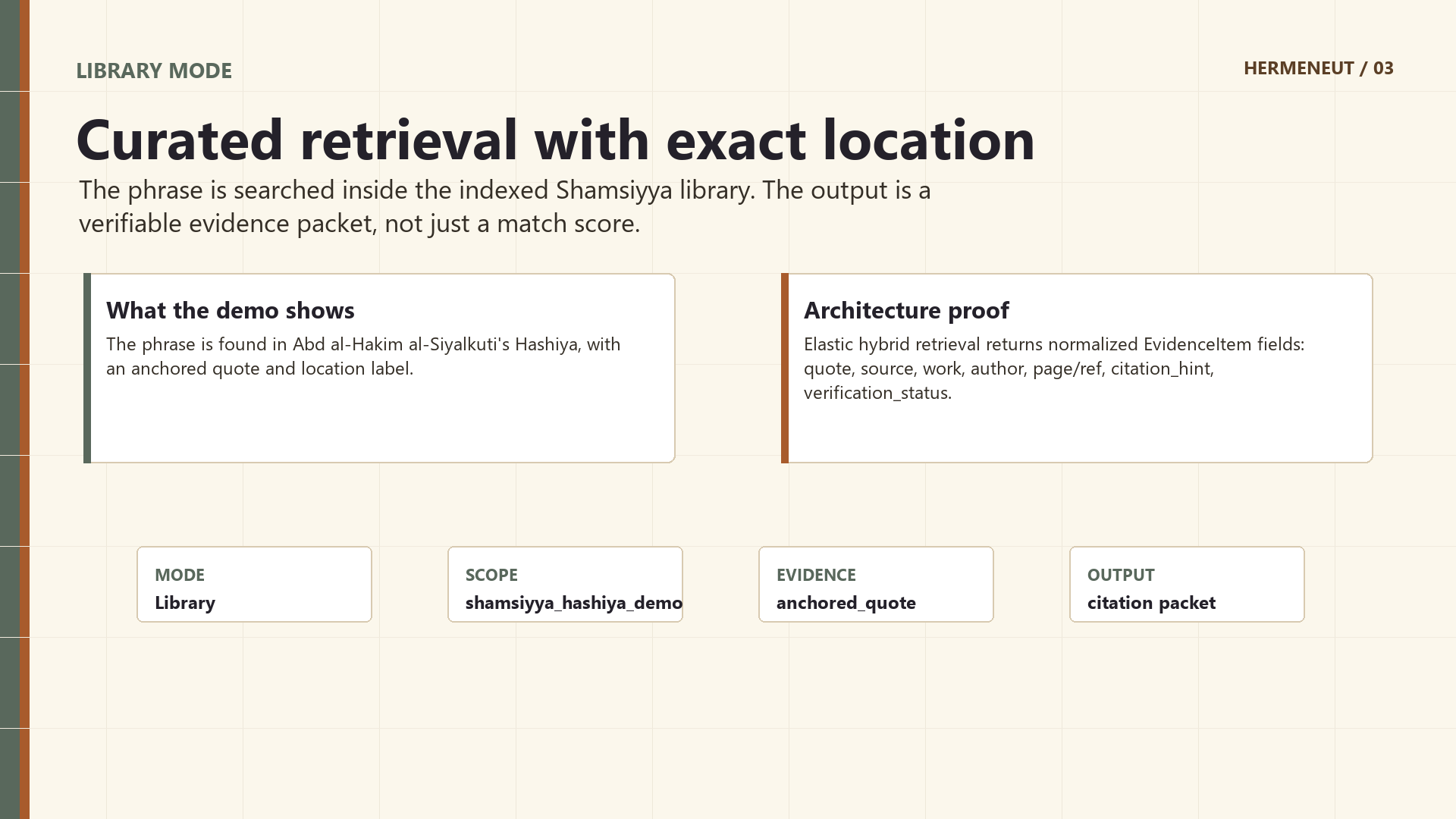
- see the quote, author, work, source, location label, and citation hint,
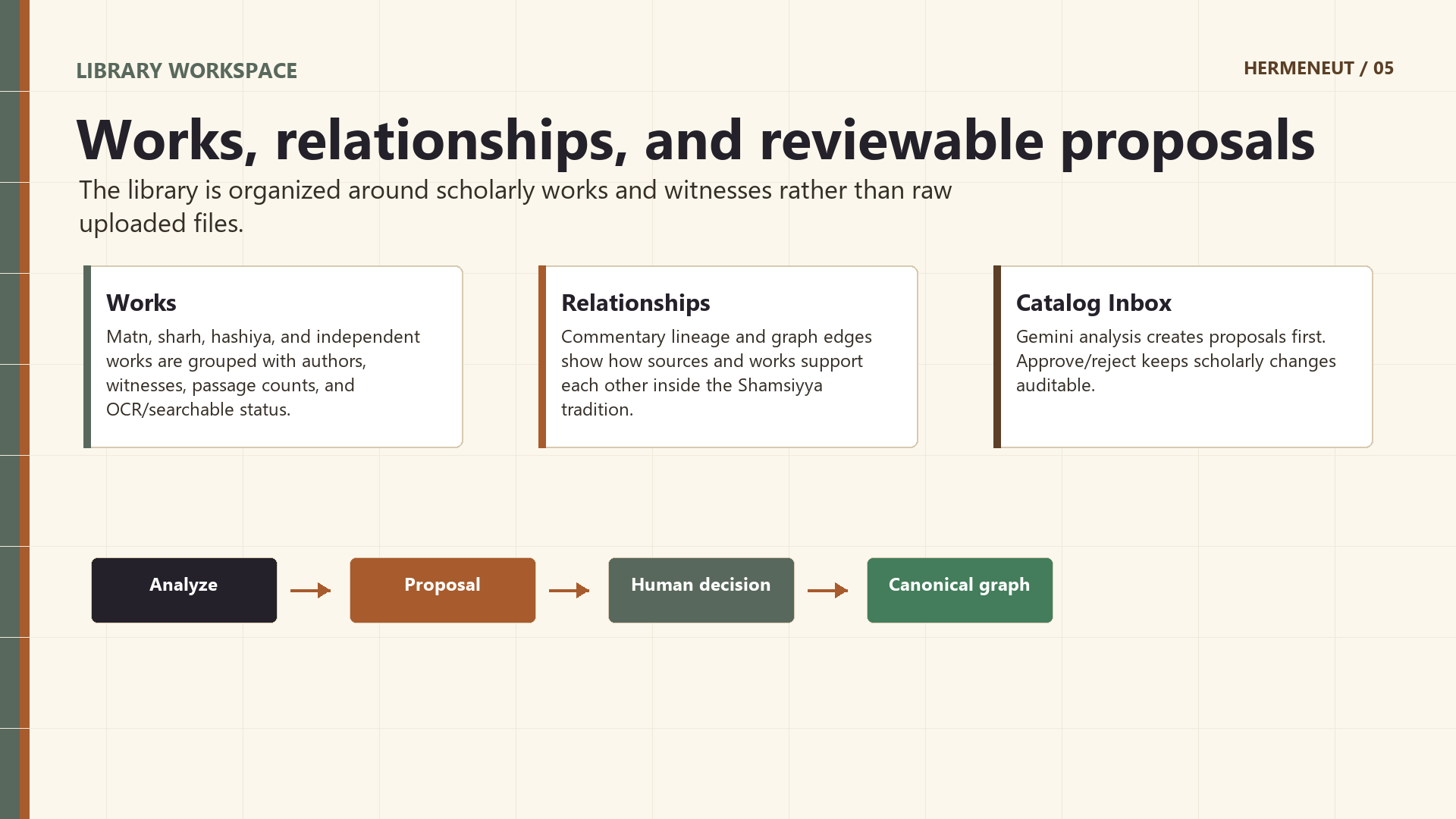
- inspect relationship graphs between works and witnesses,
- run controlled Open Discovery beyond the curated library,
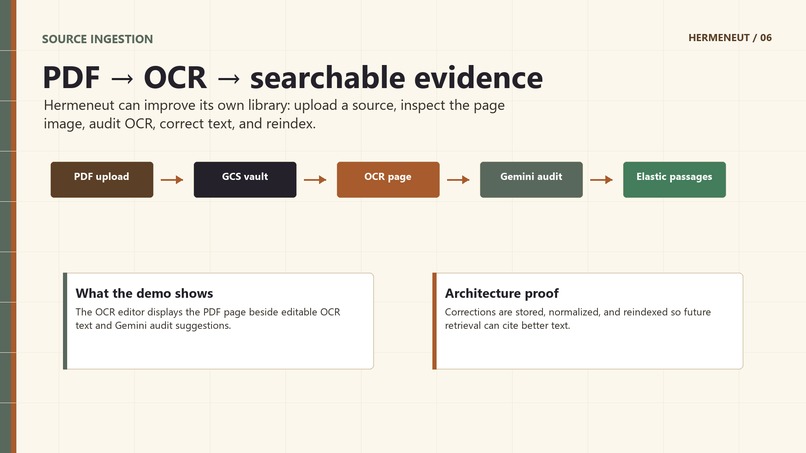
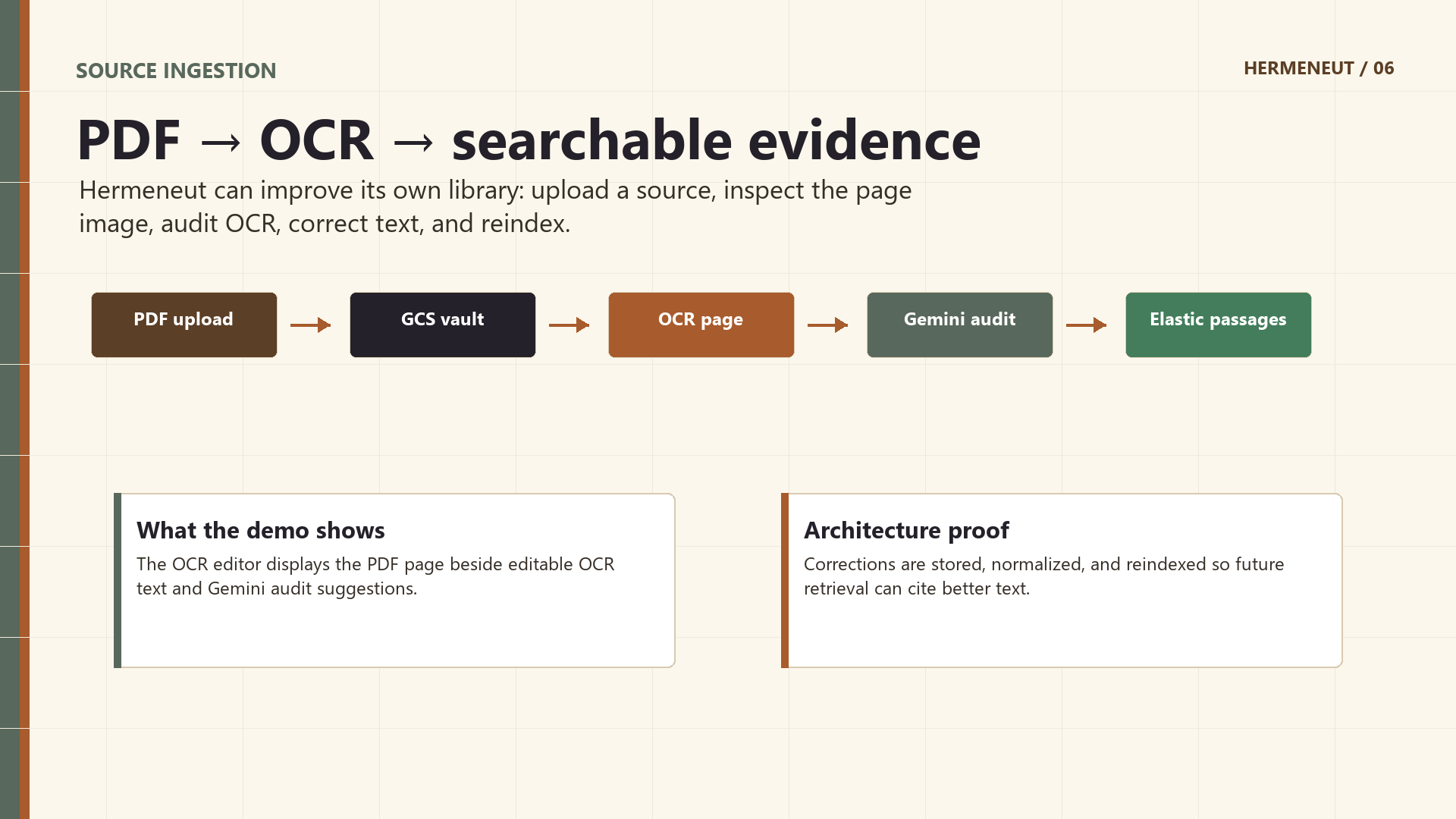
- process source candidates through OCR/indexing,
- keep weak source leads separate from verified textual evidence,
- review Gemini-generated catalog and relationship proposals,
- inspect OCR pages and apply human-approved corrections.
In the demo, Hermeneut searches a difficult phrase from the Shamsiyya commentary tradition and shows both a successful Library Mode result and a controlled Open Discovery result that refuses to overclaim when evidence is weak.
How we built it
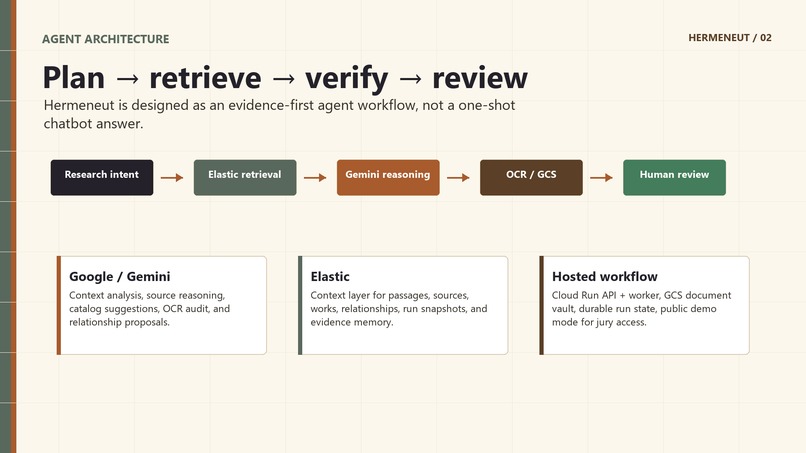
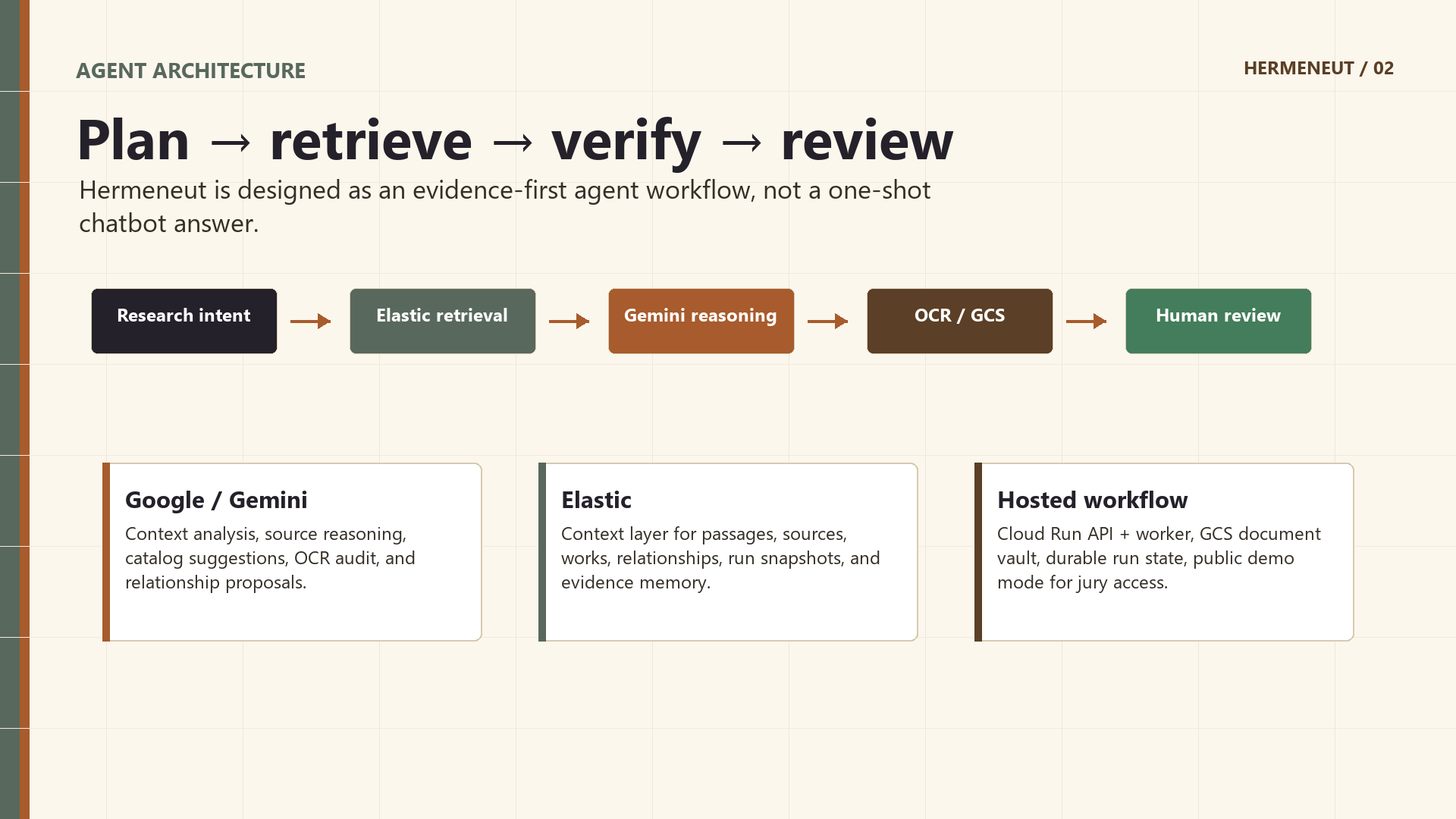
Hermeneut is built as a multi-step research agent rather than a single chatbot response.
The main components are:
- Gemini for reasoning, source analysis, catalog proposals, relationship analysis, and OCR audit suggestions.
- Elastic as the retrieval, context, evidence, memory, and relationship layer.
- Google Cloud Run for the hosted API and worker execution.
- Google Cloud Storage for PDF/source storage and OCR artifacts.
- Google Cloud Vision OCR for turning uploaded PDFs into searchable passages.
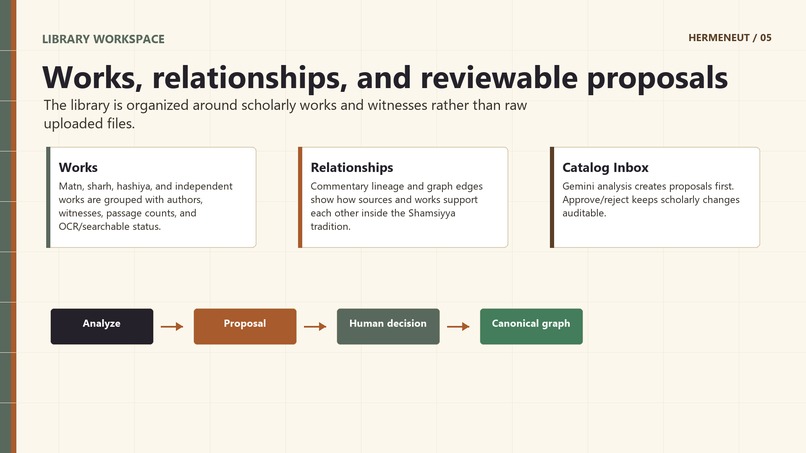
- Human-in-the-loop review for catalog proposals, relationship graph updates, and OCR corrections.
- A Next.js web interface focused on Library Mode, Open Discovery, RunView evidence presentation, Library workspace, Catalog Inbox, Relationship Graph, and OCR Editor.
The core design principle is: no scholarly claim should be upgraded unless textual evidence supports it.
Challenges we ran into
The hardest challenge was balancing discovery with reliability.
Open Discovery can find promising sources, but source leads are not the same as evidence. Some external sources have weak OCR, missing metadata, or noisy text layers. We had to make the system show these leads clearly without turning them into unsupported claims.
Other challenges included:
- normalizing author/work/source metadata,
- keeping library-scoped retrieval from leaking across collections,
- showing complex evidence in a readable UI,
- representing commentary and gloss relationships as a graph,
- making OCR correction useful without hiding the original page image,
- designing a demo-friendly public mode while preserving the idea of human review.
Accomplishments that we're proud of
We are proud that Hermeneut does not just produce an answer. It produces an evidence packet.
A good result includes:
- exact quote,
- author,
- work,
- source,
- page or passage reference,
- citation hint,
- verification status,
- confidence tier,
- neighboring passage context,
- relationship graph support.
We are also proud of the Open Discovery behavior: when external source processing produces weak OCR or no reliable textual match, Hermeneut keeps the result as a weak lead instead of pretending it has proof.
That restraint is central to the product.
What we learned
We learned that research agents for scholarly work need strong boundaries between:
- candidate and evidence,
- source lead and verified quote,
- OCR text and corrected text,
- model suggestion and human-approved catalog record,
- relationship proposal and canonical graph edge.
We also learned that UI matters deeply. A scholar needs to see why a result is trustworthy: not just a score, but the source, quote, citation, and verification path.
What's next for Hermeneut
Next, we want to make Hermeneut more useful for libraries, manuscript collections, and research institutes.
Planned directions include:
- larger corpus ingestion,
- richer manuscript and edition metadata,
- stronger OCR/HTR workflows,
- better citation export,
- more advanced relationship graph review,
- collaborative curator workflows,
- evaluation sets for attribution and evidence quality,
- deeper Elastic-backed memory and context retrieval.
The long-term vision is to turn digitized classical text collections into auditable research infrastructure: searchable evidence, reviewable metadata, relationship graphs, and citable findings.
Built With
- cloud-run-jobs
- elastic
- elasticmcp
- elasticsearch
- fastapi
- gcr
- gcs
- gemini
- googlecloudvisionocr
- next.js
- pydantic
- pymupdf
- python
- react
- tailwindcss
- typescript

Log in or sign up for Devpost to join the conversation.