-
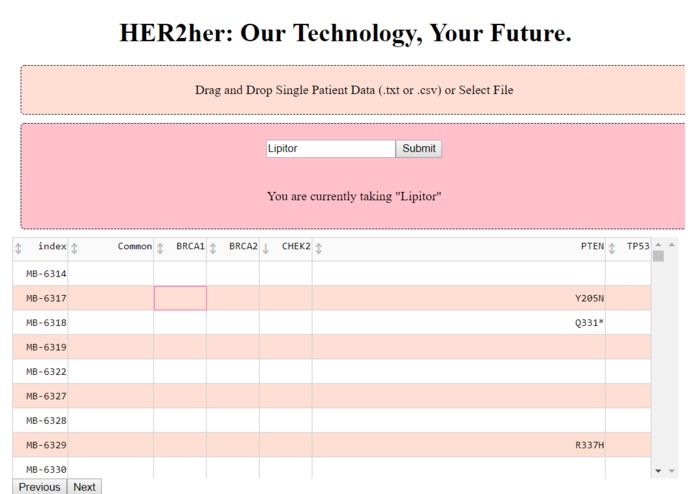
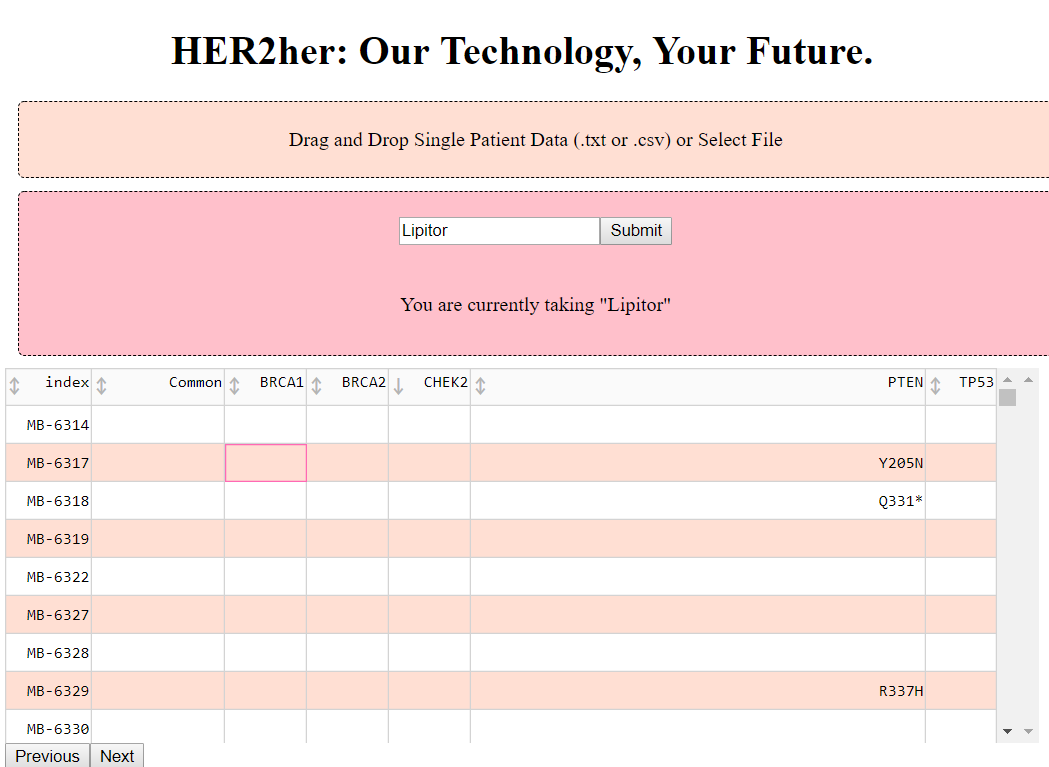
Top half of our portal where patients will input their information. As patients add their medications, the sentence underneath populates
-
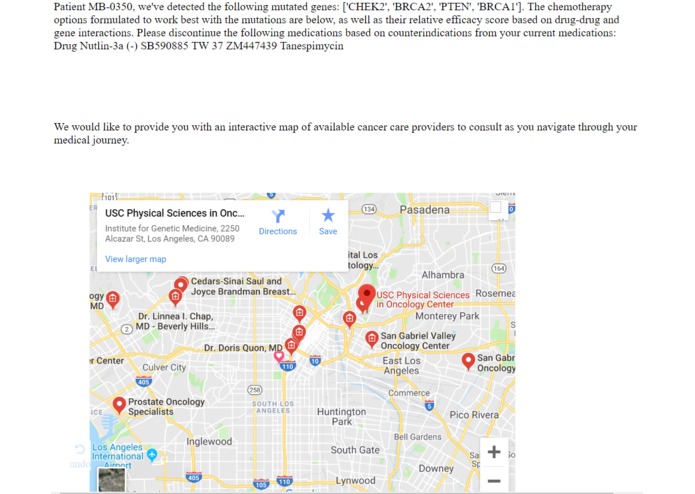
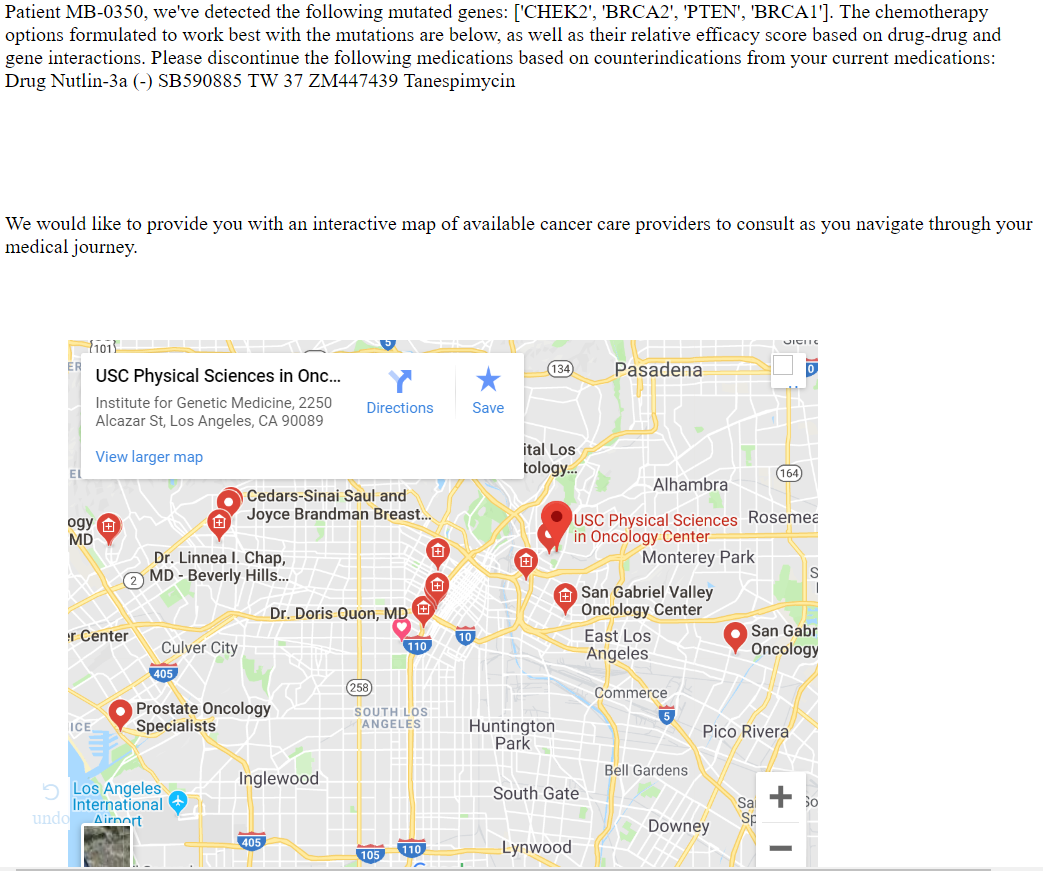
After the magic happens, the results show which medicines match well with the patient's profile and health.
Inspiration
In the United States, more than one in nine women are likely to be diagnosed with Breast Cancer at some point in their lives. According to the National Assessment of Adult Literacy, " nearly nine out of ten adults may lack the skills needed to manage their health and prevent disease". On a global scale, many people feel helpless when it comes to making decisions regarding their own health. We aim to bring confidence and direction to the fingertips of the Breast Cancer community.
Uploading Data
Launch the web version of HER2Her. Upload either a csv of the patient’s sequences for the five specified genes (BRCA1, BRCA2, TP53, PTEN, and CHEK2). Or, upload csv file with 2 columns: one with the gene name, and the other with “1” for mutated and “0” for normal.
Clinical Data
All drug efficacy data is given by (https://www.cancerrxgene.org/), who collected, verified, and published cancer drug sensitivity data from dozens of clinical trials and academic research projects. We tested our application with patient data collected from (https://www.cbioportal.org/datasets), specifically the May 2016 Nature paper(https://www.ncbi.nlm.nih.gov/pubmed/27161491). Mutated and normal genes were retrieved via API get request to Ensembl.
What it does
With increased integration of healthcare and technology, patients and researchers look forward to the implementation of personalized healthcare. Her2her aims to bring predictive medicine to the hands of women suffering from Breast Cancer. Named after one of the most common biological factors present in Breast Cancer, Her2, our platform allows patients (or clinicians) to upload genomic information (sequence data or mutation list). Data science gives the unique opportunity to visualize the rapid growth in patient information.
Currently, patients will input their status (mutated or normal) of 5 of the most commonly mutated oncogenes. Alternatively, a patient can upload raw genetic data from their doctor or DNA test. The 5 oncogenes, when mutated, lead to changes in how the body metabolizes and interacts with medicines. Our platform then uses clinical data from Massachusetts General Hospital, the Wellcome Sanger Institute (UK), and the Center for Molecular Therapeutics to determine breast cancer drugs, and make a recommendation based on clinical efficacy data.
To personalize the platform further, the user will input any current medications they are using. Our platform will access DrugBank to ensure our potential medicine don't interact with current patient therapies. This assures the patient won't have hypersensitivity caused by drug-drug interactions.
Lastly, our platform provides the closest oncology centers around the patient in order to provide some possible next steps. We don't want our women to feel alone, and suggesting Cancer Doctors on our site would allow patients to feel more in touch with their health. By personalizing medical choices, our platform empowers Breast Cancer patients to become more knowledgeable about their health.
How we built it
We utilized Python & the Flask-Dash microframeworks to develop a dashboard hosted locally on our system. Built on top of React, Plotly.js, and Flask, Dash provided a full-stack development environment. We began by identifying mutated and normal DNA sequences for 5 genes that are most commonly found to be mutated when breast cancer is clinically indicated via a API function to the Ensembl genomic database. Then, we generated randomized sample data that used a weighted random sequence selector to produce more than 1000 phenotypes with varying frequencies of mutated sequences. By utilizing Pandas, we created a dataframe that consolidated our data and flagged any genes that were found to be mutated; this was visualized on the Flask dashboard as a paginated, clearly formatted data table.
We also developed a function for clinicians to upload data from their patients-- text & CSV files were parsed & any abnormal sequences that are suspicious for breast cancer were automatically flagged.
A drop down menu was also developed in Flask to introduce further directions for HER2her-- in the future, it would be prudent to compare current therapies between the different genetic breast cancer profiles.
We also included a text-based diagnostic summary for the user. This includes a personalized title based on the profile of the patient, as well as the specific gene mutations that were detected in their profile. We also included a dynamic search-based Google Maps API using an iframe object within the Flask framework. We automatically highlighted oncologists within Southern California to best fit the needs of our users.
We have considered 5 mutations for the current scope of the problem. Average effectiveness for a particular drug (a drug may be suggested with different effectiveness by different centres based on their patient history) on a mutation was computed. As a patient can have multiple mutations at the same time and we would want the cumulative effect of a drug due to these mutations, we computed the cumulative effect of all the drugs suggested for a patient.
Take a patient with mutation M and N. Given previous data, drugs A, B, and C have previously been prescribed to patients with mutation M. Similarly, N-mutated patients have previously used drugs B, D, E. We then would compute the cumulation of the effectiveness scores for the patient's particular genetic makeup: A (from Mutation M) , B (cumulation of the effectiveness for mutation M and Mutation N), C (from Mutation M), D (from Mutation N), E (from Mutation N).
From the resultant drug data, we selected the top 20 most effective drugs based on efficacy scores. The patient then provides us with the current list of the drugs that they are already taking.
By webscraping the URLlib and XML.etree of the drug interaction effects, we generated an XML with the necessary information. This was then used to compute the lists of drugs which might react with the current drug intake of patient. Those drugs were then removed from the top 20 drugs, and only the top 5 which won’t react with the current patient intake were suggested.
Challenges we ran into
We faced challenges in data accessibility due to patient confidentiality reasons. The most reputable healthcare & research facilities around the world are HIPAA compliant, which means that patients reserve the right to keep their medical information confidential. This is absolutely understandable, but it did require creative sequence discovery & mutation analysis within the Ensembl genetic database. Furthermore, we wanted our platform to meet unmet medical needs within the community, while remaining accessible for patients of all backgrounds. As such, we had some difficulty determining the scope of the project within the confines of 24 hours!
Accomplishments that we're proud of
While many research centers are beginning to look into ML and personalized medicine, our platform provides a much more patient-centric, and comprehensive perspective into individualized medicine. Large clinics like MayoClinic only offer one gene, one drug tests, which only test a patient's genetic makeup for response to a single drug. We decided to look at all the drugs that interact with more than one genetic marker in our patient. This allows for a more personalized result. If we can improve the quality of life for even one patient, we are proud of what we've accomplished (and we do test it on 60 patient samples!)
What we learned
It is hard to find a good dataset that does what you'd like. Many of us come from biology backgrounds, and we had a plethora of ideas for the different biological markers we wanted to look at. We scoured the interwebs for stress response, drug response, categorical markers, patient gene expression, EEGs, their favorite foods, but we couldn't quite find a dataset that would allow us to fulfill our desires. We strongly believe that as data science grows as a field, so will the drive to produce comprehensive and well-reputable datasets.
What's next for HER2her
We will further look to expand our platform to consider all genetic mutations as well as make it all inclusive to other types of cancer patients. We also will predict possible drug responses or hypersensitivities, such as allergic reactions. This way, we would need to utilize patient history that can be disclosed by the patient themselves. Drug therapy is not the only treatment available to the Breast Cancer patients. Further improvements on our platform will consider recommending hormonal, biological, and radiation treatments.
Built With
- dash
- ensembl
- flask
- google-cloud
- google-maps
- html5
- pandas
- python
- restful-api
- the-cancer-genome-atlas
- urllib
- xml.etree





Log in or sign up for Devpost to join the conversation.