-
the login page
-
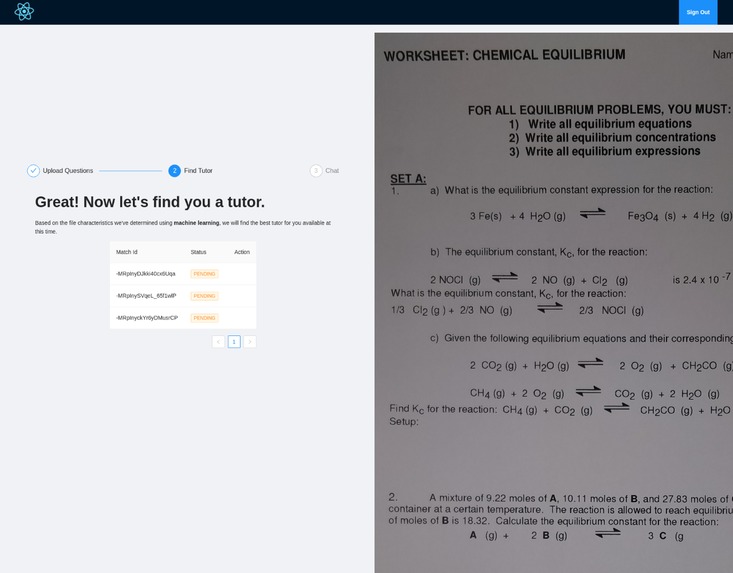
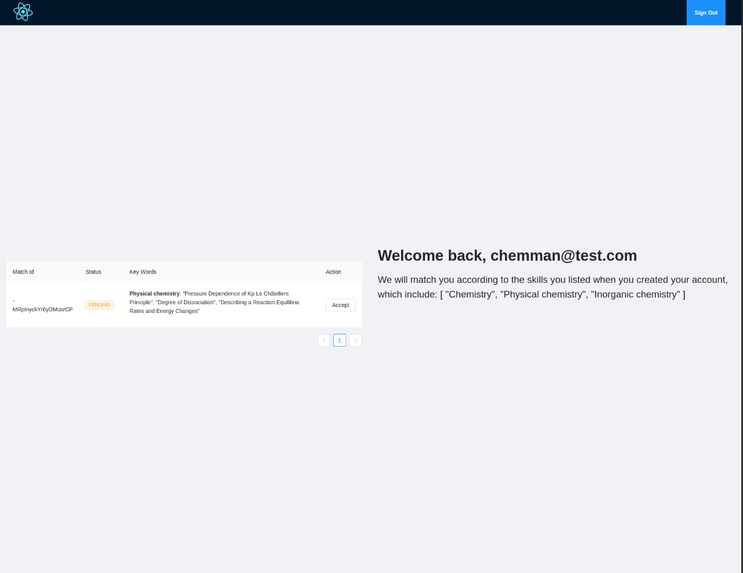
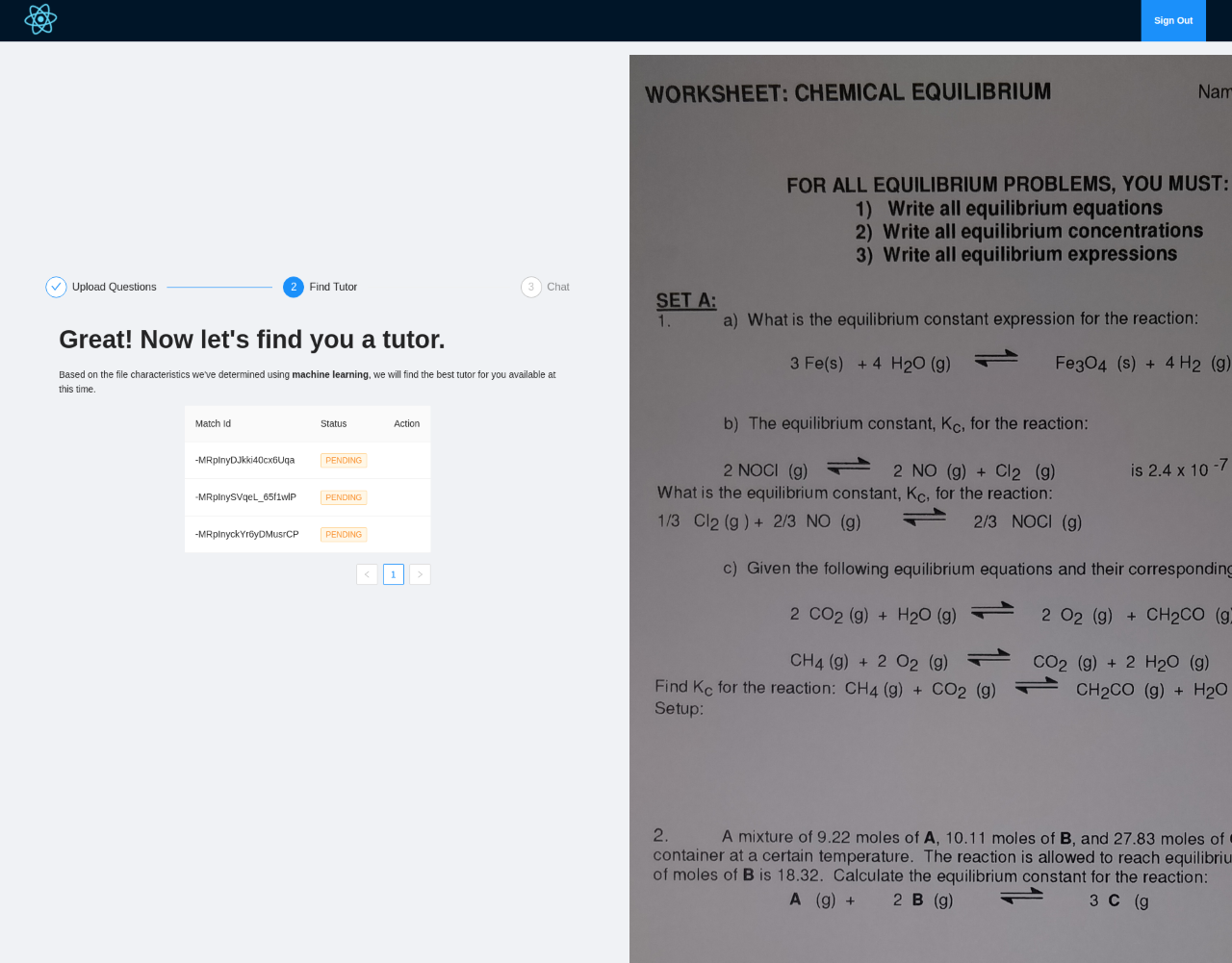
match with your tutor
-
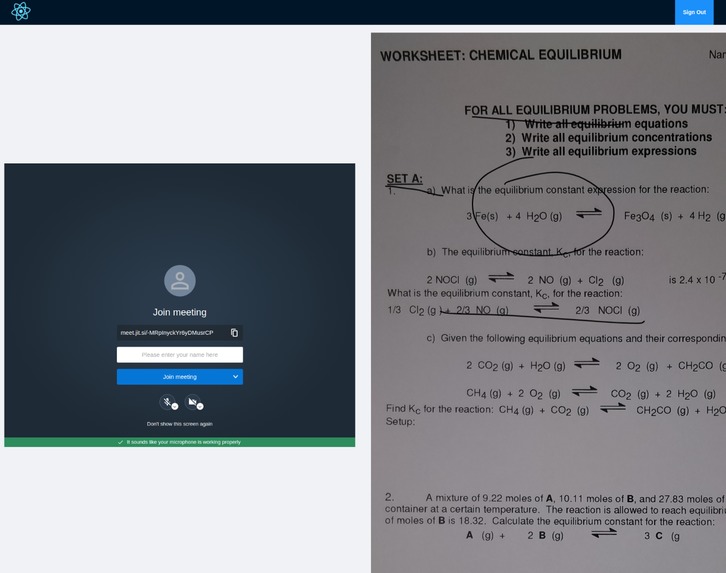
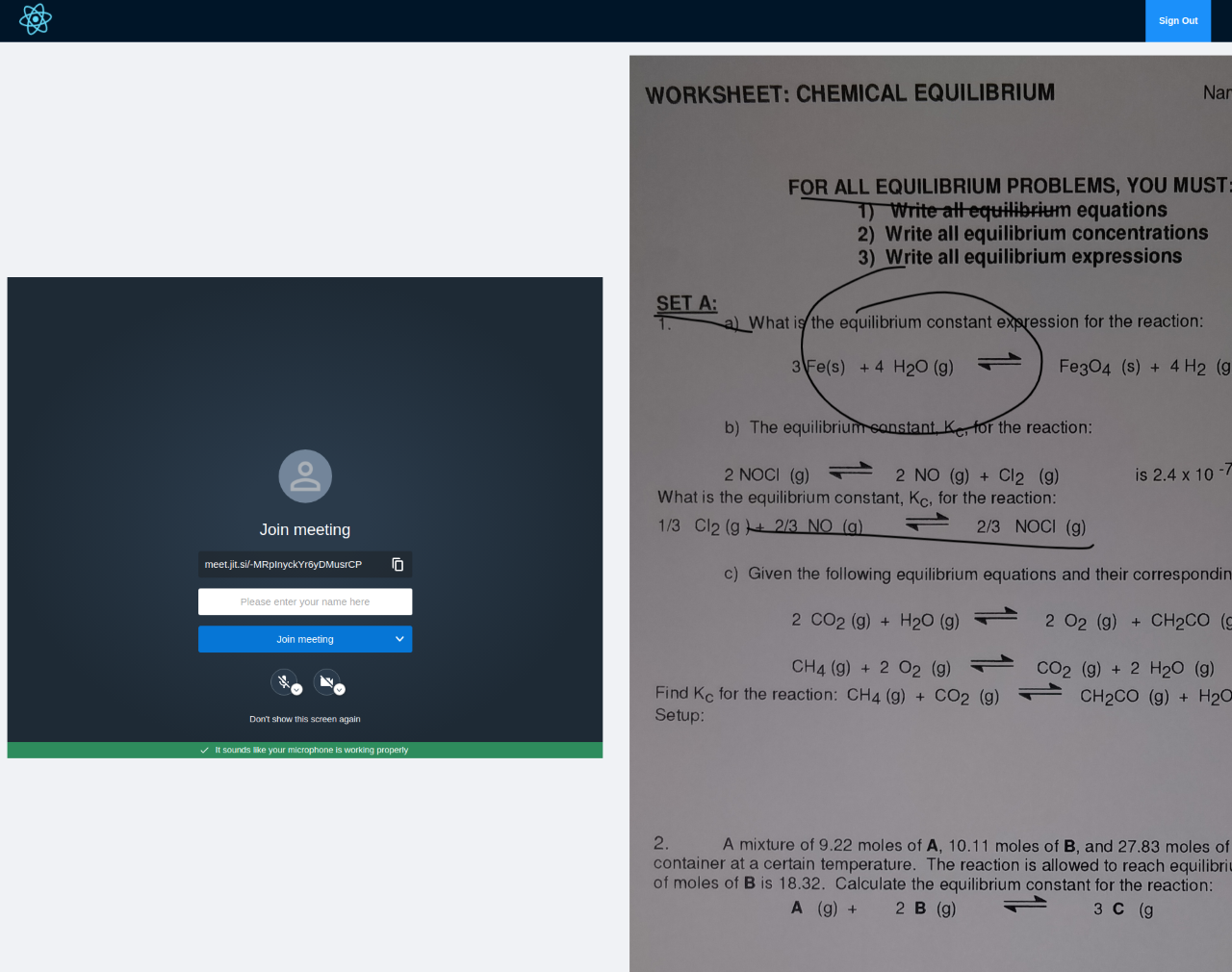
video calling with pdf on side
Inspiration
The detrimental effect of national lockdowns on education has highlighted the incredible value of face-to-face learning. As postgraduates at Cambridge, many of us are involved in tutoring secondary school pupils as well as undergraduates, and our experience has taught us that real-time human interaction can have an unparalleled impact on students’ understanding - even remotely via video conferencing software. However, many parents of school children who would benefit most from online tutoring are simply not in the position to pay the often extortionate fees, and many talented potential tutors are unable to dedicate a regular time slot. We have decided to create a platform to connect keen volunteer tutors like us with those pupils in need of one-to-one support, as and when the need presents itself.
What it does
Pupils can upload pictures of their homework, a page from a textbook or a screenshot. Our system uses machine learning to extract the data from the picture, decide on the subject and field, and find topic key words. At the same time, tutors experienced in the same field will receive a notification including the key words. Even within the broad field (e.g. chemistry) there may be topics a given tutor does not feel comfortable teaching, so this step allows them to accept or reject requests based on more than just the name of the subject. Once the tutor decides to accept the notification, they will be connected to a video chat with the pupil. For greater safety, the pupils do not have to sign up or include any personal details, as opposed to the mentors.
How we built it
We built the website using React, with a Firebase database for storing user data. For video conferencing we use an embedded Jitsi Meet Call, and for OCR we used the Textract Python library. Data was generated by harvesting freely available Libretext course pages and textbooks, and used to train an ANN for text classification. TF-IDF vectorization is used to collect key words, further narrowing down the topic for the benefit of the tutor.
Challenges we ran into
Using a few sentences or paragraphs of a homework question to determine the subject, branch and even a specific topic was challenging in multiple ways. We need reliable clean labelled data, which we obtained by harvesting online textbooks by individual sections. To quickly and reliably categorise the contents of the uploaded images, we had to use a combination of techniques: ANN to narrow down the subject and its branch, and similarity comparison using TF-IDF vectorization to generate key words.
Accomplishments that we're proud of
While this idea came to us only after the hackathon has already started, we managed to create a working example for a service that could greatly help disadvantaged students, especially in the time of national lockdowns.
What we learned
Most of us had little-to-no experience of building websites before this weekend, so we have learned a great deal over these 36 hours! We learned about different methods for text classification and the challenges involved in implementing them, especially when only a rather limited dataset is available.
What's next for Help-me-now!
We would like to train our text classification model on a much larger dataset for greater flexibility and reliability. We would also like to implement more sophisticated account management and create a mobile app for tutors, that they could integrate with their calendars to be notified of relevant student requests at times when they are available.




Log in or sign up for Devpost to join the conversation.