-
-
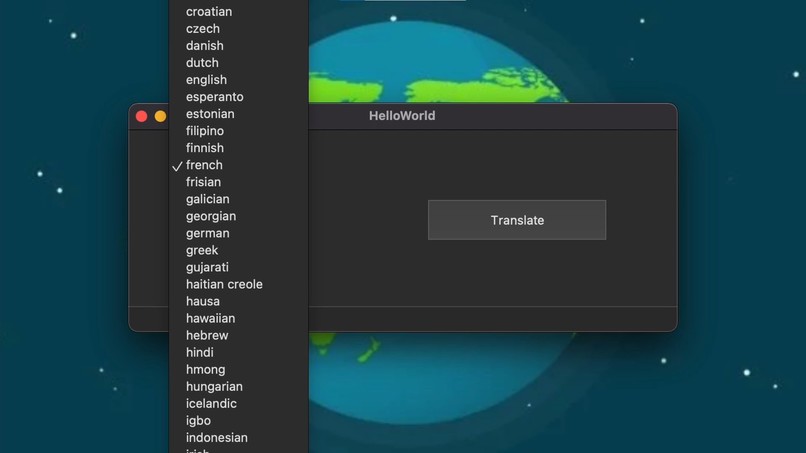
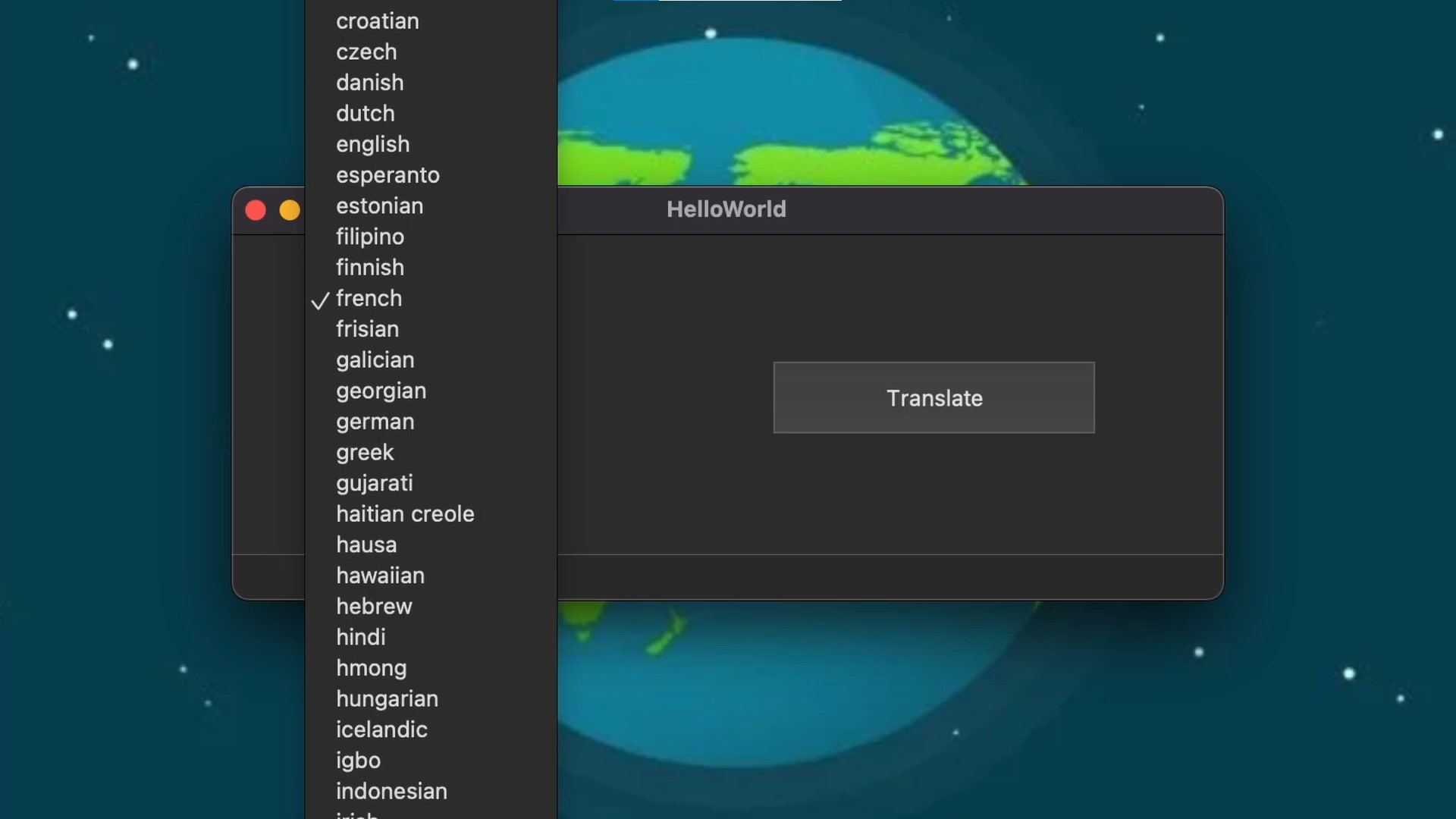
Input and translation language selection
-
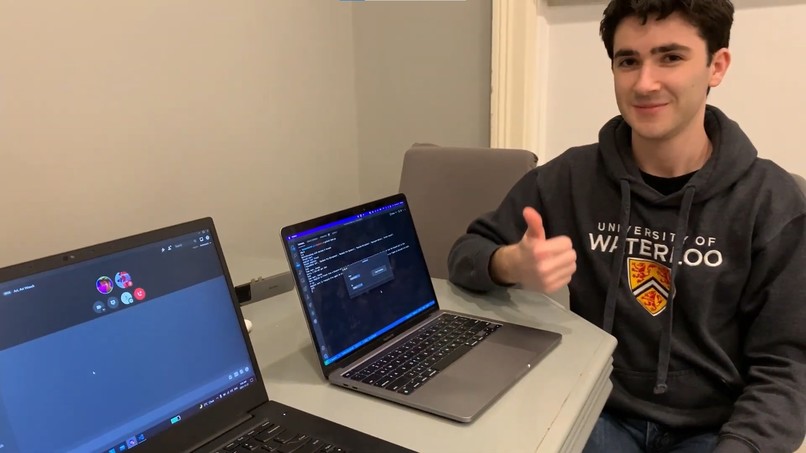
Virtual translation (output through Discord)
-

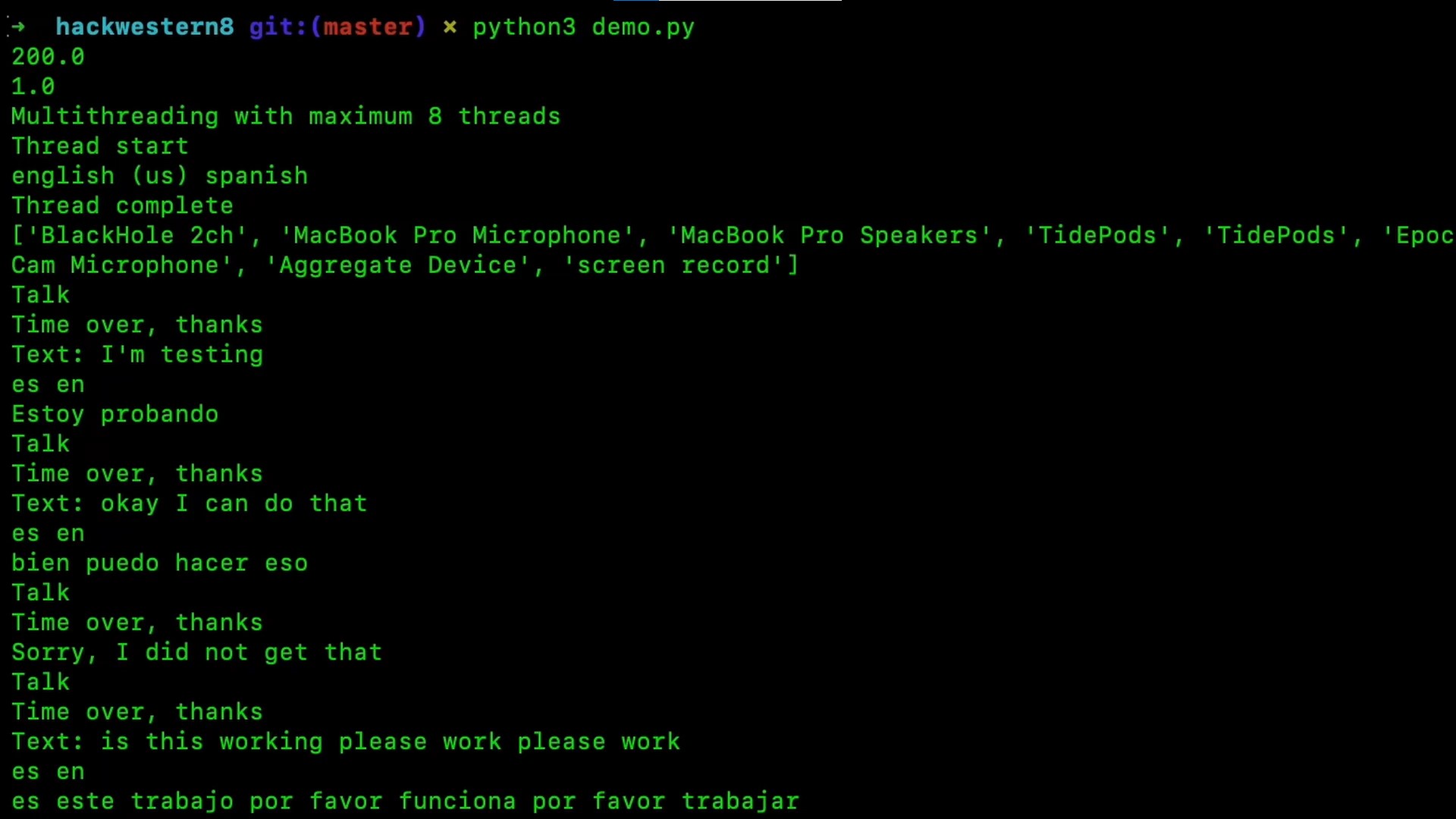
Terminal output of running program
-
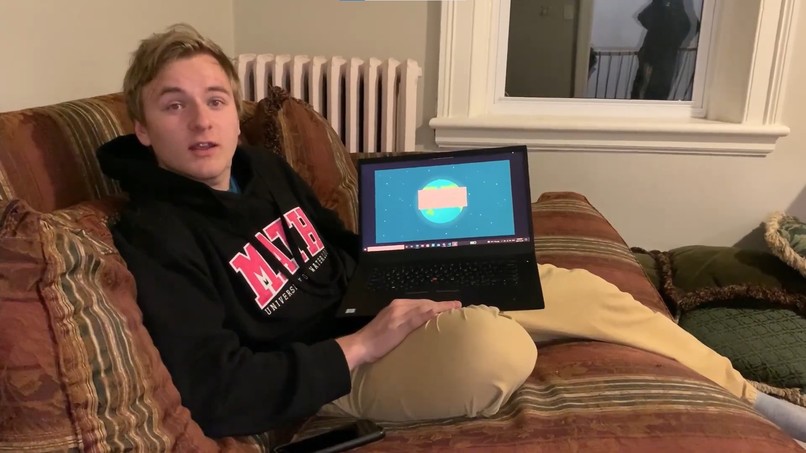
In-person translation (output to speaker)
-


Inspiration
Although there are limitless technologies that connect people from around the world, language barriers still stand as an unbreakable wall blocking communication between people who speak different languages. We want to eliminate language barriers so that everyone can talk with anyone. We saw a gap in real-time translation apps and thus decided to create HelloWorld, a program to translate languages in real-time in-person and on the Internet.
What it does
HelloWorld is a real-time translator that allows users to communicate in the languages of their choice. HelloWorld allows quick, real-time, easy user-to-user communication in 50+ languages.
HelloWorld translates your language into another language with two optional outputs: speaker output for in-person communication or microphone output for virtual communication.
To translate into another language, HelloWorld receives the user’s microphone input and outputs the translated sentence into a speaker, headset, video call, or other audio output.
How we built it
We were able to smoothly transition from inputted speech to translated speech in four steps: we first convert the recorded speech to text, translate that text, then convert the text to speech. Finally, we output the translated audio to the appropriate output stream. We handle all of these transitions with a multithreaded PyQt frontend, utilizing a virtual audio cable.
The initial speech-to-text process uses the speech_recognition Python library. The key to this part of the program is making sure that the input stream the program is listening to is not the actual system input stream -- this is because we must avoid overlapping our translated output and the original inputted speech. Our solution to this problem is outlined below. We record the audio input phrase-by-phrase to ensure that the text reads naturally.
After converting the speech input to text, we translate the text using the googletrans library which communicates with the Google Translate API. The Google Translate API supports translation between a vast array of languages, which is optimal for our implementation as we want as broad a user base as possible, working toward our goal of maximizing interlanguage communication around the globe.
The final process of text-to-speech was accomplished with the gTTS Google text-to-speech function, using the Python library pyttsx3. To play the translated speech back to the user, we sent the translated speech out to the default audio output. If we need to send the translated speech to an application, we send it to a virtual output device.
Challenges we ran into
One of the initial obstacles we encountered was the need for the application to interact with two separate input streams. One input stream is used to capture the user's voice, and another input stream is utilized for pipelining the translated audio into the target application. We achieved this by using both a physical input (microphone) and a virtual input (software emulated input). Another challenge we encountered was the utilization of multithreading to create a smooth real-time experience, as the application uses several threads to run the front end, listen to the user's speech, translate it, and send the translated speech into the virtual stream.
Accomplishments that we're proud of
We are proud that we could create a finished product and expand on our idea more than what we had originally planned. We are happy with how the translation turned out given our challenges. Additionally, we feel like this has a real world application that millions of people world-wide could benefit from. Overall, we are most proud of what we learned!
What we learned
We learned two major things while building this project. Firstly, we learned how to use multithreading in Python. Secondly, we learned about interfacing various audio input/output devices on Mac/Windows devices to make everything runs smoothly. This was our team's first project in this sphere, so it was a great learning experience for all of us, as we picked up vast new knowledge and skills regarding how apps like ours are implemented.
What's next for HelloWorld
The first thing to improve in HelloWorld is the latency: the time between speaking and the translator outputting the translated audio. It currently takes a few seconds, making for a slightly awkward turnaround period without speech. To make the app more natural and seamless, the first thing to do is cut down this interval. Second, we’d like to improve the consistency of the translation, optimizing its accuracy. Finally, we would like to make HelloWorld deliverable on more devices (e.g., mobile) to widen the pool of potential users and make the app more accessible. Implementing HelloWorld as a web app could also make strides in this direction.
Built With
- googletrans
- os
- playsound
- pyqt5
- python
- pyttsx3
- speech-recognition
- threading





Log in or sign up for Devpost to join the conversation.