-
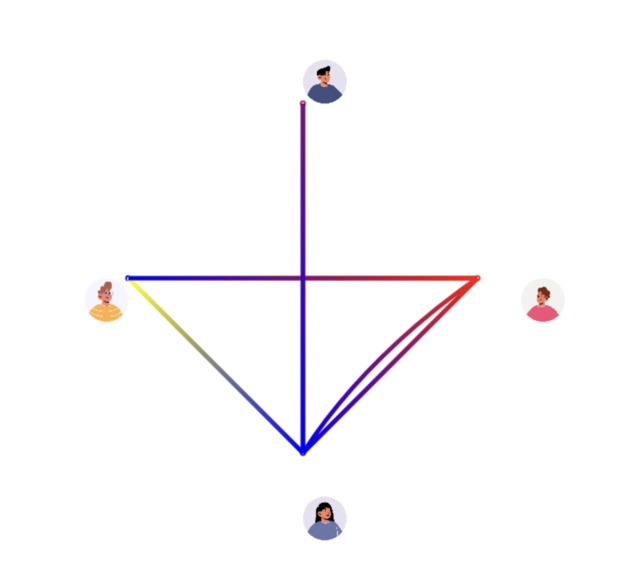
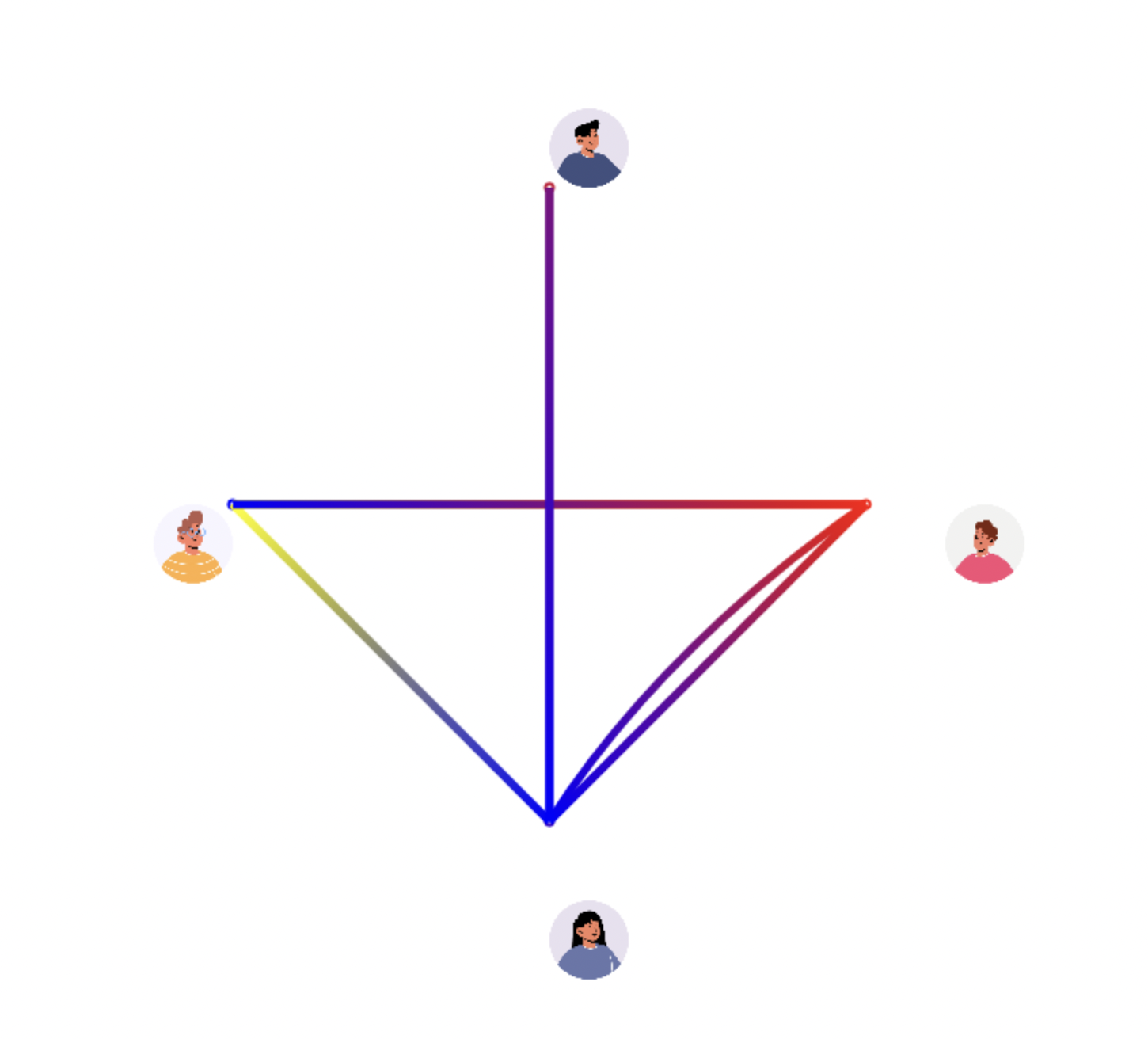
App interface
-
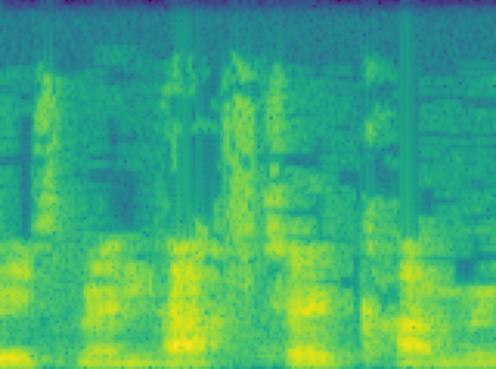
Spectrogram of one of our members' voice
-
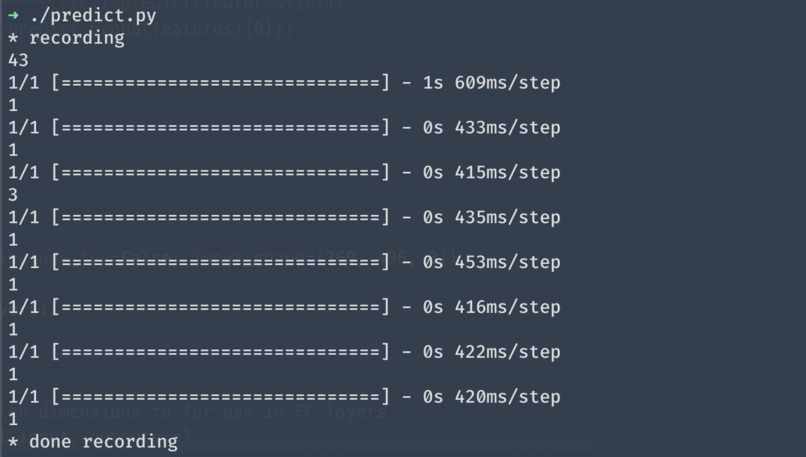
Process of predicting voice using our model
Inspiration
In high school, a teacher of ours used to sit in the middle of the discussion to draw lines from one person to another on paper to identify the trends of the discussion. It's a very meaningful activity as we could see how balanced the discussion is, allowing us to highlight to people who had less chance to express their ideas. It could also be used by teacher in earlier education, to identify social challenges such as anxiety, speech disorder in children.
What it does
The app initially is trained on a short audio from each of the member of the discussion. Using transfer learning, it will able to recognize the person talking. And, during discussion, very colorful and aesthetic lines will began drawing from person to another on REAL-TIME!
How we built it
On the front-end, we used react and JavaScript to create a responsive and aesthetic website. Vanilla css (and a little bit of math, a.k.a, Bézier curve) to create beautiful animated lines, connecting different profiles. On the back-end, python and tensorflow was used to train the AI model. First, the audios are pre-processed into smaller 1-second chunks of audio, before turning them into a spectrogram picture. With this, we performed transfer learning with VGG16, to extract features from the spectrograms. Then, the features are used to fit a SVM model, using scikit-learn. Subsequently, the back-end opens a web-socket with the front-end to receive stream of data, and return label of the person talking. This is also done with multi-threading to ensure all the data is being processed quickly.
Challenges we ran into
As it's our first time with deep-learning or training an AI for that matter, it was very difficult to get started. Despite the copious amount of resources and projects done, it was hard to identify a suitable source. Different processing techniques were also needed to know, before the model could be trained. In additions, finding a platform (such as Google Colab) was also necessary to train the model in appropriate time. Finally, it was fairly hard to incorporate the project with the rest of the project. It needs to be able to process the data in real-time, while keeping the latency low.
Another major challenge that we ran into was connecting the back-end with the front-end. As we wanted it to be real-time, we had to be able to stream the raw data to the back-end. But, there were problems reconstructing the binary files into appropriate format, because we were unsure what format RecordRTC uses to record audio. There was also a problem of how much data or how frequent the data should be sent over due to our high latency of predicting (~500ms). It's a problem that we couldn't figure out in time
Accomplishments that we're proud of
The process of training the model was really cool!!! We could never think of training a voice recognition model similar to how you would to to an image/face recognition. It was a very out-of-the-box method, that we stumbled up online. It really motivated us to get out there and see what else. We were also fairly surprised to get a proof-of-concept real-time processing with local audio input from microphone. We had to utilize threading to avoid overflowing the audio input buffer. And if you get to use threading, you know it's a cool project :D.
What we learned
Looking back, the project was quite ambitious. BUT!! That's how we learned. We learned so much about training machine learning as well as different connection protocols over the internet. Threading was also a "wet" dream of ours, so it was really fun experimenting with the concept in python.
What's next for Hello world
The app would be much better on mobile. So, there are plans to port the entire project to mobile (maybe learning React Native?). We're also planning on retrain the voice recognition model with different methods, and improve the accuracy as well as confidence level. Lastly, we're planning on deploying the app and sending it back to our high school teacher, who was the inspiration for this project, as well as teachers around the world for their classrooms.
Sources
These two sources helped us tremendously in building the model:
https://medium.com/@omkarade9578/speaker-recognition-using-transfer-learning-82e4f248ef09
https://towardsdatascience.com/automatic-speaker-recognition-using-transfer-learning-6fab63e34e74
Built With
- fastapi
- javscript
- multithread
- python
- react
- recordrtc
- scikit-learn
- tensorflow
- websockets





Log in or sign up for Devpost to join the conversation.