
Inspiration
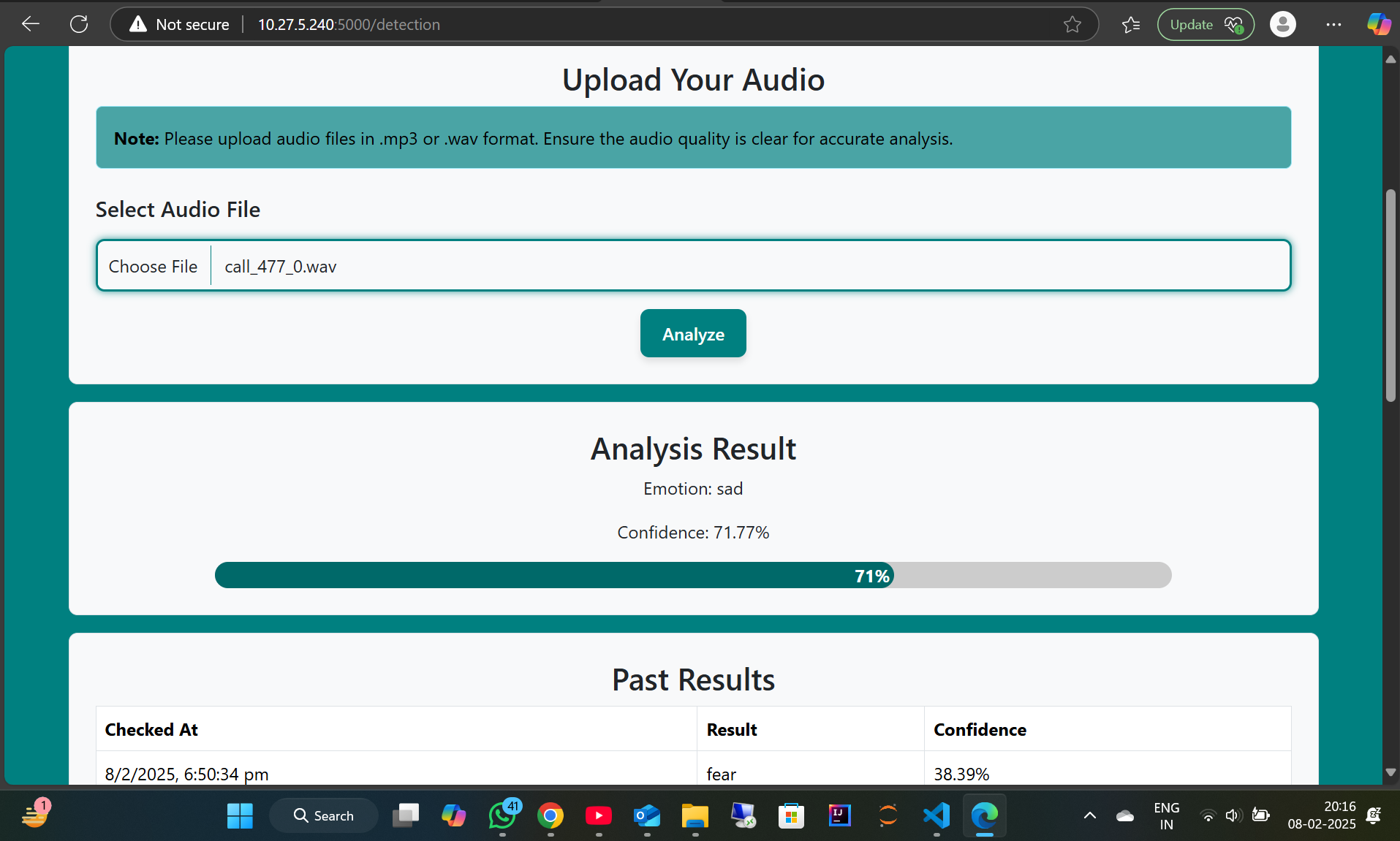
Mental health struggles often go unnoticed, especially among students and working professionals who live away from home. Despite frequent video calls, parents remain unaware of their child’s emotional state because emotions are not always visible in facial expressions—they hide in tonal shifts, speech patterns, and unspoken words. Existing solutions primarily focus on analyzing visual cues, but Hear2Help bridges this gap by utilizing AI-powered audio analysis to detect early signs of distress.
What it does
Using TensorFlow, Keras, and Librosa, our model processes voice recordings to predict emotional well-being. Beyond emotion detection, Hear2Help is a comprehensive mental health platform designed for both individuals and their well-wishers. Our key features include:
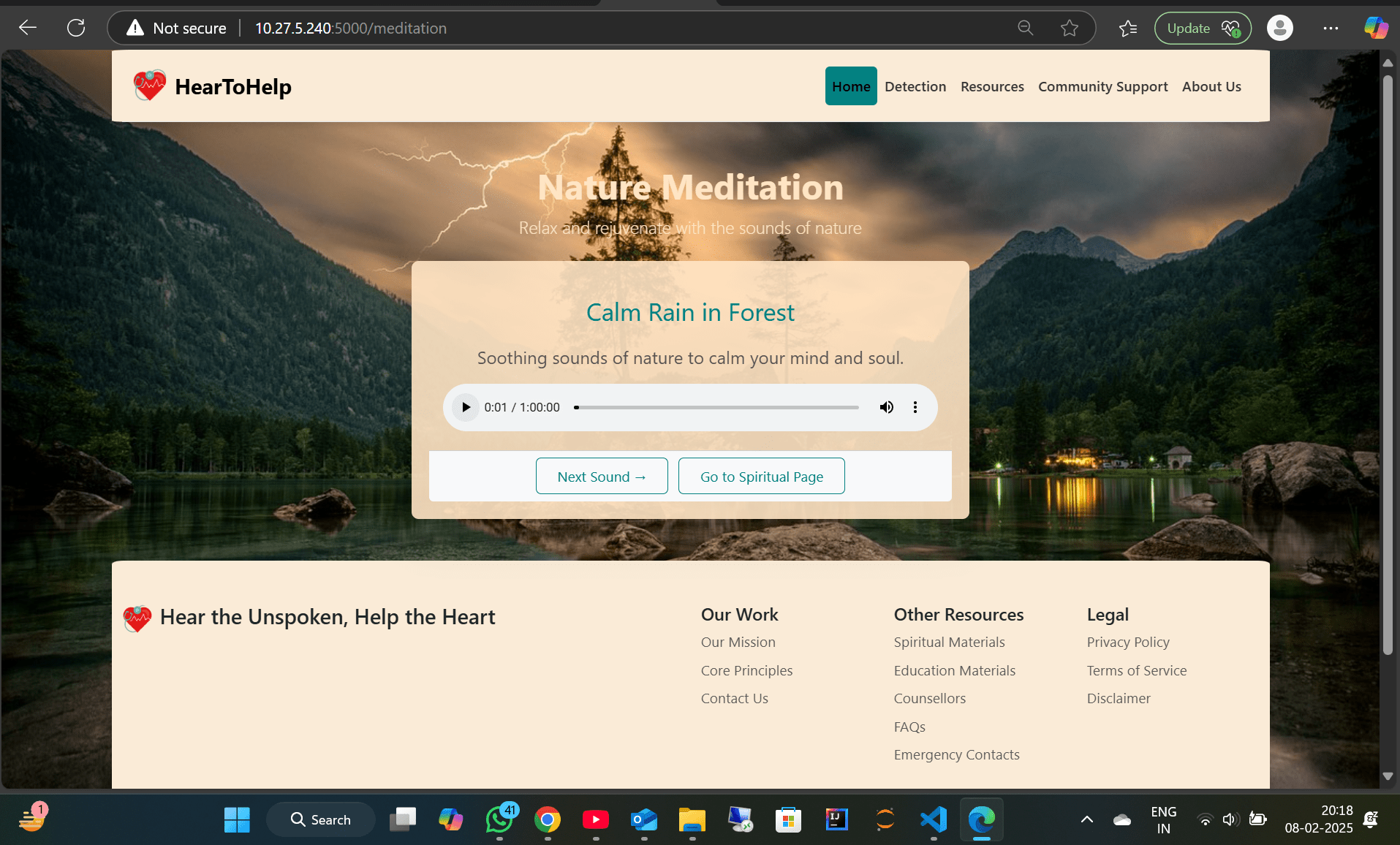
-> Meditation & Spiritual Resources – Dedicated section offering guided meditation and spiritual support to help users find inner peace.
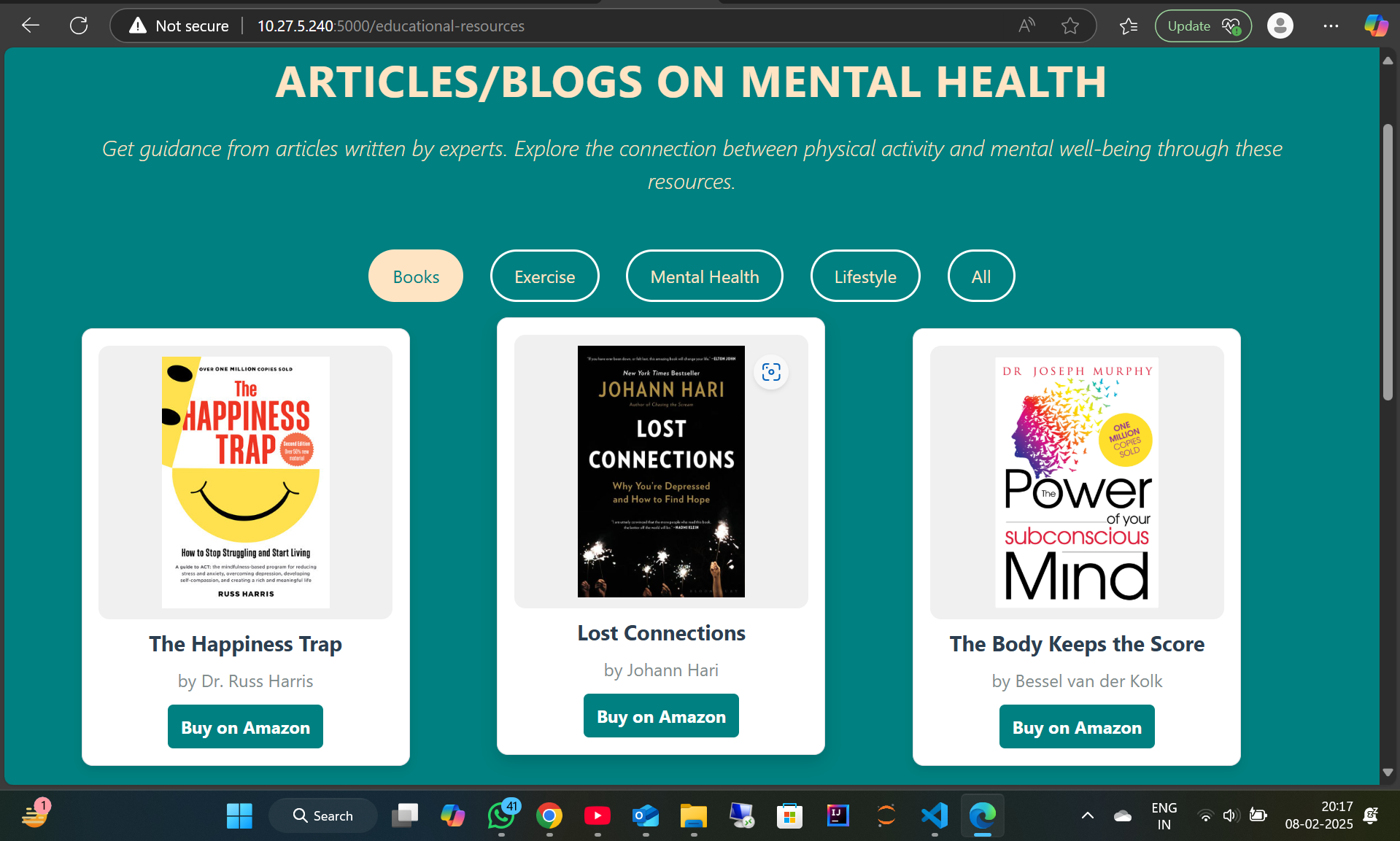
-> Educational Resources – Provides curated content to spread awareness about mental health and coping strategies.
-> Counselor’s Portal – Users can use it to connect with certified mental health professionals for guidance and support.
-> Emergency Contacts – For quick access to helplines and immediate support for those in crisis.
-> Community Support & Feedback – provides a safe space for individuals to share experiences, seek guidance, and offer support.
How we built it
🔹 Backend
Flask - Lightweight Python web framework
Librosa - Audio processing & feature extraction
🔹 Frontend
Bootstrap - Styling & UI components
Vanilla CSS - Custom styles
🔹 Data Analysis And Predictive Modelling
Librosa - Data Preprocessing
Numpy and Pandas - Data Analysis
Matplotlib & Seaborn - Data Visualization
TensorFlow & Keras - Model training & inference
Challenges we ran into
Initially we thought of working with express and ejs but later when we tried to integrate our model on our platform, we started getting bugs and we were unable to integrate our ML model on the website, then we rewrote the entire backend to flask to make the model run. Improving the model's accuracy was a very challenging task. Since we were working on audio data, which is somewhat in itself a challenging task because of the change in phonetics and linguistics, the model took our most of the time to get towards decent accuracy. Training an LSTM model on a large sound dataset is in itself a tedious task.
Accomplishments that we're proud of
- Successfully creating the dataset and creating a deployable machine learning model with an accuracy of 90%
- We shifted the backend to flask at short notice to make the model work.
What we learned
This was a great learning experience- from building a model to integrating it with the website.
What's next for HeartoHelp
In the future, Hear2Help aims to expand into real-time audio analysis, allowing for instant detection and intervention—just like True-caller but for mental health. We refuse to let another student’s name become just another statistic. It’s time to truly listen. Hear2Help is listening.
Built With
- css
- flask
- html
- javascript
- librosa
- python
- tensorflow
- vanilla




Log in or sign up for Devpost to join the conversation.