-
This is the Soup Training Case
-

This is where we cleaned and analyzed the provided data

Inspiration
The need for a smarter and more accurate product search system for customers is what inspired this project. The traditional keyword systems often return irrelevant results because they don’t understand shopper intent or product details. We saw an opportunity to apply data science, embeddings, and re-ranking models to make search results more accurate and personalized. Our goal is to help HEB improve how products are matched to search queries using semantic searching instead of basic keyword matching.
What it does
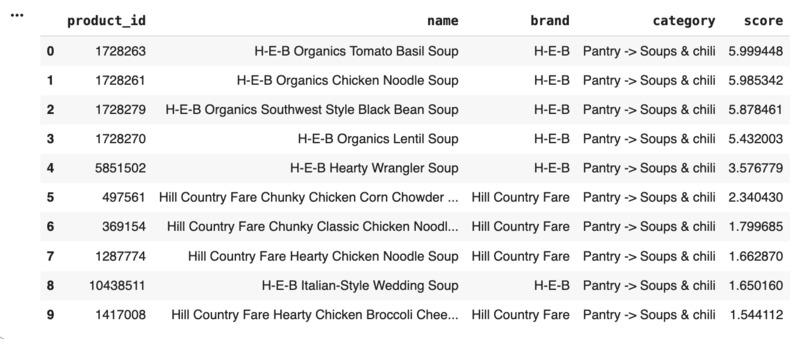
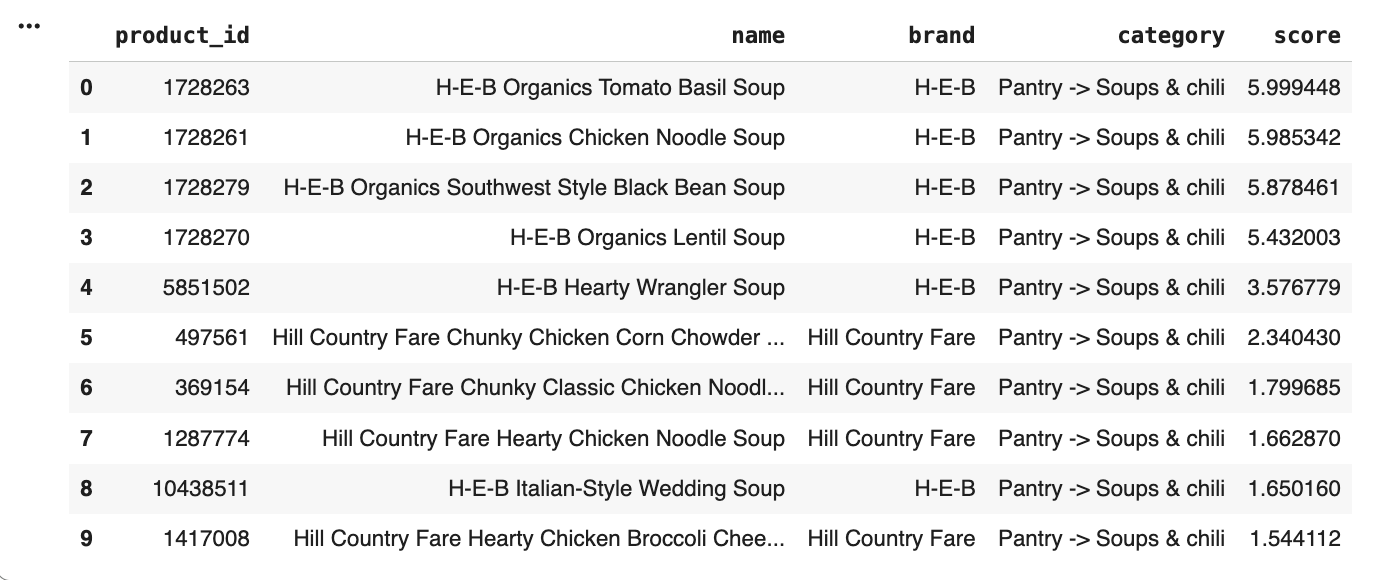
Our model takes a customer’s search query and ranks H-E-B products based on how closely they match what the shopper is looking for. It combines multiple product fields such as title, brand, category, and description to understand context and meaning. Using OpenAI embeddings, it generates vector representations of products and queries to capture semantic relationships between them. The system then retrieves the most relevant candidates and re-ranks them using a cross-encoder model to ensure that the top results are meaningful and relevant to what the customer is looking for.
How we built it
We began by cleaning and preprocessing H-E-B’s product catalog, focusing on key fields such as title, brand, category, and description. Each field was normalized by converting text to lowercase, removing punctuation, and filtering out common stopwords. This ensured that the embeddings focused on meaningful product information rather than irrelevant tokens and formatting. Next, we used OpenAI’s text-embedding 3-large model to convert both product data and customer queries into high-dimensional vectors. Each product field (title, brand, category, and description) was embedded separately to preserve its unique context. We then applied custom weighting to these embeddings (w_title= 0.8, w_brand= 0.05, w_cat= 0.10, w_desc= 0.05) before concatenating and normalizing them into a single high-dimensional vector. To make searches efficient, we stored all product vectors in a FAISS inner-product index, which allows the system to quickly compare query embeddings with millions of product embeddings and retrieve the most similar matches based on cosine similarity. The top matches from this retrieval step are then passed to a cross-encoder model (ms-marco-MiniLM-L-6-v2). This model reads the query and product description together and assigns a learned relevance score, effectively re-ranking the results for better precision.
Challenges we ran into
One of the biggest challenges we faced was balancing precision and recall. Some queries were very broad while others were highly specific, which made it difficult to tune our weighting system so that the model performed well in both cases. However, our biggest challenge came when trying to integrate a VLM to interpret product images. The goal was to connect visual features like brand logos, nutritional labels, and packaging details to the text-based query attributes. We experimented with several models, including CLIP, SigLIP, and BLIP, and while most of them technically worked, they didn’t improve our ranking performance in a meaningful way. After multiple trials, we found that the added complexity didn’t translate to better results, so we decided to focus our efforts on refining the core text-based model instead.
Accomplishments that we're proud of
We are proud of building a fully functional semantic search system that accurately ranks products based on customer intent. By combining OpenAI embeddings, a FAISS retrieval index, and a cross-encoder re-ranking model, we created a pipeline that consistently delivers precise and meaningful search results. We were able to run our model against the queries_synth_train.json file to test it where we got our highest score of 0.672.
What we learned
We learned how powerful semantic embeddings can be for improving search relevance and understanding user intent. Additionally, it taught us how much small adjustments like normalization, field weighting, and re-ranking thresholds can impact overall performance.
What's next for HEB Challenge
Next, we plan to expand our system into a true multimodal search model by integrating visual understanding and structured product attributes. This would allow the system to interpret not only product text but also images, nutritional information, and packaging details, making search results even more accurate and personalized.


Log in or sign up for Devpost to join the conversation.