Inspiration
As a lot of people are suffering from late diagnosis of heart diseases we wanted to do our part and hence made a program with only a few inputs from the user can predict weather the patient is in risk of a heart disease or not
Working
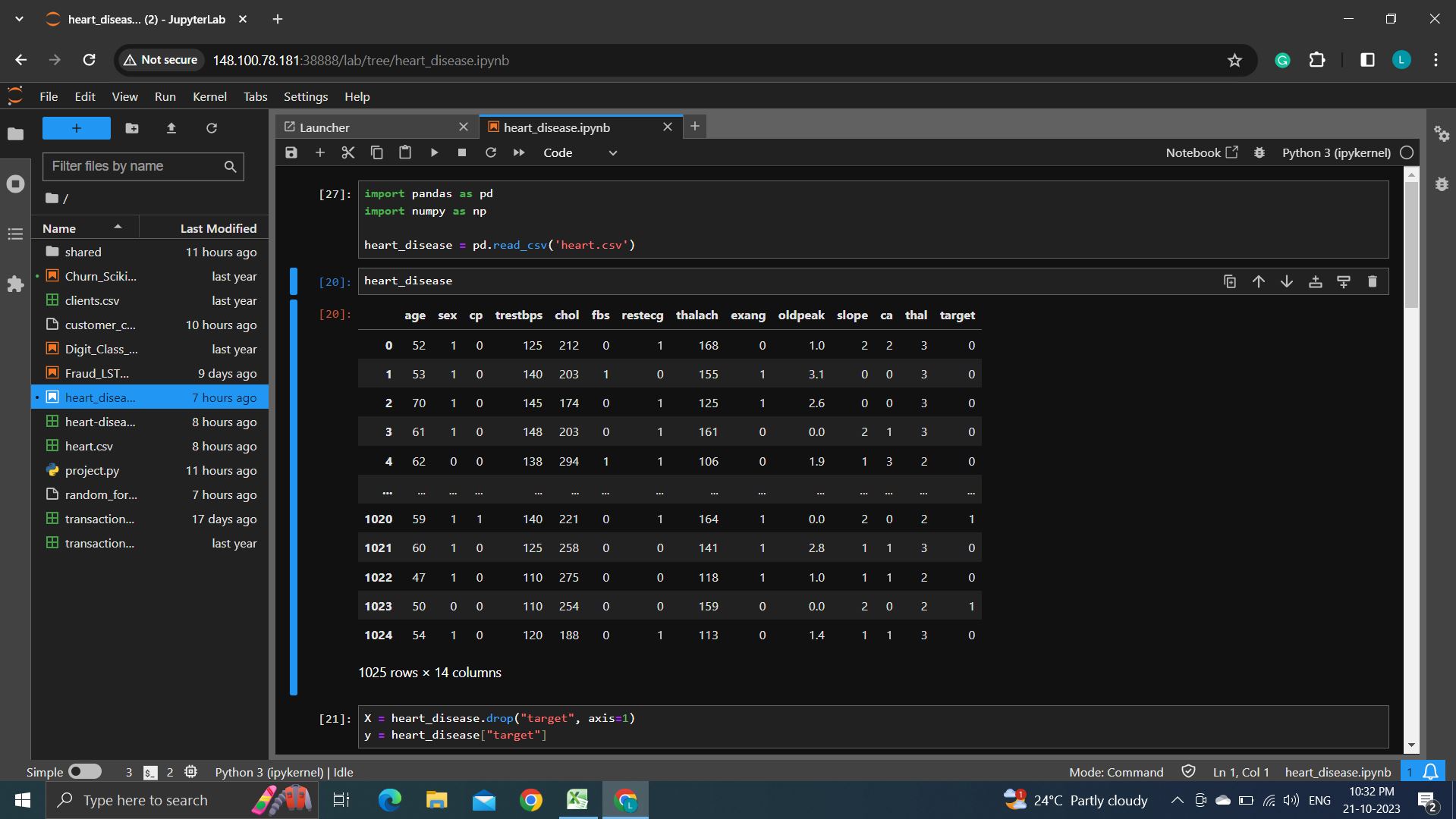
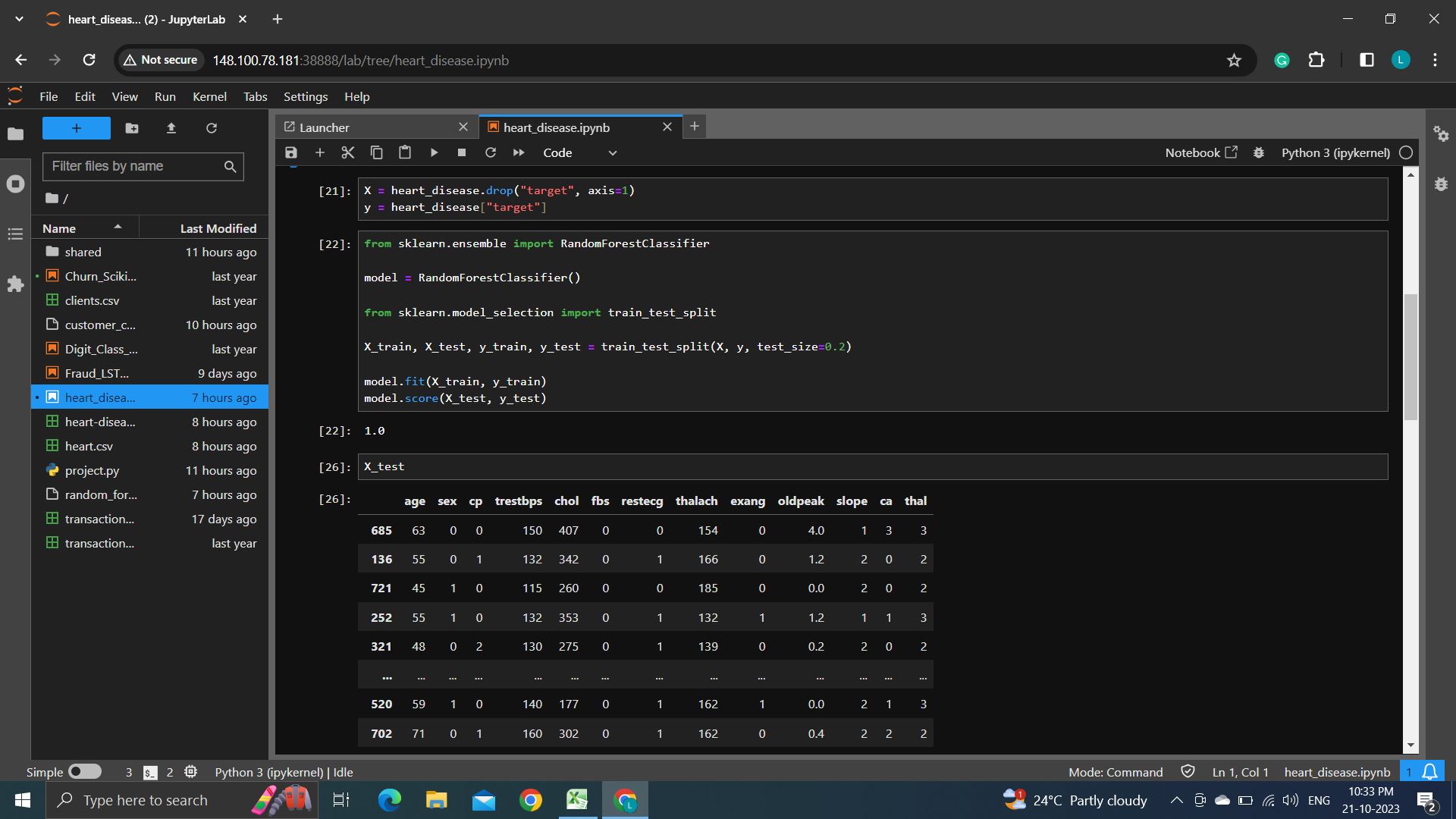
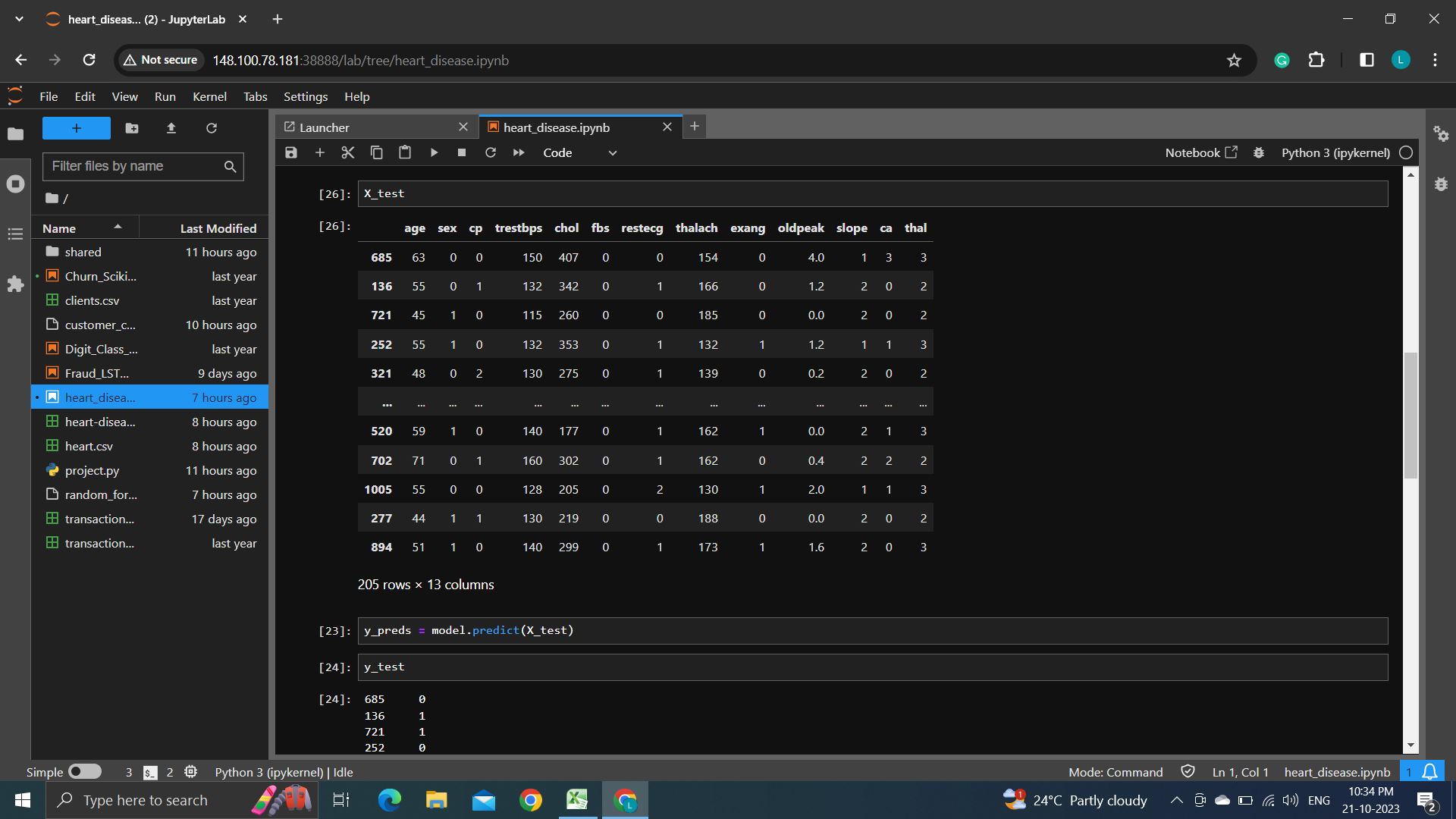
We used a Random forest separation model and the datasets are taken from Kaggle and It uses the train_test_split function from scikit-learn to split the data into training and testing sets. 80% of the data is used for training (assigned to X_train and y_train), and 20% is used for testing (assigned to X_test and y_test). The code trains the Random Forest Classifier model (model) on the training data using model.fit(X_train, y_train).
Challenges we ran into
The challenges we ran into was finding all the different data and understanding what it means and how these different data can be related to heart problems and how to train the ML model to use these different data sets .As engineers these medical data was a challenge for us to process and use.
Accomplishments that we're proud of
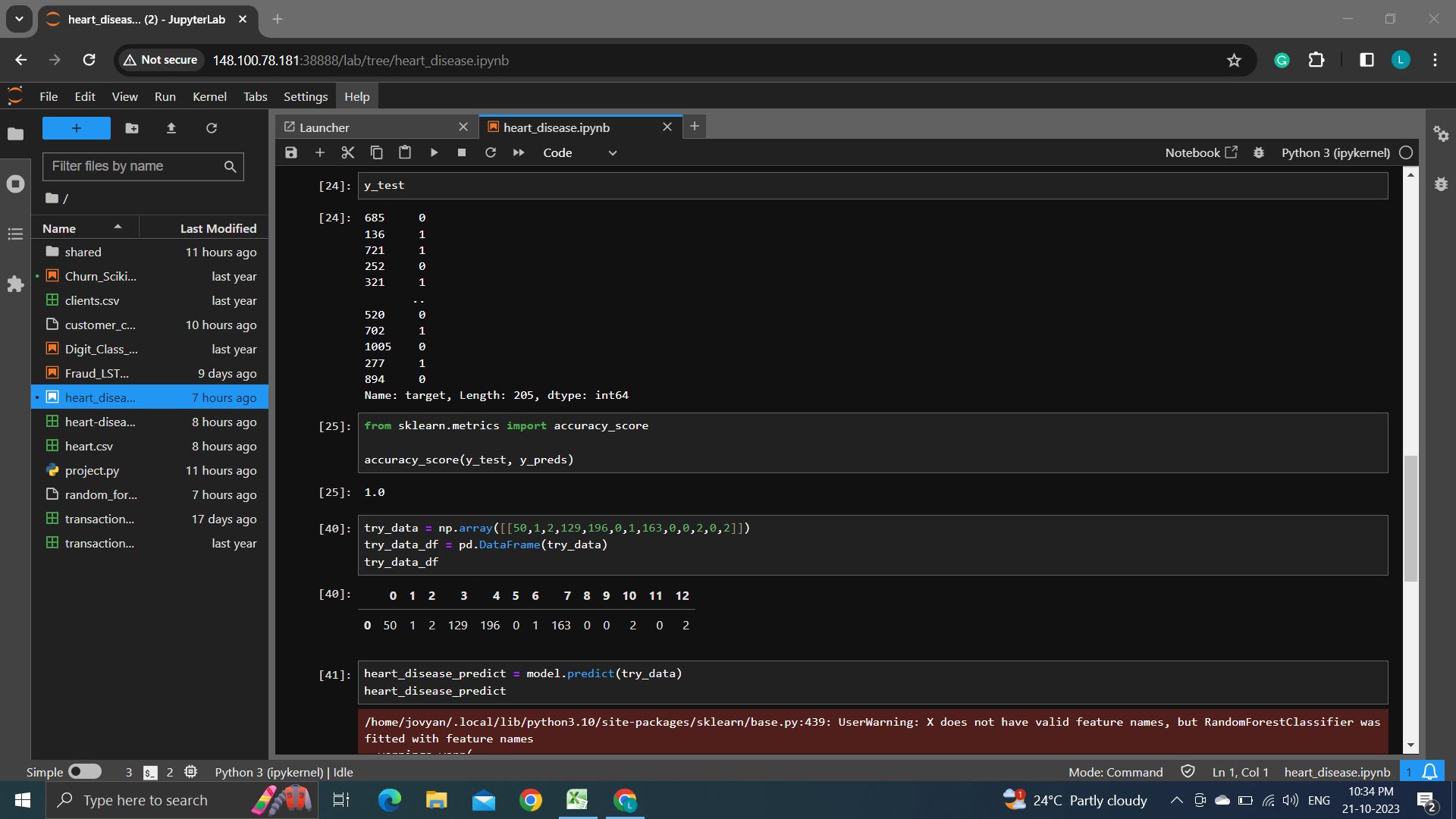
We are proud that we made a working model with nearly 90% accuracy
What we learned
We learnt a lot about the causes of heart diseases and how to control them is in our hands and on how we could leverage the IBM servers and use LinuxOne and Jupyter as efficient tools to run ML models and learnt on how to search,create and use various data sets
What's next for Heart Disease predictor
As the model and data sets increases we can deploy this in hospitals to make heart disease prediction easier and also make it a open-source software as anyone in any part of the world can access this model and self evaluate themselves and see weather they have a heart disease or not
Built With
- jupyter
- kaggle





Log in or sign up for Devpost to join the conversation.