


🐘 HerdSignal
Listening to what we couldn't hear before.
🧠 Inspiration
We built a system that transforms unusable elephant recordings into clean, analyzable signals—unlocking hidden communication for research and conservation.
In the wild, elephants are constantly communicating. But we rarely hear them. Not because they are silent— but because their voices are buried. Field recordings are filled with overlapping noise: engines, airplanes, generators. What should be communication becomes distortion. Over time, this creates a silent failure: We have the data. But we cannot use it. And if we cannot hear them clearly, we cannot understand them. If we cannot understand them, we cannot protect them.
🎯 What It Does
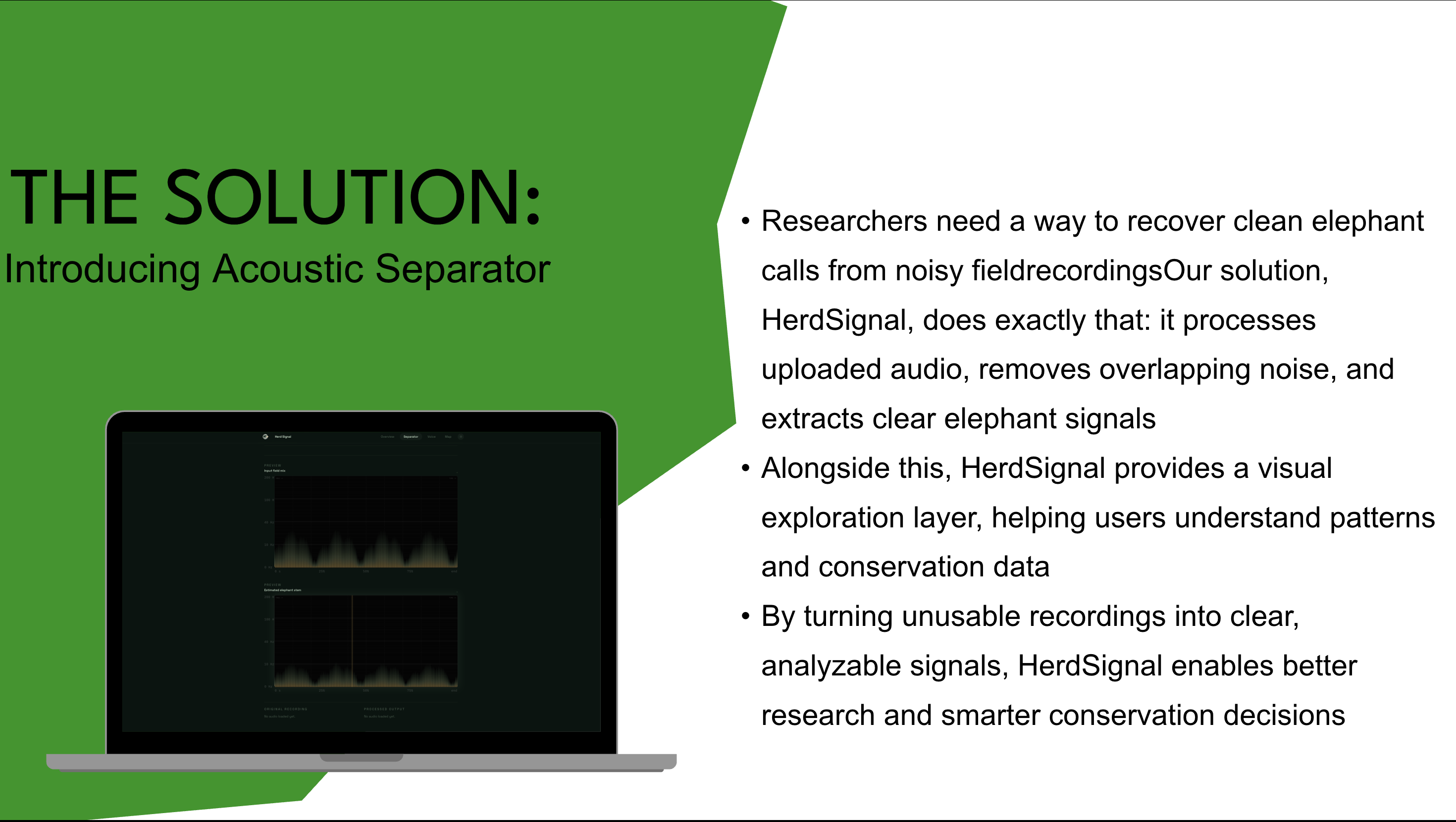
HerdSignal is a bioacoustic system that takes noisy elephant recordings and turns them into clean, usable signals.
Upload → Separate → Understand
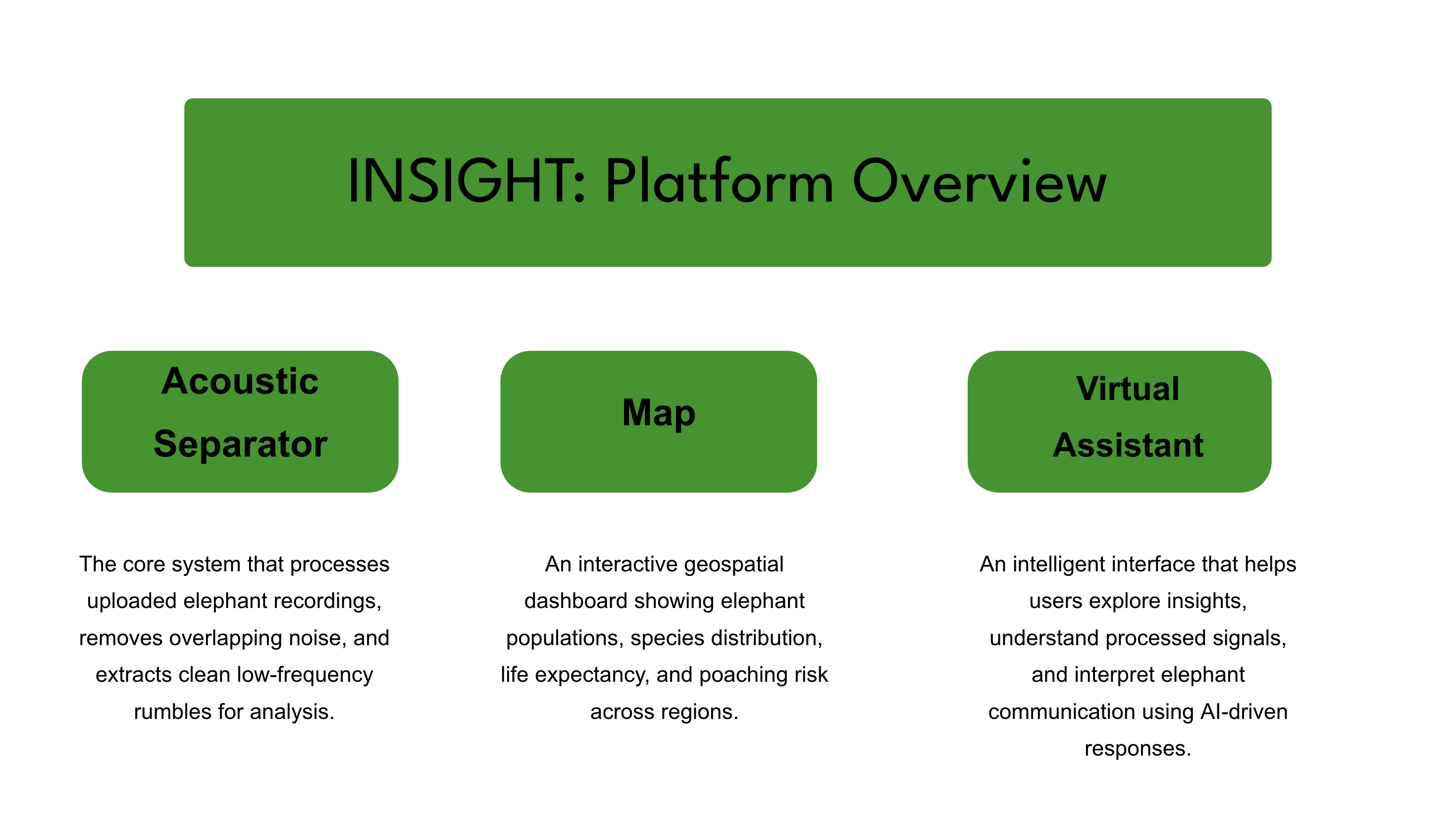
🎧 Acoustic Separation Engine Upload a noisy field recording Decompose the signal using Non-negative Matrix Factorization (NMF) Separate elephant calls from background noise Output a clean waveform + spectrogram At the core, we factor the spectrogram:
𝑉≈𝑊×𝐻
Where: V = original spectrogram W = spectral patterns (elephant vs noise) H = activation over time We classify components using frequency-band energy and reconstruct only the elephant signal. Spectrogram Intelligence Visualizes low-frequency rumbles (10–20 Hz) Identifies overlapping calls and harmonic structure Enables analysis of communication patterns
🗺️ Conservation Map A separate exploration layer that provides: Elephant population distribution Species and habitat regions Life expectancy trends Poaching and threat heatmaps This connects signal → context → understanding AI Assistant Explains separated signals Interprets conservation data Answers questions about elephant behavior
🧩 How We Built It
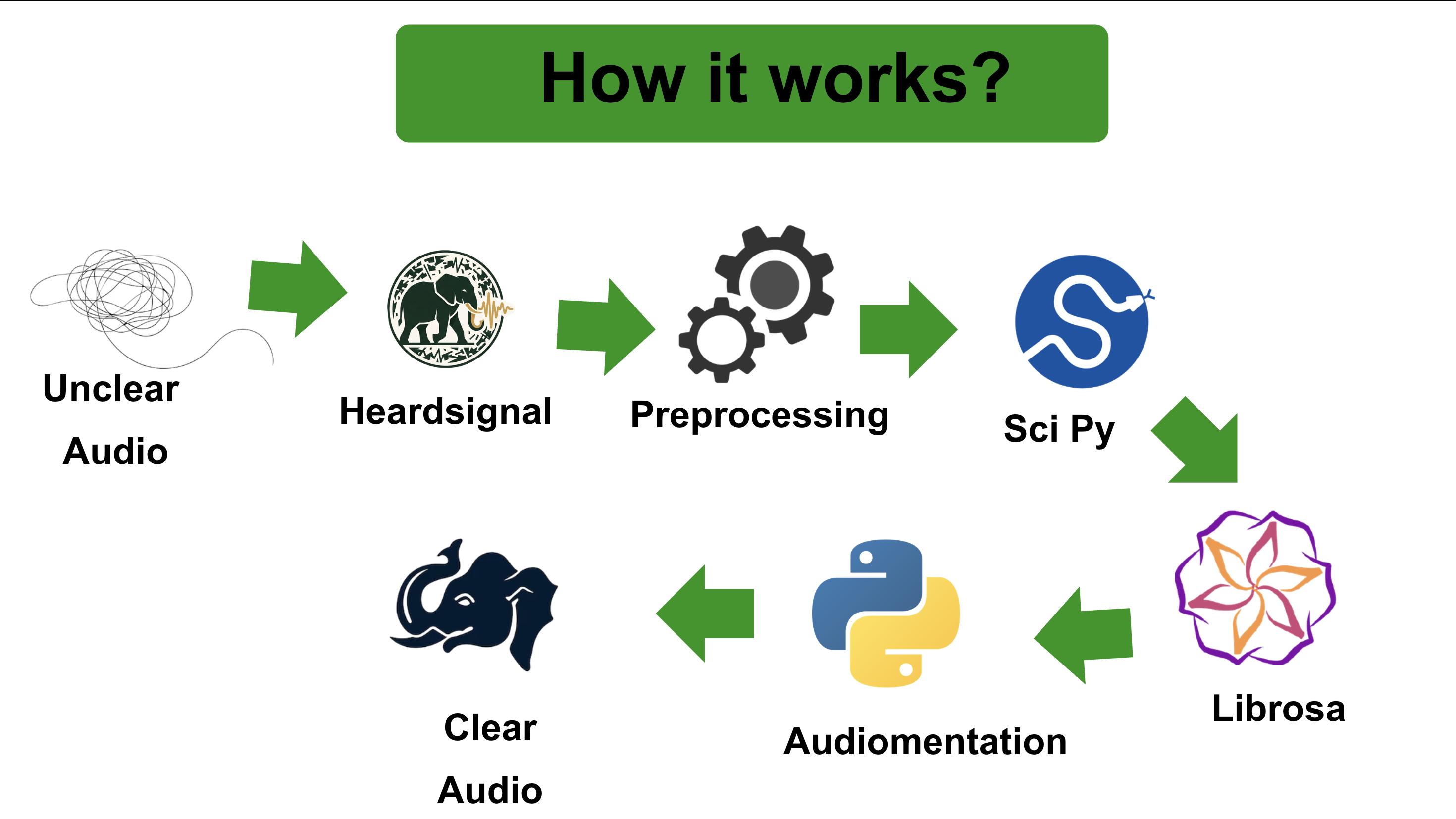
🔁 System Pipeline Recording → Spectrogram → NMF Separation → Reconstruction → Visualization
Backend (Audio/API):Built with Python and FastAPI (served with Uvicorn). The separation pipeline leans on NumPy, SciPy, and librosa for spectrograms and audio I/O, with non-negative matrix factorization (NMF) and related processing to pull elephant calls out of noisy recordings; PyTorch / torchaudio, Demucs, and Asteroid appear in the stack for heavier separation and evaluation tooling.
Frontend:: A Next.js (React) app styled with Tailwind CSS. Maplibre power the interactive map; Recharts drives dashboard charts; React Three Fiber and Three.js (with @react-three/drei) back the 3D audio visualizer. The voice agent uses the Web Speech API (STT/TTS) with a Next.js Route Handler calling Groq for replies; Zustand, TanStack Query, and tRPC support client state and typed APIs where wired in.
Database: We used Supabase (PostgreSQL) loaded with the PostGIS extension. By using spatial indexing (GiST), the frontend can rapidly query regions and cluster threat incidents.
🧠 Challenges
Low-Frequency Overlap Elephant rumbles exist in the same frequency range as mechanical noise—making separation extremely difficult without losing signal integrity.
Signal Preservation Balancing noise removal while maintaining harmonic structure required multi-stage processing: preprocessing separation postprocessing
🎉 Accomplishments
Built a full audio separation pipeline in under 24 hours Processed 200+ recordings with high-quality signal recovery Achieved ~0.72 match score with near-zero noise contamination Created an end-to-end system from raw audio → usable insight
Impact
Unlocks thousands of unusable elephant recordings Enables deeper study of elephant communication and cognition Supports conservation and anti-poaching strategies Bridges the gap between data collection and real understanding
🔮 What’s Next
Improve multi-elephant call separation Expand dataset across ecosystems Integrate real-time field recording pipelines Deploy for conservation organizations
🧾 Final Thought
We are not lacking data. We are lacking clarity. HerdSignal doesn’t just clean audio. It restores communication. And in doing so, it gives elephants something they’ve always had— but we’ve never fully heard: a voice.
Built With
- demucs
- fastapi
- groq
- librosa
- maplibre
- next.js
- numpy
- postgis
- postgresql
- python
- scipy
- tailwind
- torchaudio
- uvicorn




Log in or sign up for Devpost to join the conversation.