-
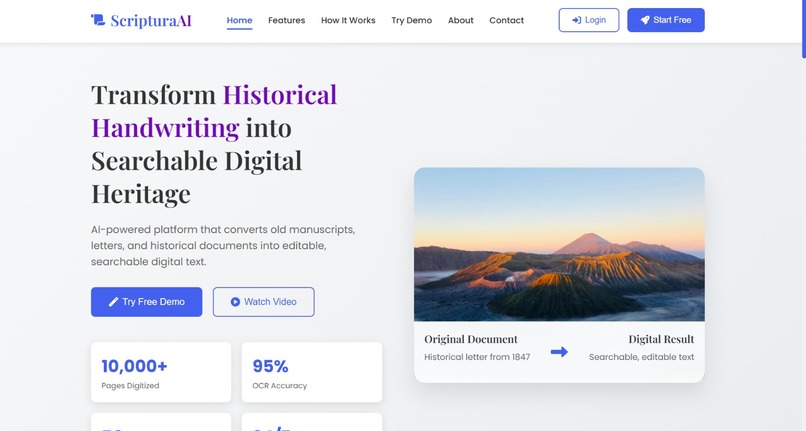
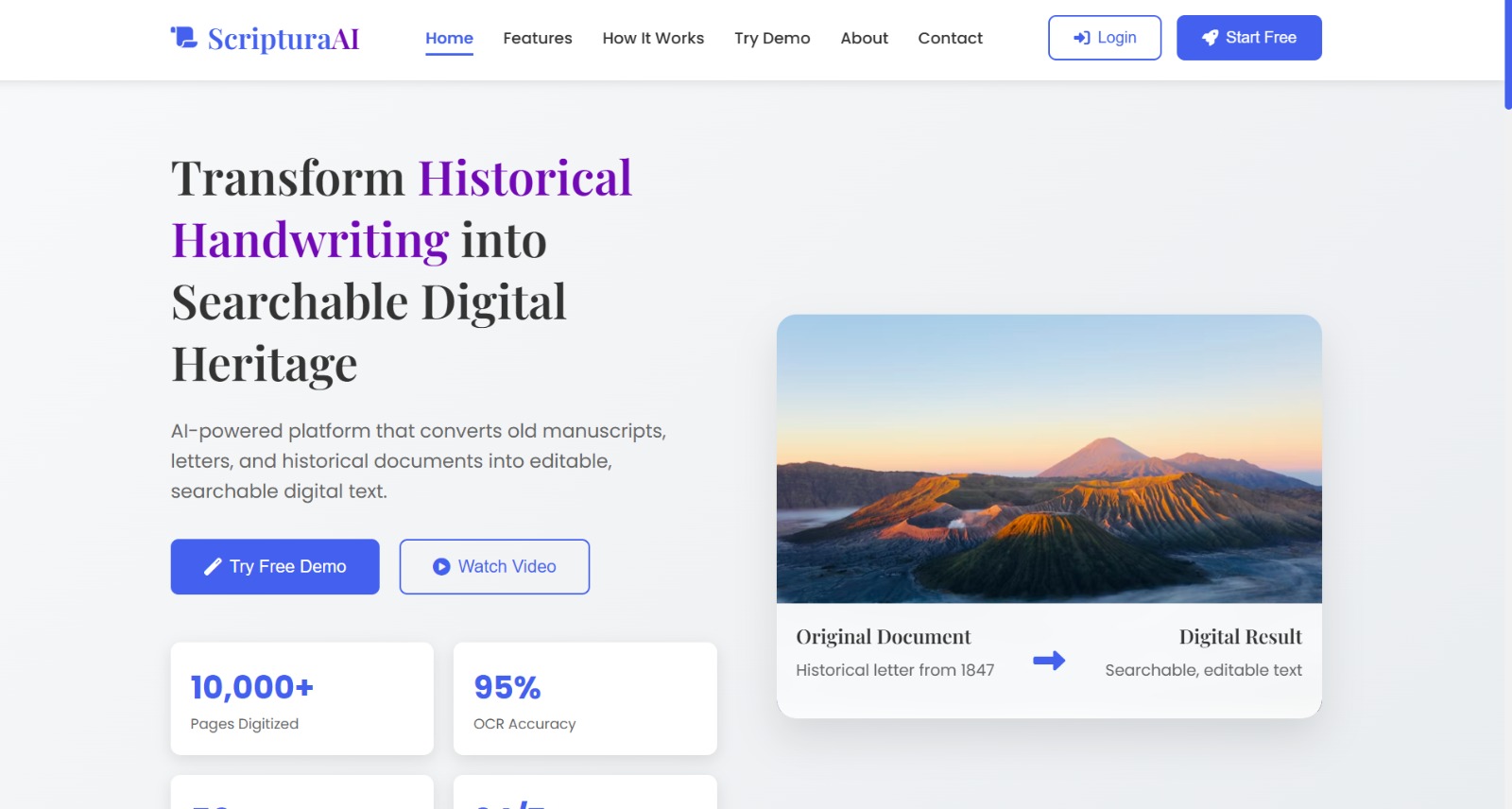
home page
-
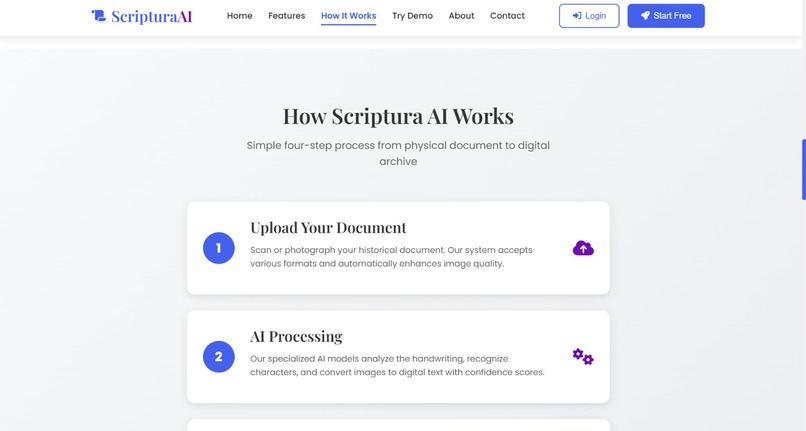
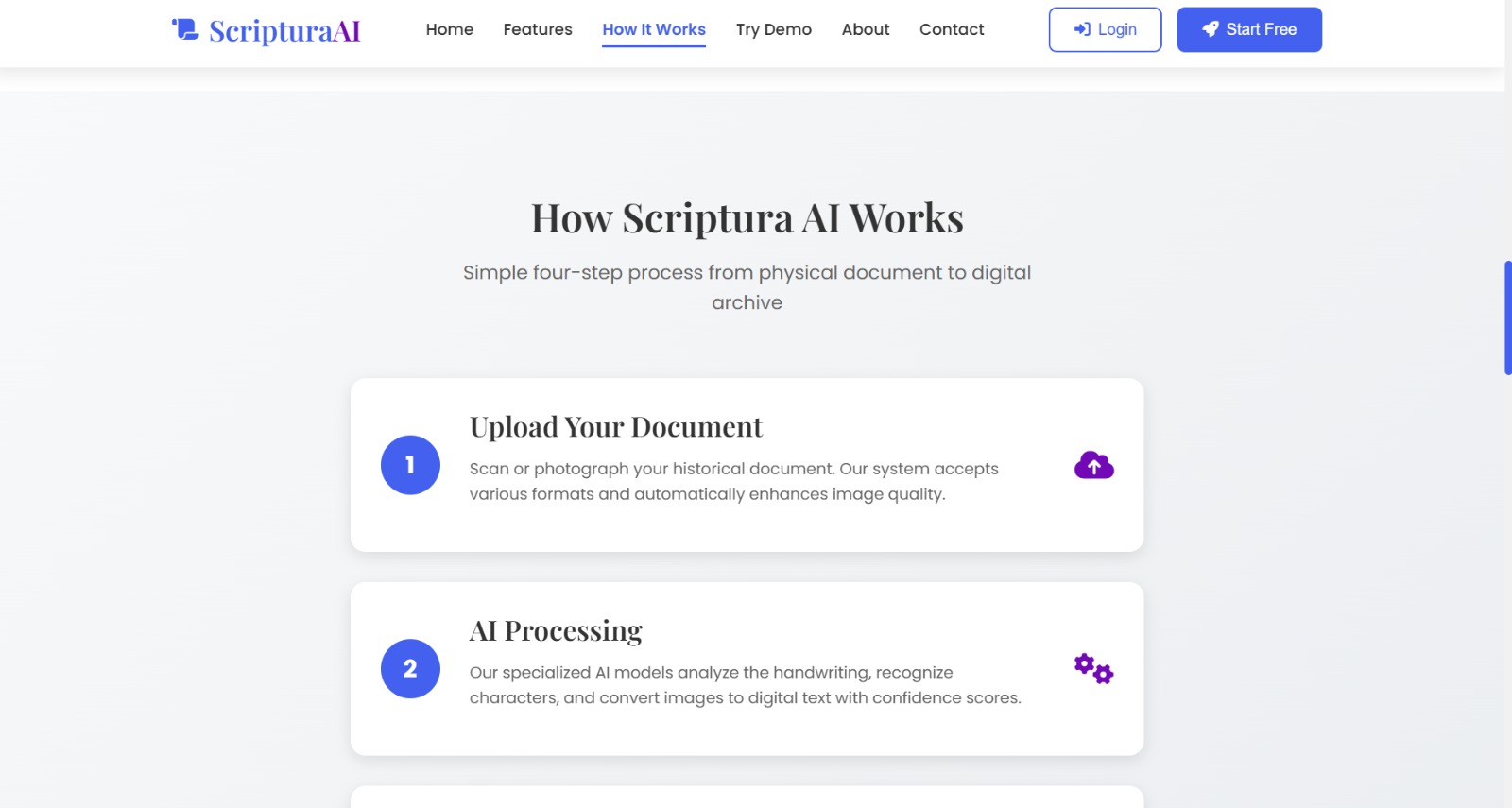
how it works
-
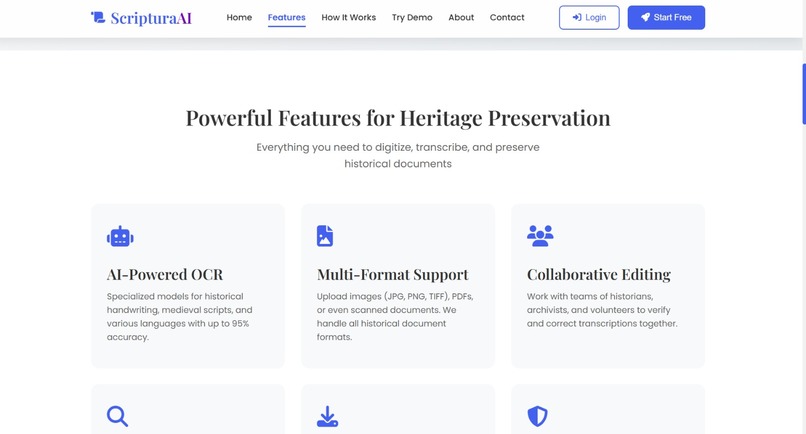
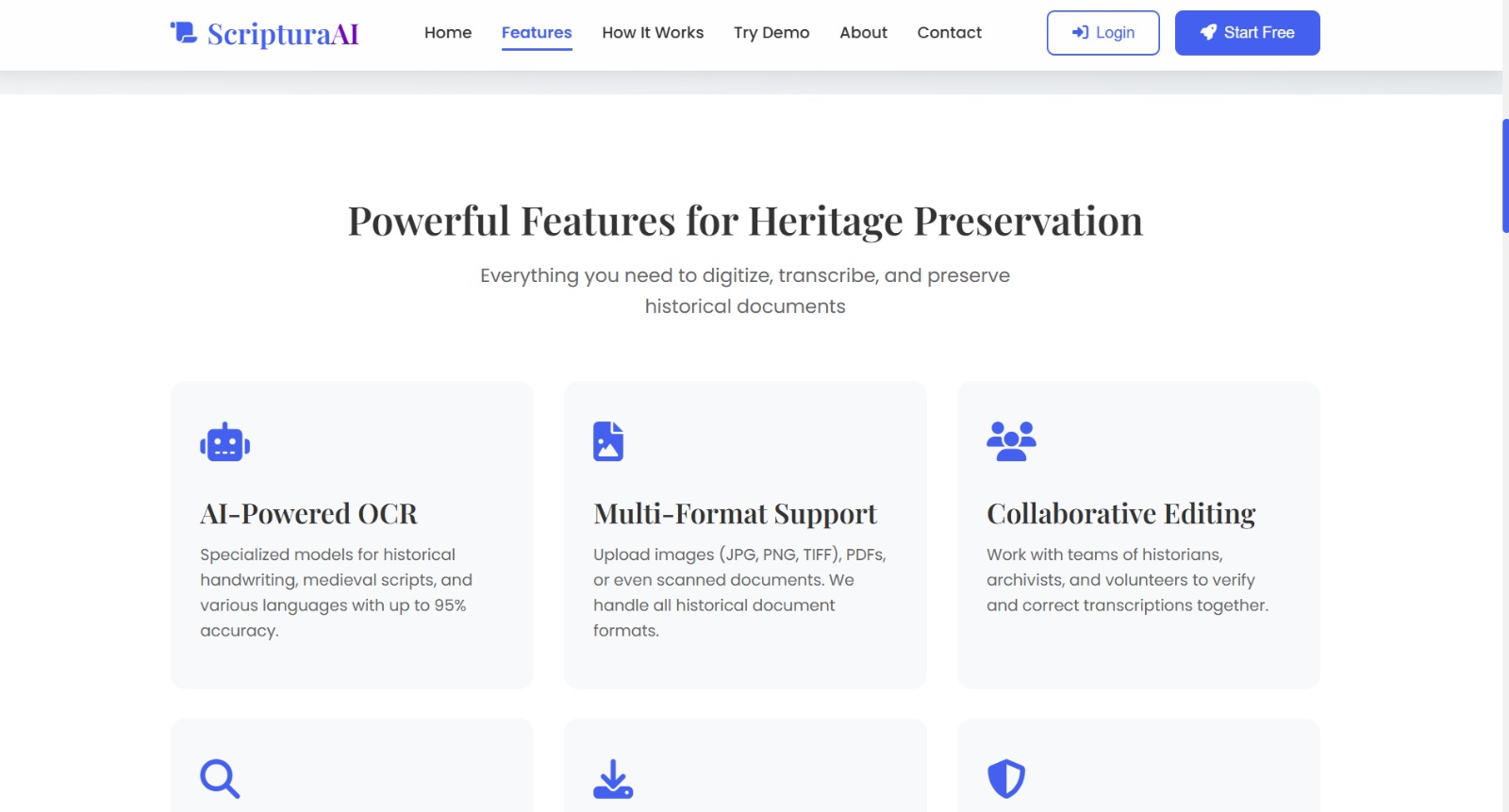
features of our project
-
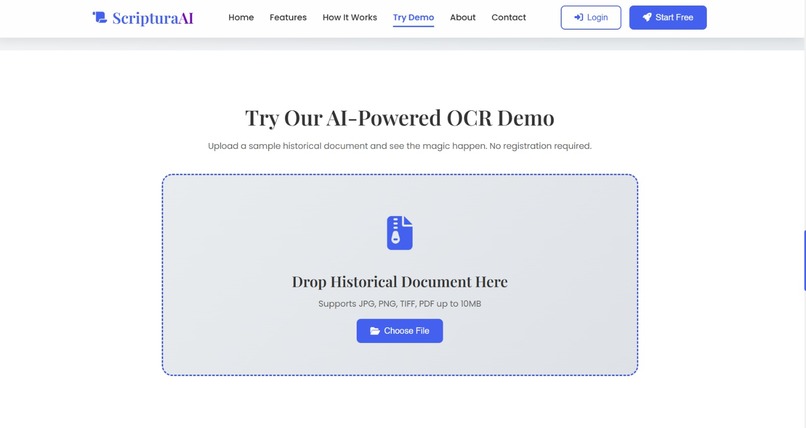
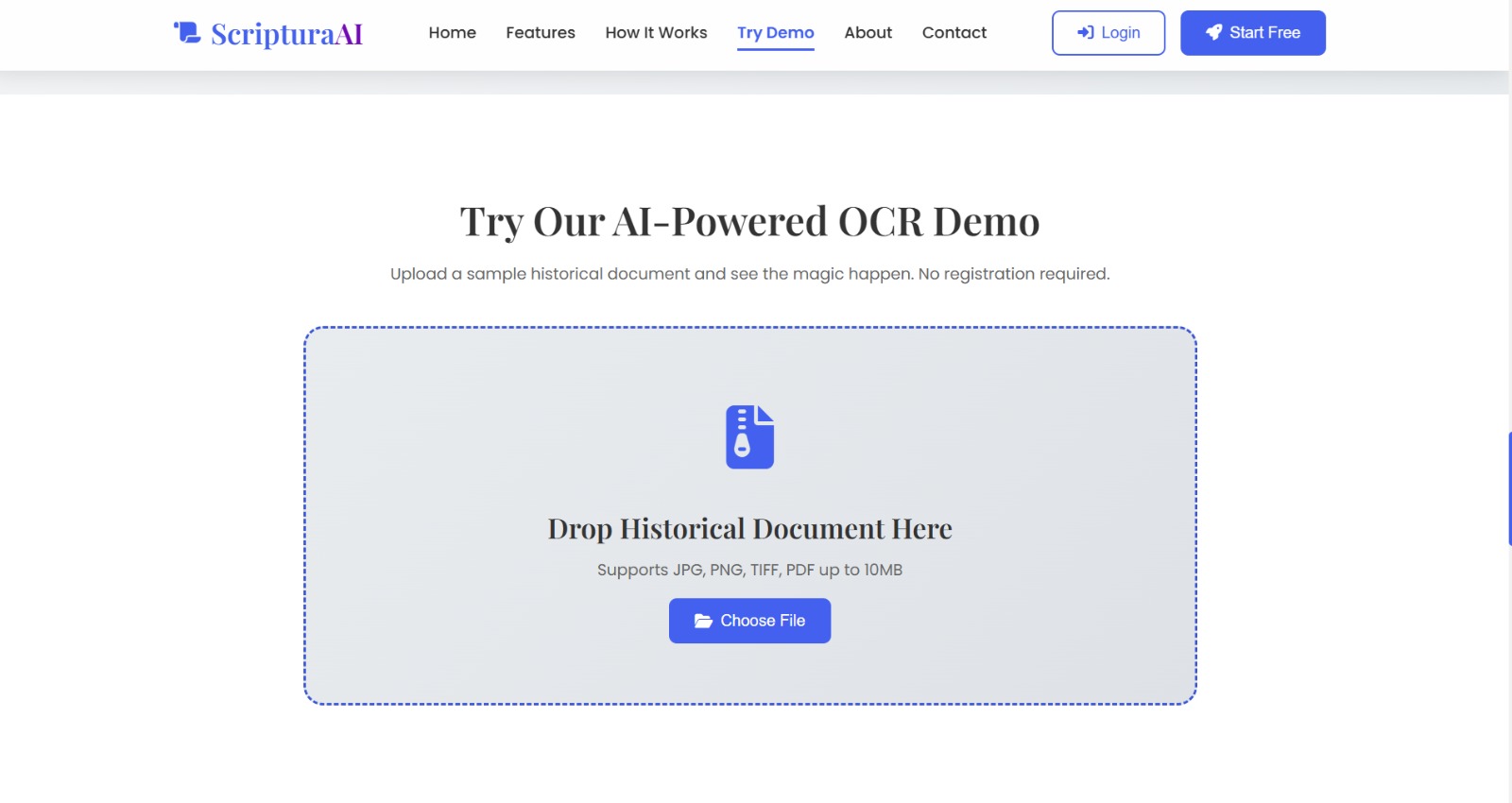
free demo part
Inspiration
India has a rich collection of historical handwritten manuscripts that are deteriorating and often inaccessible. We wanted to preserve this heritage by converting old handwriting into modern, digital text.
What it does
Heritage Text AI converts scanned images of handwritten documents into clean, searchable PDFs. It extracts text using AI-based OCR, formats it, and generates structured PDFs for easy storage, sharing, and research.
How we built it
We used Python and OpenCV for image preprocessing, Tesseract OCR / AI handwriting recognition for text extraction, Flask for the backend, and HTML/CSS/JavaScript for the frontend. Extracted text is processed into searchable PDFs.
Challenges we ran into
Handling faded ink, damaged pages, and varied handwriting styles was difficult. Improving OCR accuracy without losing characters required careful preprocessing and model tuning.
Accomplishments that we're proud of
We created a working system that digitizes handwritten historical documents into searchable PDFs, reducing manual transcription and preserving cultural knowledge.
What we learned
We gained experience in AI, OCR, image preprocessing, and document digitization, and learned how technology can help preserve historical knowledge.
What's next for Heritage Text AI
We plan to support more scripts and regional languages, add translation and text-to-speech, and integrate cloud storage for large-scale archival access, making historical documents widely available.
Built With
- ai-based-ocr-(tesseract)
- flask
- html/css/javascript
- machine-learning
- opencv
- pdf-generation-libraries
- python


Log in or sign up for Devpost to join the conversation.