-
-
Landing Page
-
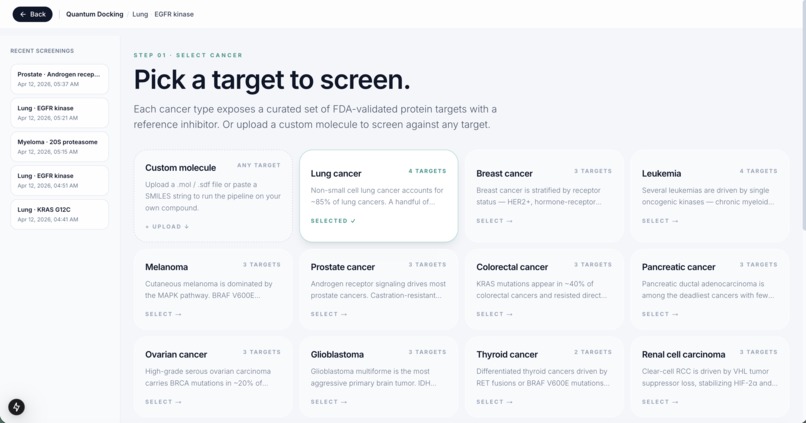
Quantum Docking
-
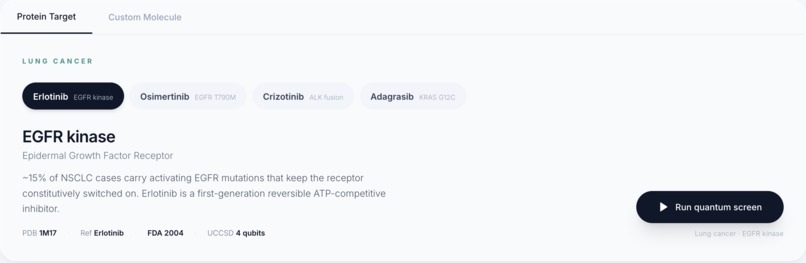
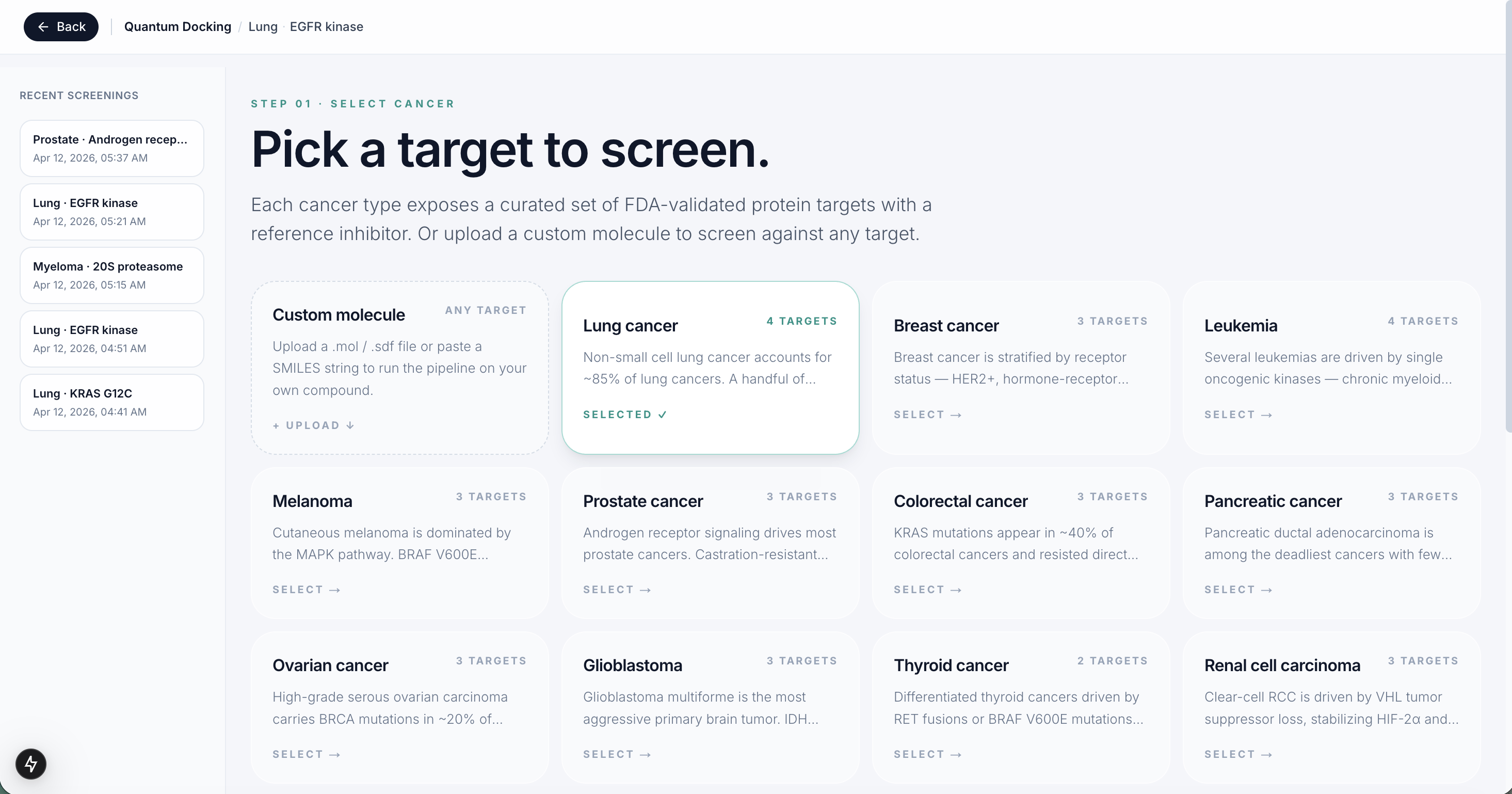
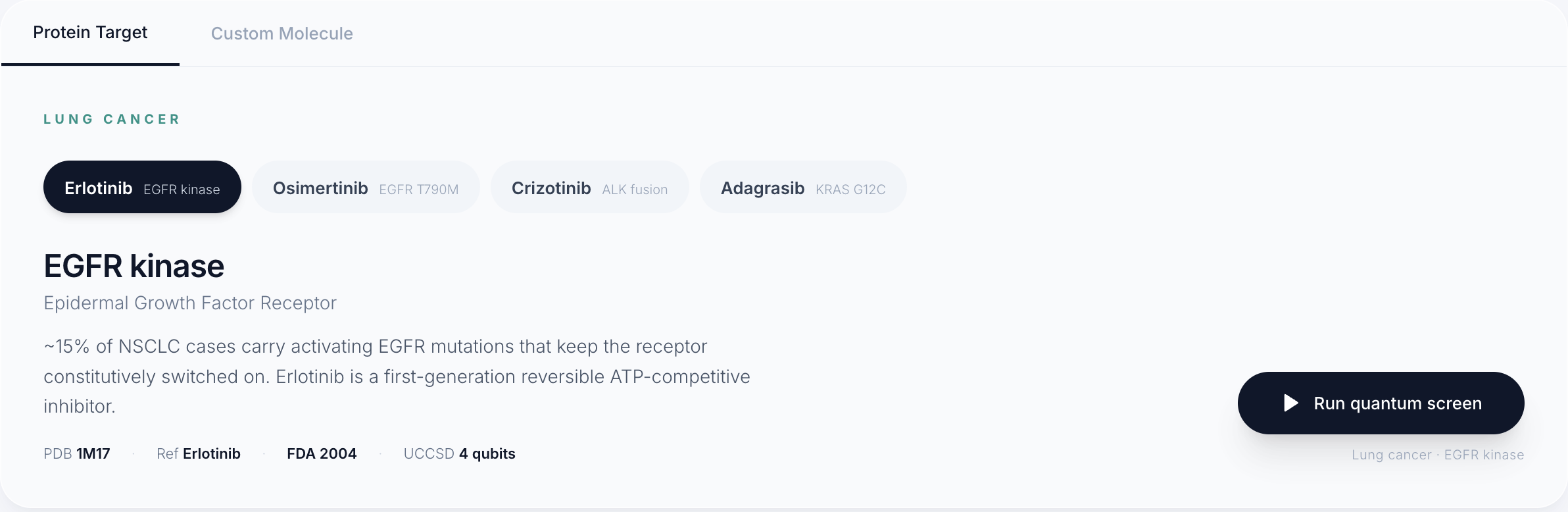
Target Protein Selector
-
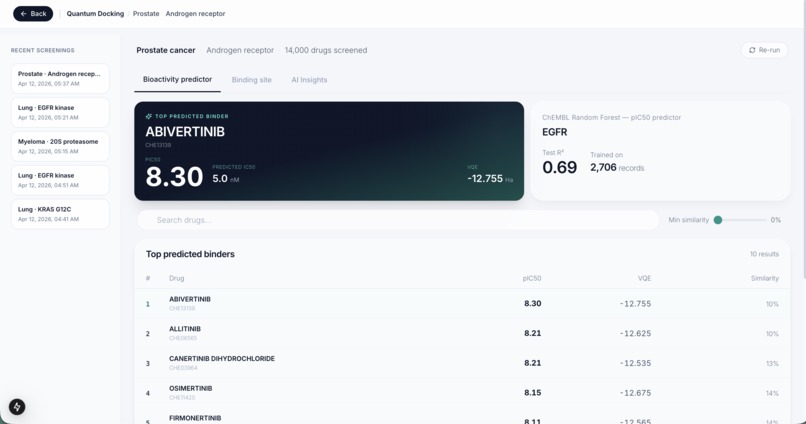
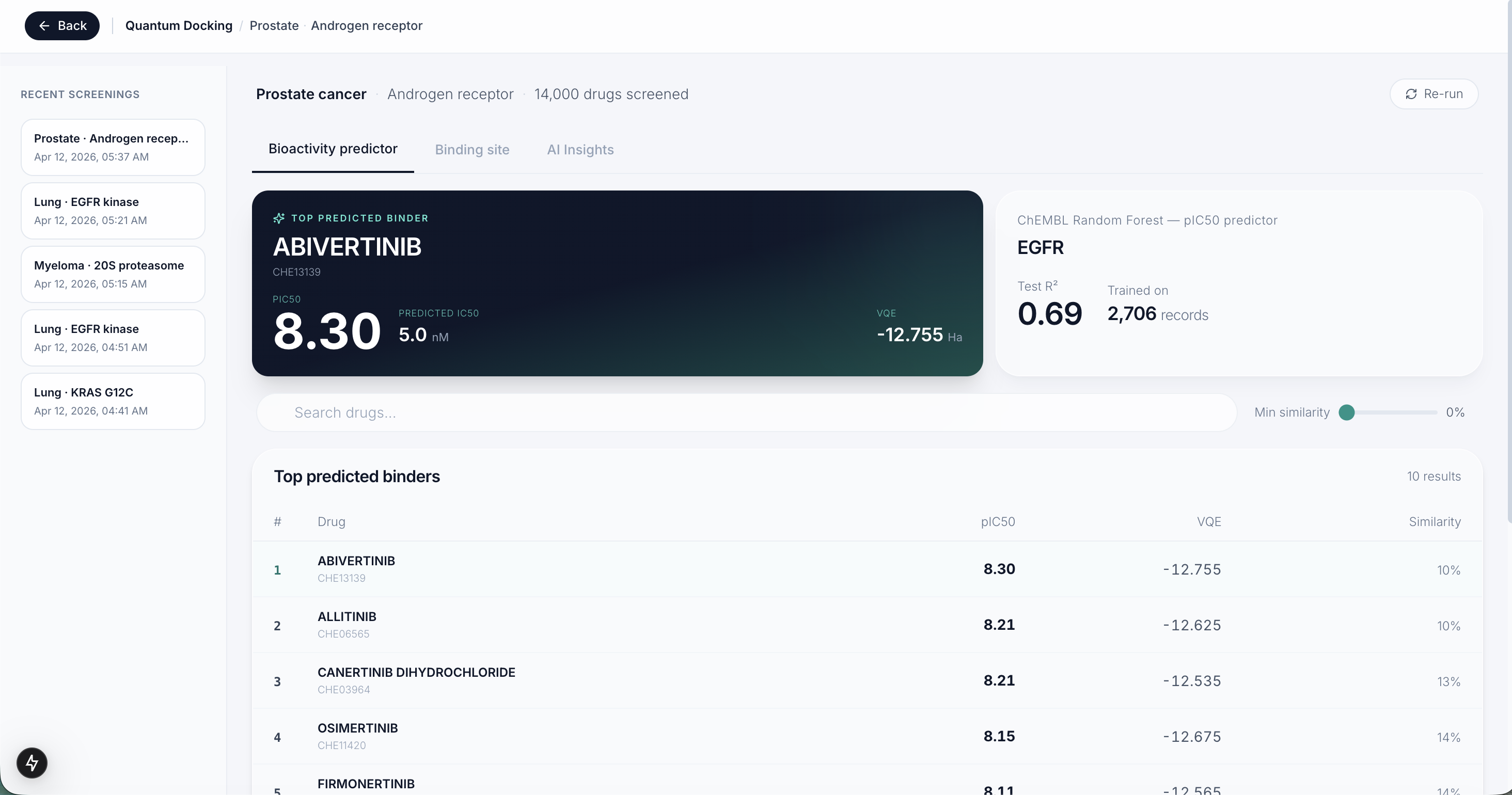
Quantum Docking Report
-
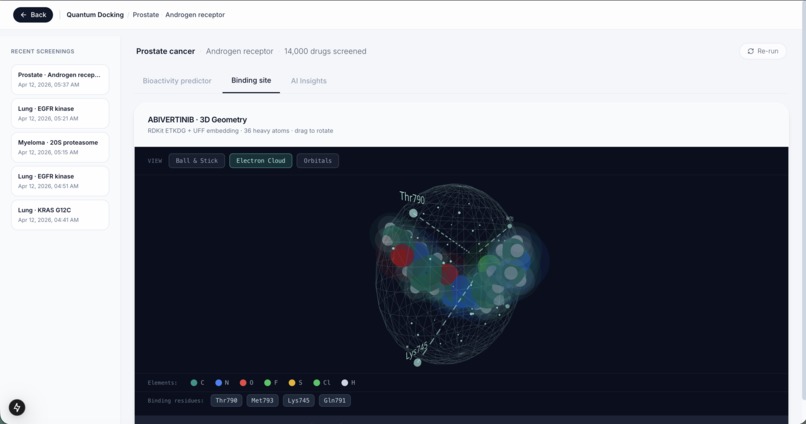
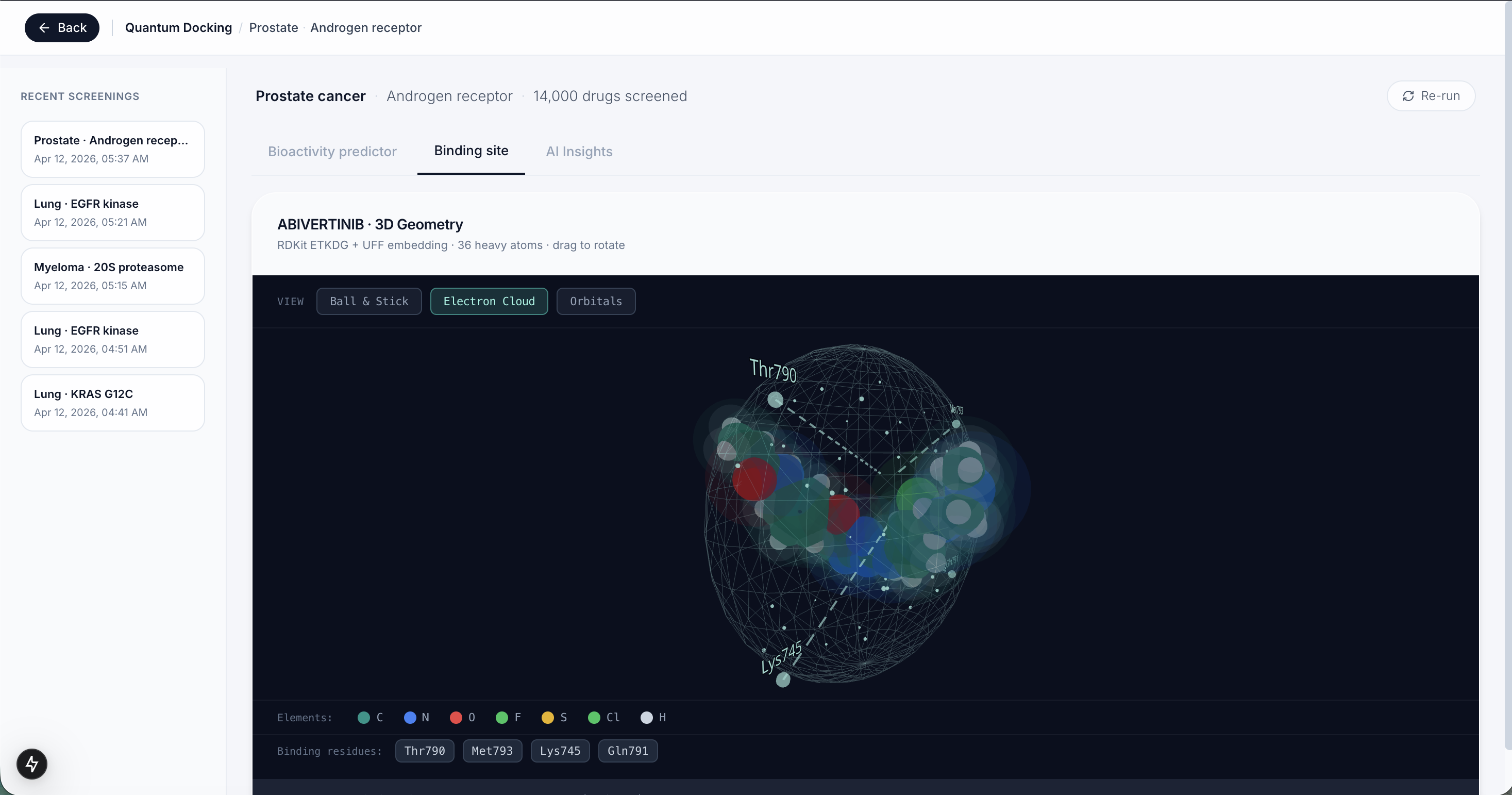
Compound Visualization
-
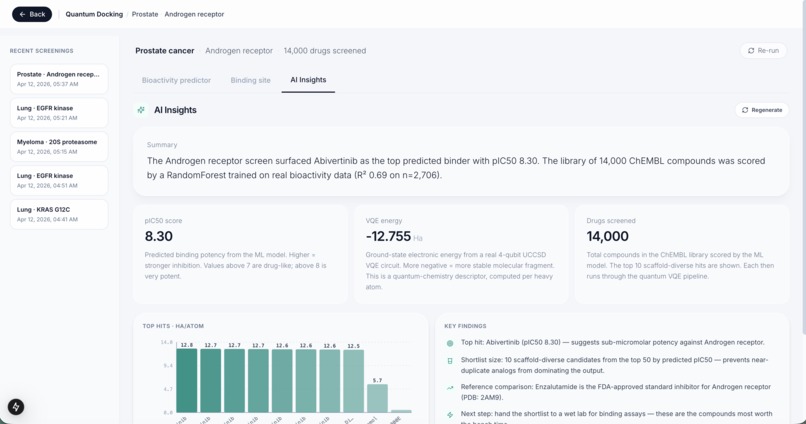
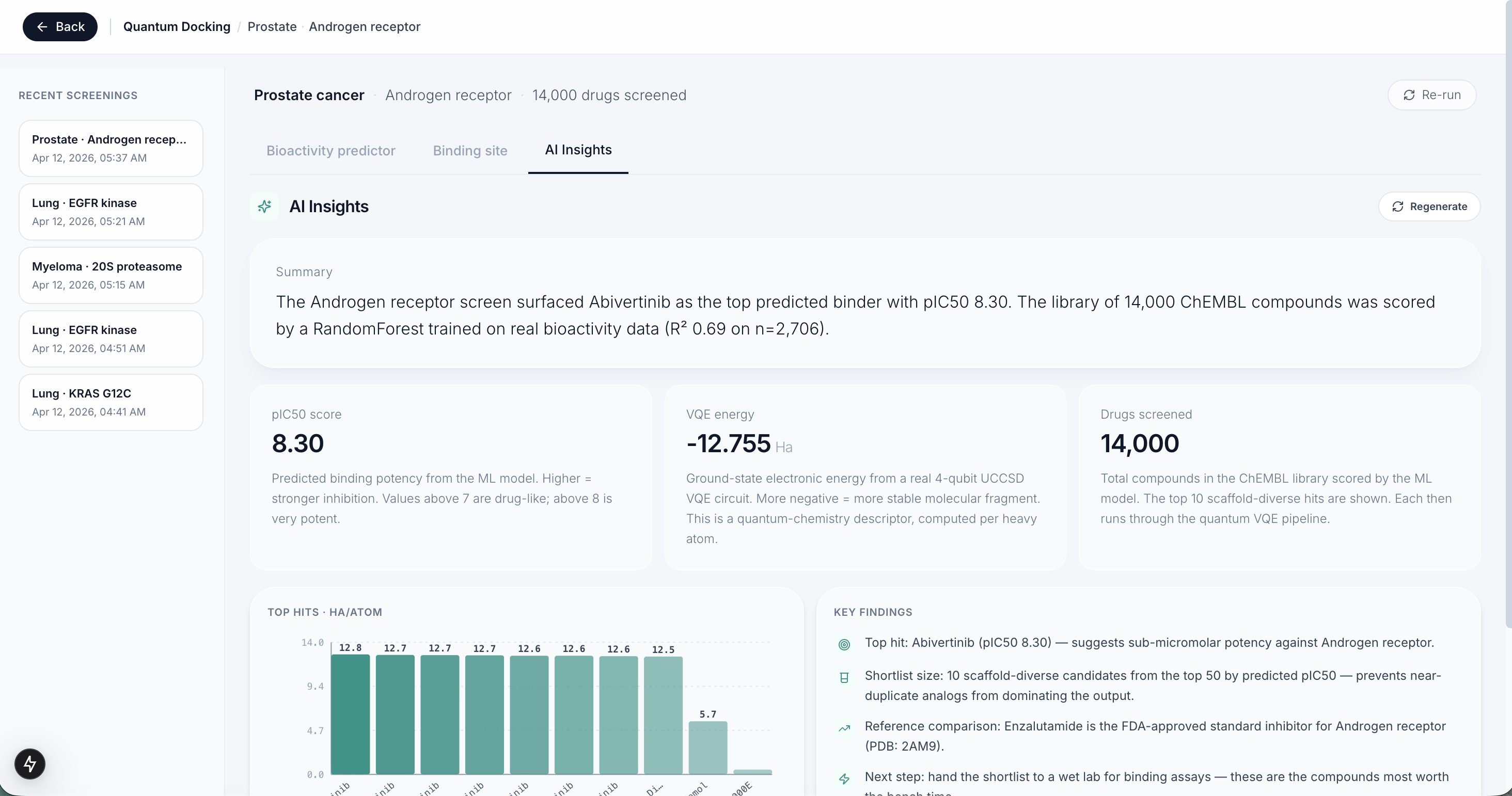
AI Insights
-
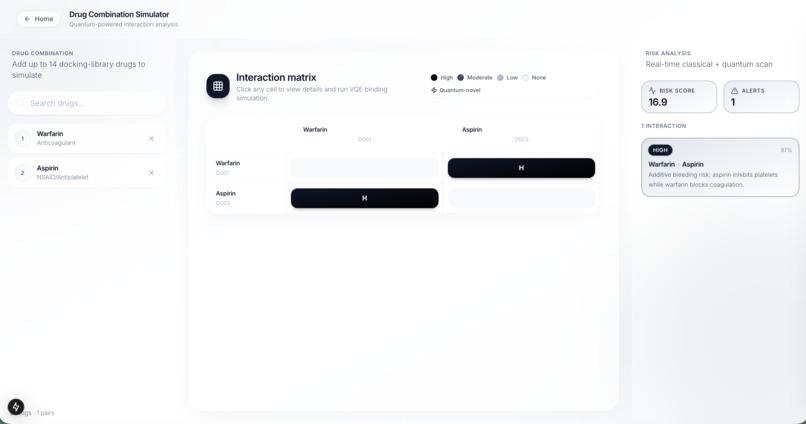
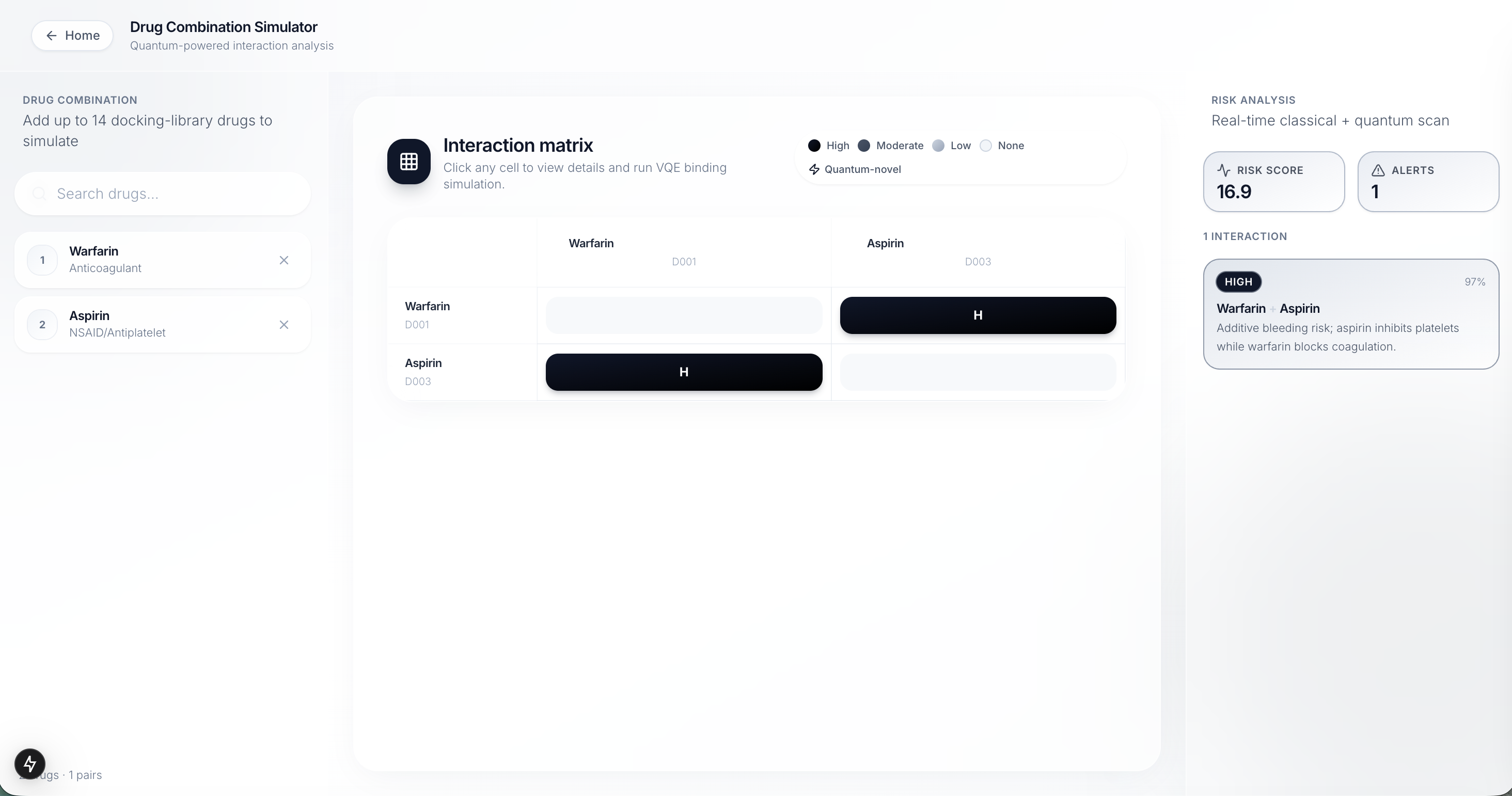
Drug Interaction Simulator
-

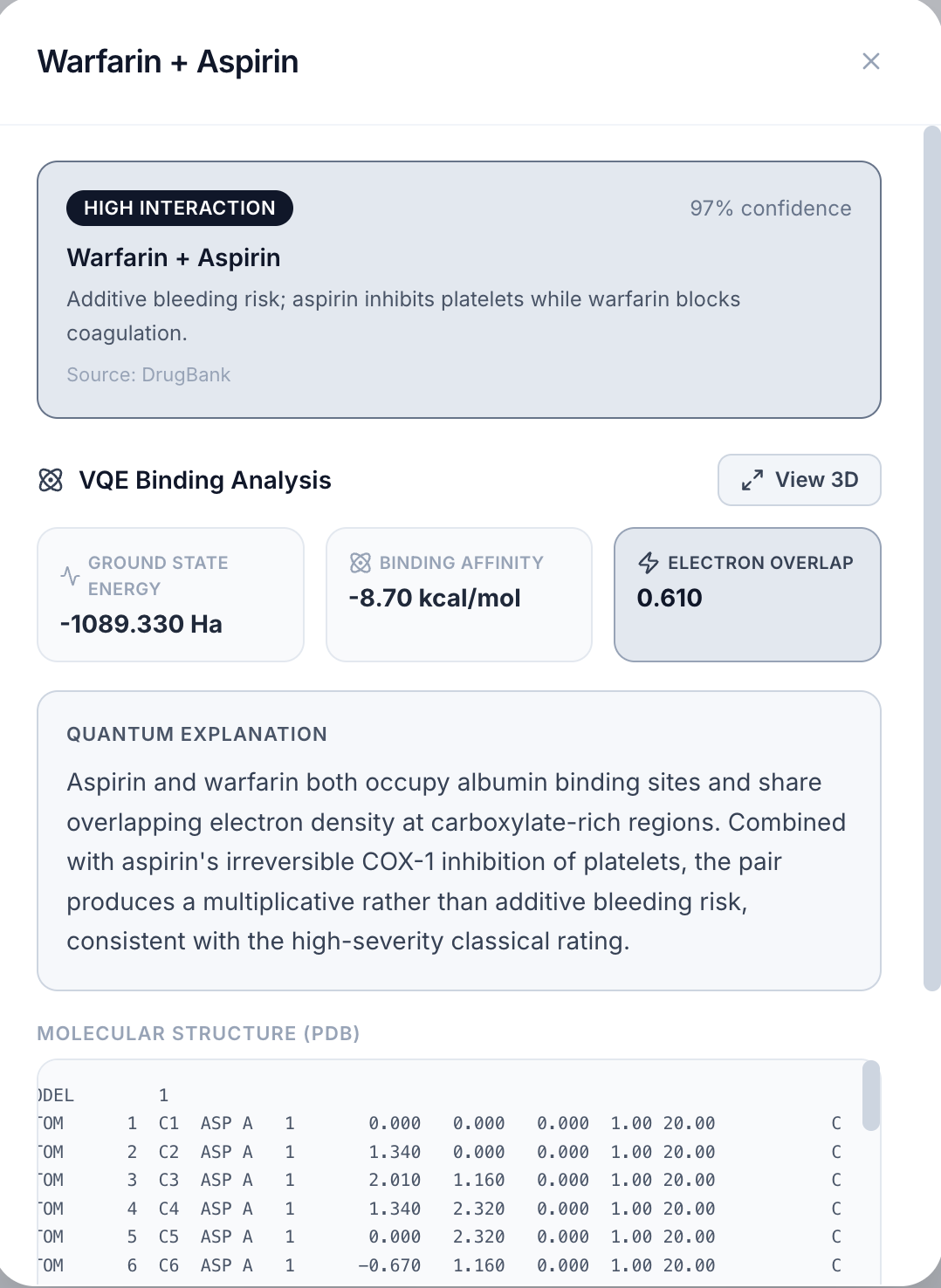
Drug Interaction Report
-
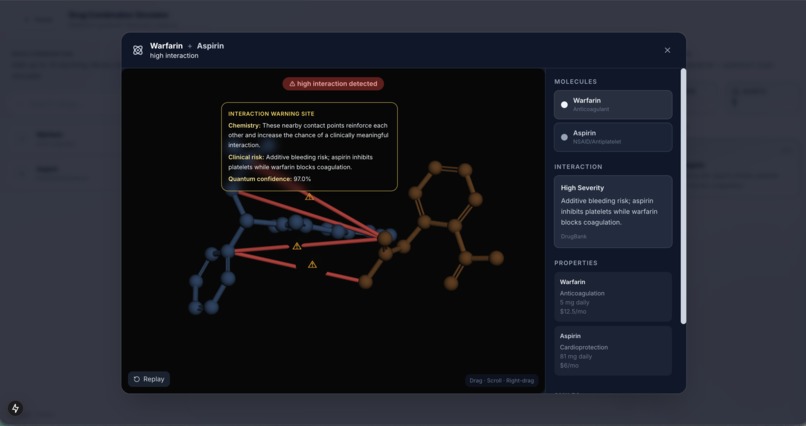
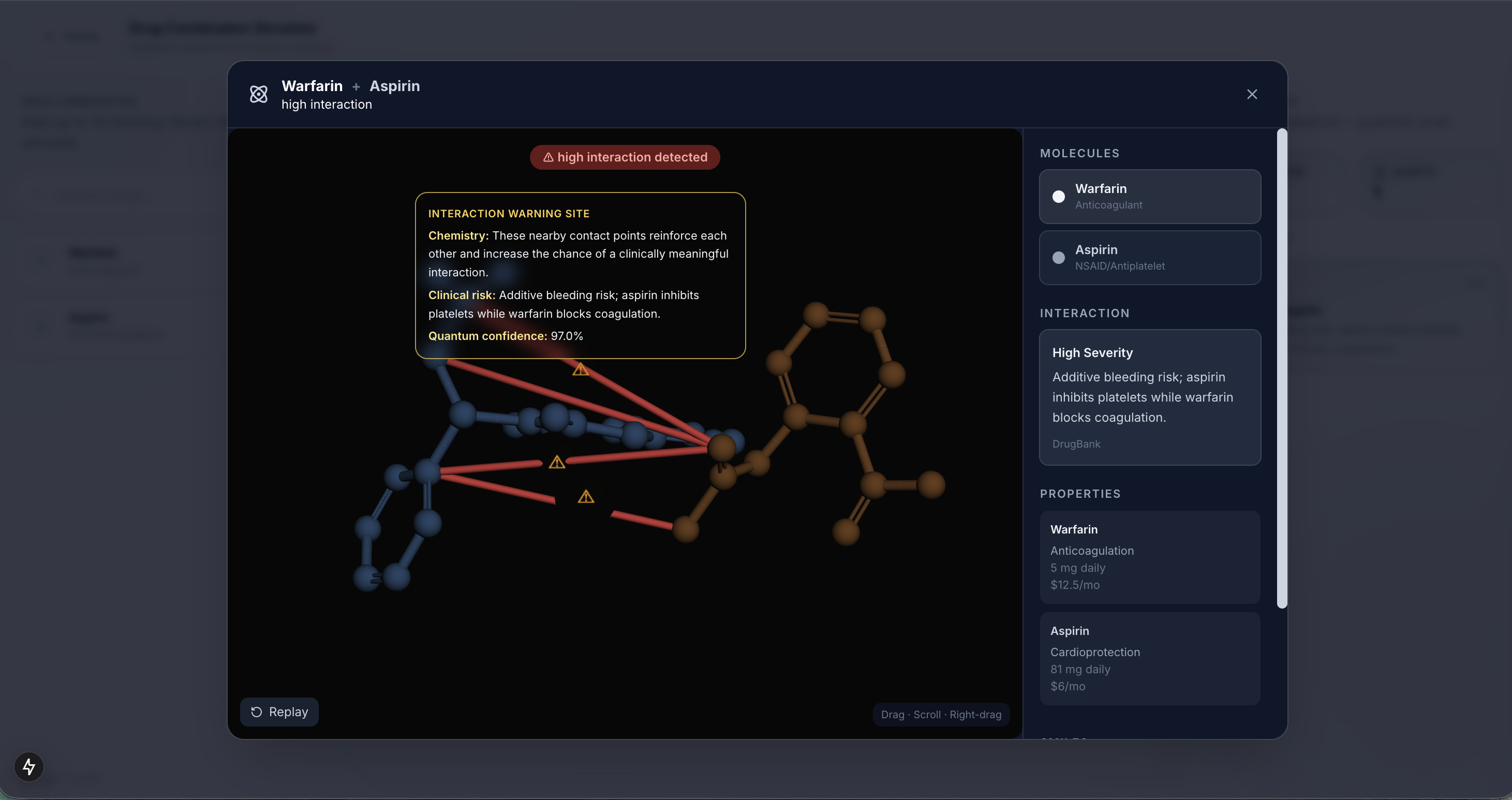
Drug Interaction 3D Visualization
-
Landing Page Slide 1
-
Landing Page Slide 2
-

Landing Page Slide 3



How we built it
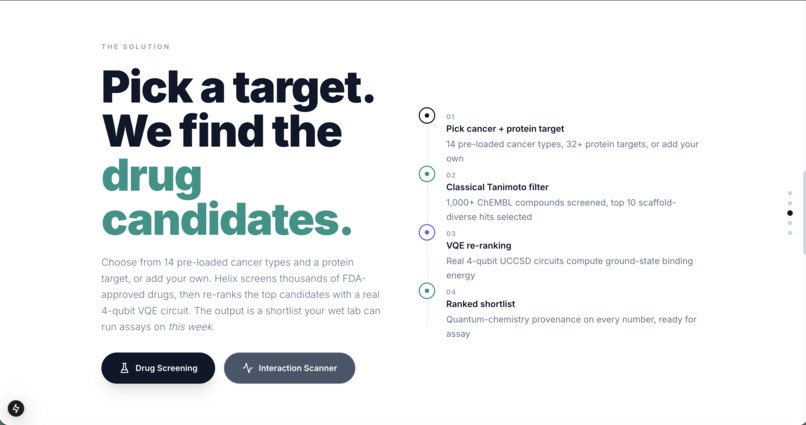
We built Helix in three layers. The first layer pulls 14,000 real drug compounds from ChEMBL, the world's largest open drug database, and trains a machine learning model on real lab experiments for each cancer protein target. The second layer runs every compound through that model to narrow 14,000 options down to 10 candidates in seconds. The third layer runs a real quantum algorithm called VQE on each of those 10 drugs to compute how stable the molecule is at a quantum chemistry level, giving researchers an extra signal that no standard tool produces.
Challenges we ran into
Getting quantum circuits to work on real drug molecules was harder than expected because quantum chemistry requires molecules to have an even number of electrons, and most drug fragments do not. We had to write custom preprocessing logic to fix each molecule before it would run without crashing. Cleaning the training data was also a big challenge since the raw database had duplicate experiments and inconsistent measurements that we had to filter out before the models could learn anything useful.
Accomplishments that we are proud of
Every number in Helix comes from a real source. The machine learning models were trained on thousands of real lab experiments, the quantum energies are real circuit outputs, and the drug library is real ChEMBL data. We are also proud that the system never just breaks. If a model is missing, it falls back to similarity screening automatically, and if the backend is off, the frontend still works on cached data.
What we learned
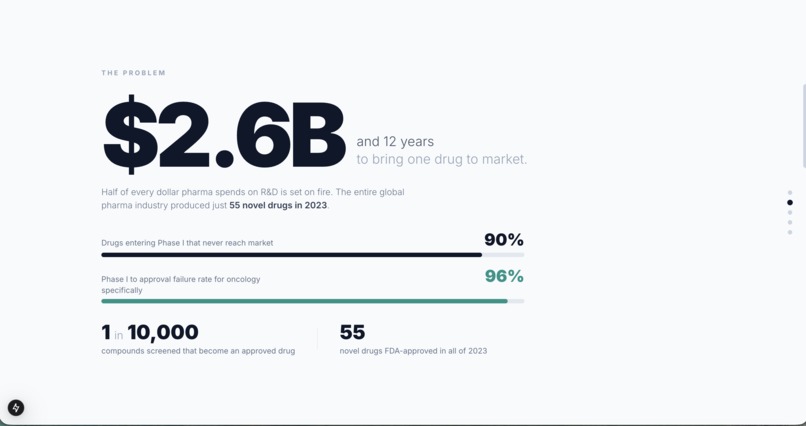
Quantum computing is a very specific tool and knowing where it fits matters more than using it everywhere. We also learned that the real problem in drug discovery is not speed, it is that 96% of drugs fail in clinical trials because early screening misses too many good candidates.
What is next for Helix
We want to scale the quantum layer to run on real IBM quantum hardware, which we already have the integration built for and just need hardware access to turn on. On the machine learning side, we want to switch to graph neural networks that reason about the shape of a molecule instead of a flat fingerprint, which should make predictions significantly more accurate. Long term, we want the system to learn from real lab results so every experiment a researcher runs makes the next round of predictions better.






Log in or sign up for Devpost to join the conversation.