-
-
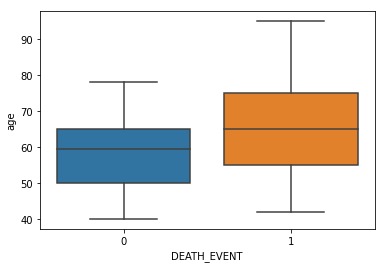
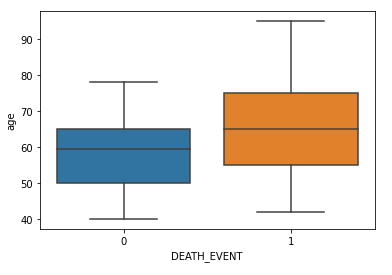
Feature Selection
-
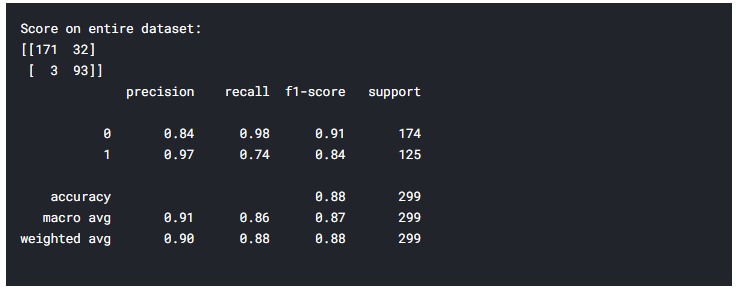
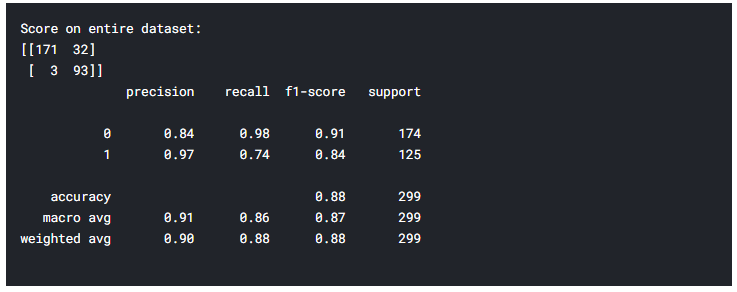
Overall Model Metrics
-
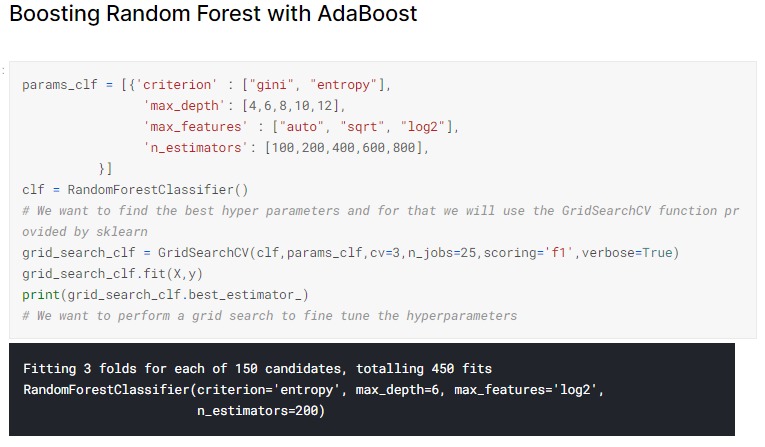
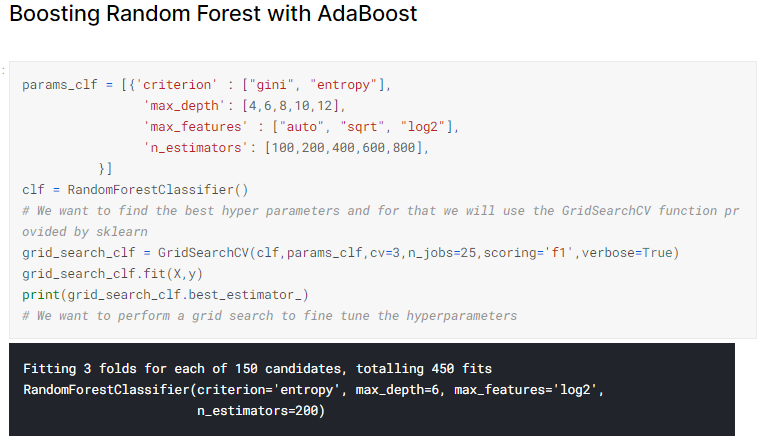
AdaBoost Hyperparameter Tuning
-
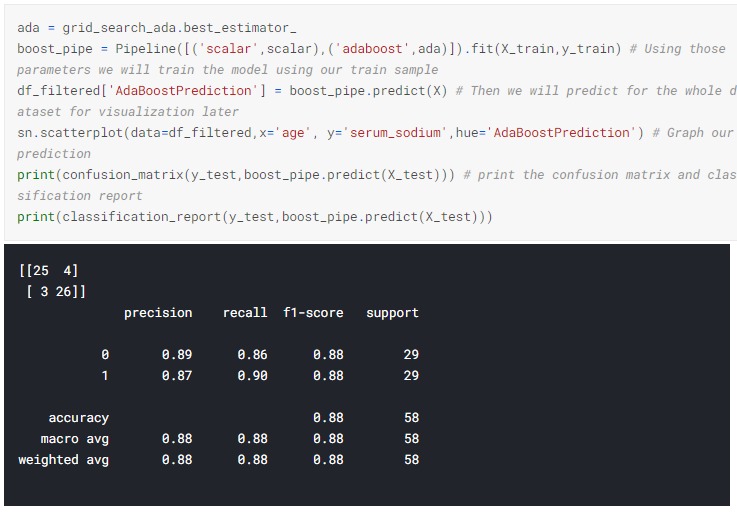
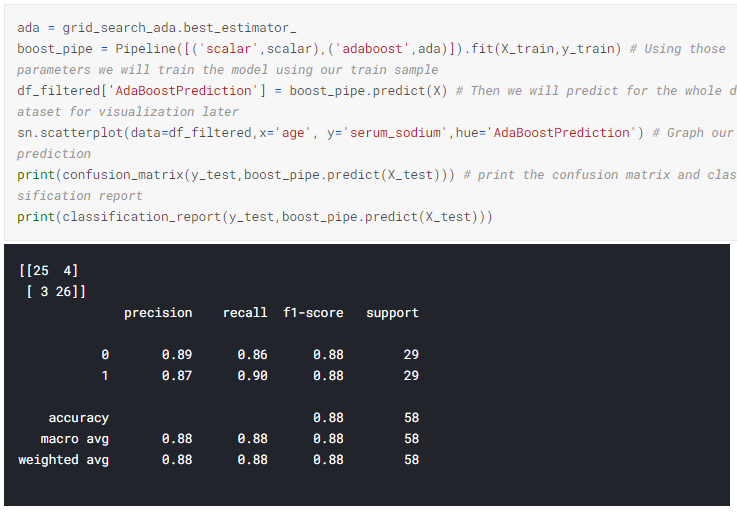
AdaBoost Model Performance
-
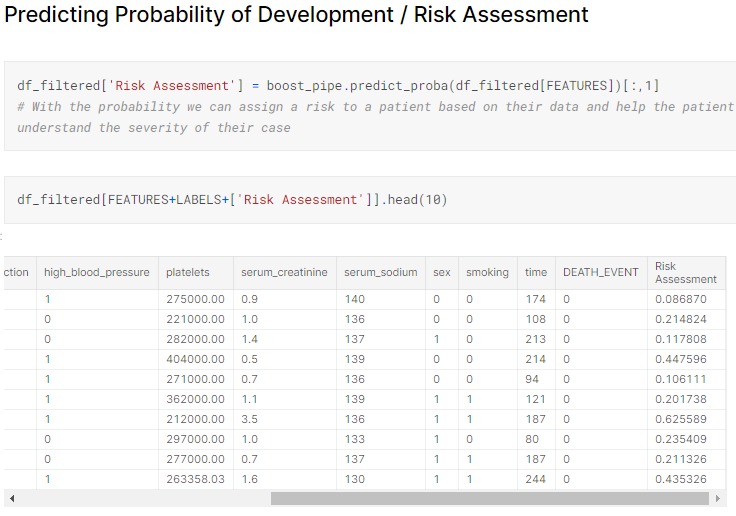
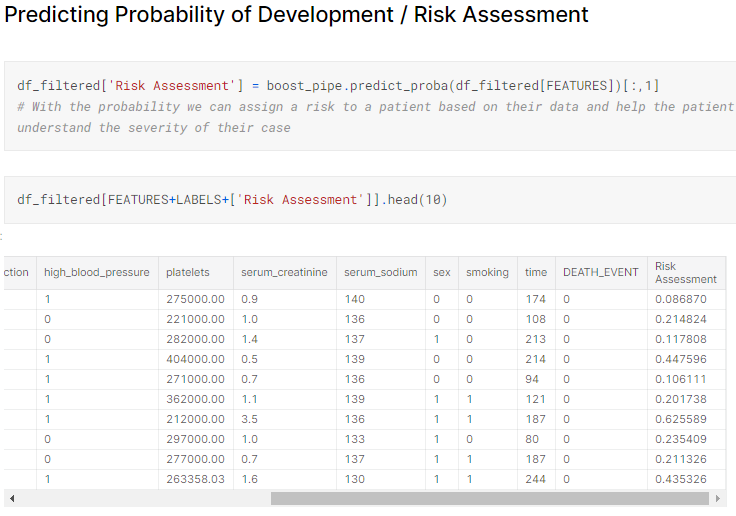
Risk Assessment
-
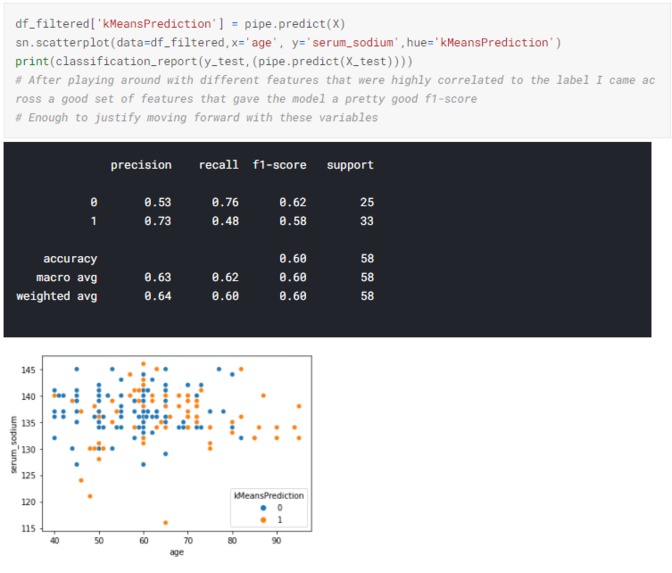
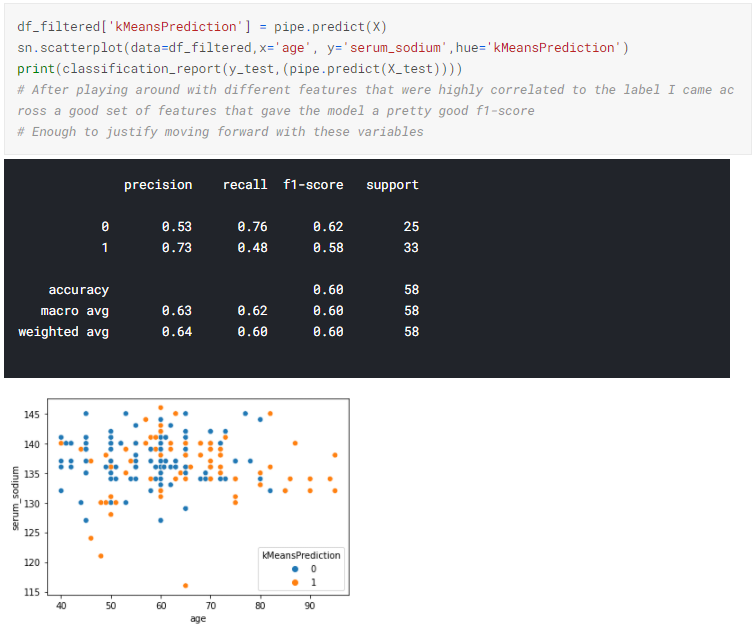
K-Means Model Performance
-
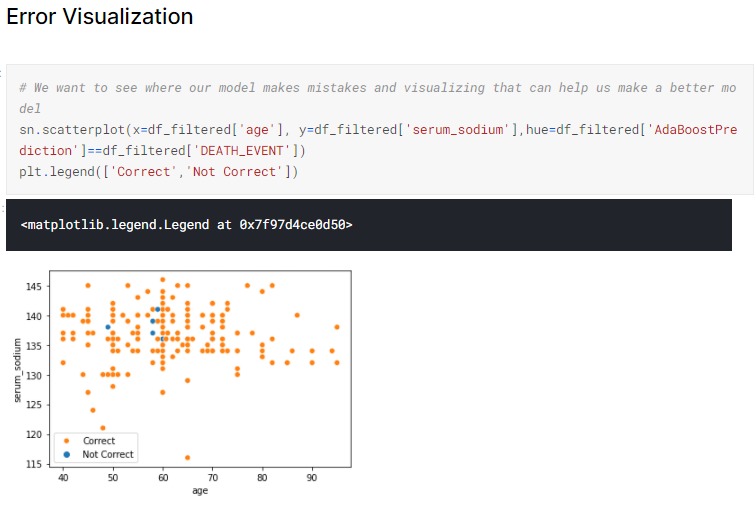
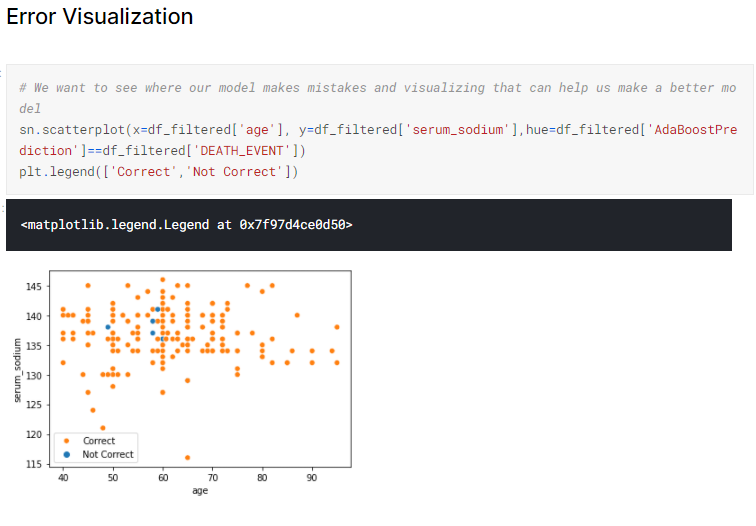
Error Visualization
-
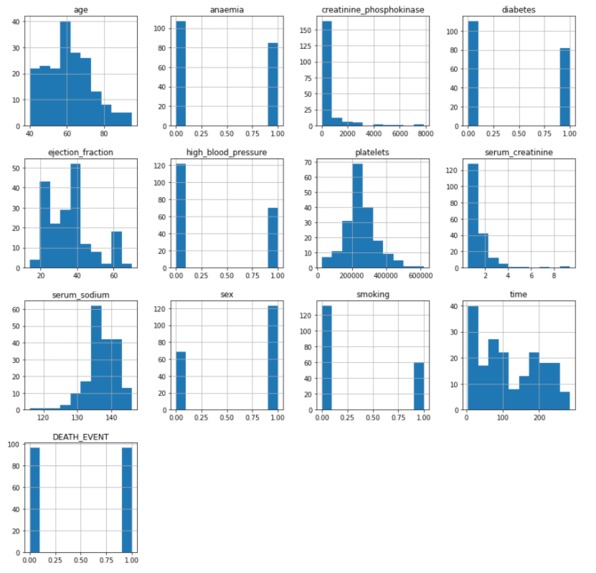
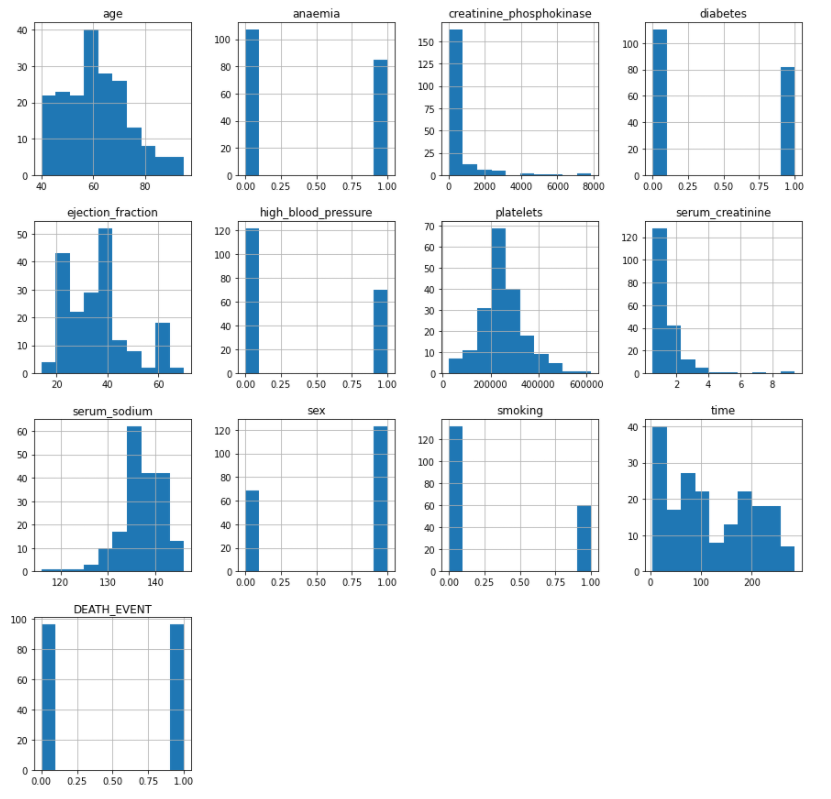
Data Wrangling
Heart Failure Classifier
Classifies cardiovascular risk with various health metrics




Updates

Leave feedback in the comments!
Log in or sign up for Devpost to join the conversation.