-

Innovate your health care!
-
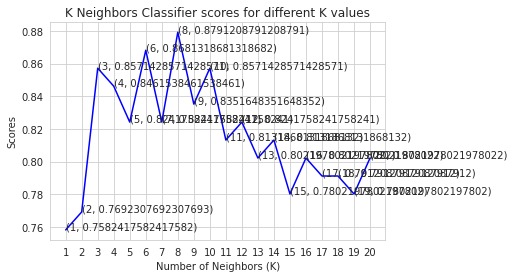
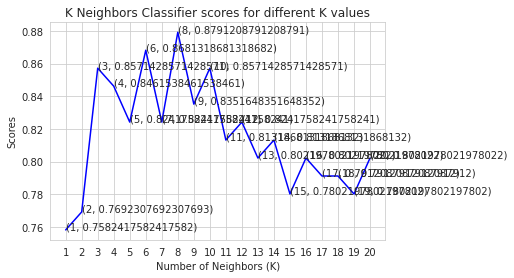
K neighbors classifiers for different K values.
-
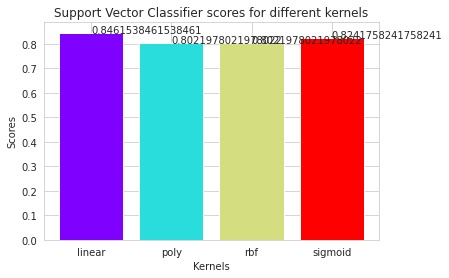
-
Different figure sizes.
-
KNN MODEL


## HEART DISEASE PREDICTOR
Cases of heart illness are developing at an alarming rate, and it is critical and important to predict any such ailments in advance. This is a challenging process that must be completed accurately and effectively. This initiative is primarily concerned with determining whether patients are more likely to have heart disease based on numerous medical characteristics. I created a heart disease prediction system that uses the patient's medical history to forecast whether the patient is going to be diagnosed with a heart ailment.
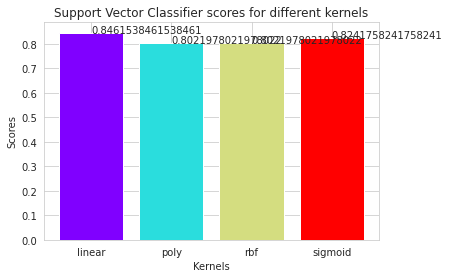
The regulation of how the model may be utilized to increase the precision of heart attack prediction in any individual was done in a very helpful way. The accuracy of this model's use of KNN, which predicts evidence of having a heart illness in a certain person, was 84%, which is a very gratifying strength. The goal of this project is to extract hidden patterns by applying data mining techniques, which are noteworthy to heart diseases, and to predict the presence of heart disease in patients where this presence is valued from no presence to likely presence.
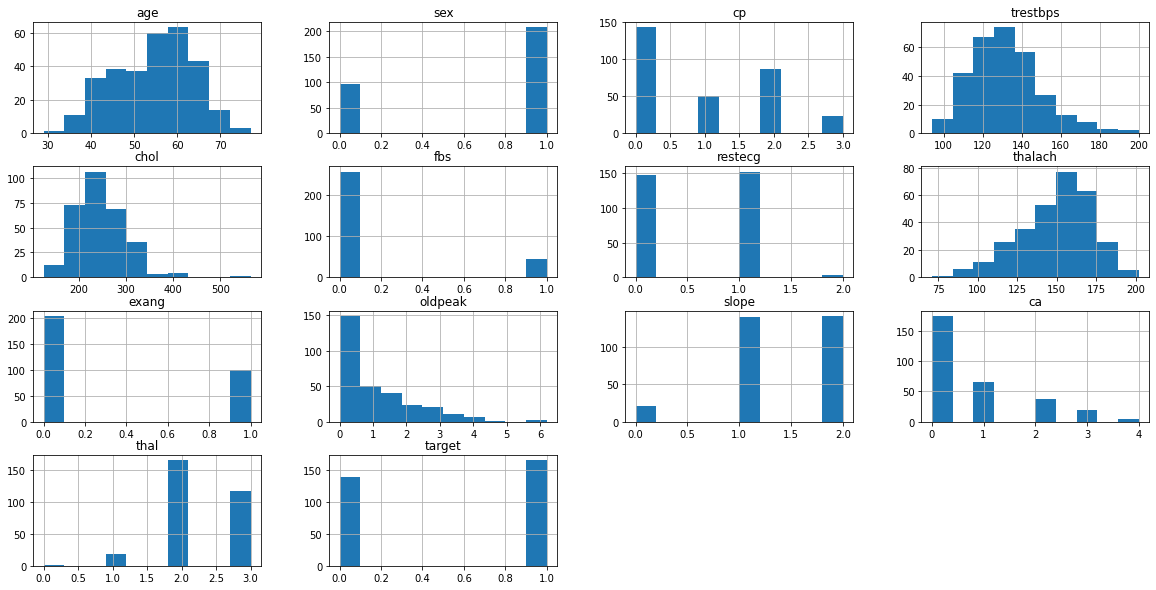
- age: The person's age in years
- sex: The person's sex (1 = male, 0 = female)
- cp: The chest pain experienced (Value 1: typical angina, Value 2: atypical angina, Value 3: non-anginal pain, Value 4: asymptomatic)
- trestbps: The person's resting blood pressure (mm Hg on admission to the hospital)
- chol: The person's cholesterol measurement in mg/dl
- fbs: The person's fasting blood sugar (> 120 mg/dl, 1 = true; 0 = false)
- restecg: Resting electrocardiographic measurement (0 = normal, 1 = having ST-T wave abnormality, 2 = showing probable or definite left ventricular hypertrophy by Estes' criteria)
- thalach: The person's maximum heart rate achieved
- exang: Exercise induced angina (1 = yes; 0 = no)
- oldpeak: ST depression induced by exercise relative to rest ('ST' relates to positions on the ECG plot. See more here)
- slope: the slope of the peak exercise ST segment (Value 1: upsloping, Value 2: flat, Value 3: downsloping)
- ca: The number of major vessels (0-3)
- thal: A blood disorder called thalassemia (3 = normal; 6 = fixed defect; 7 = reversable defect)
- target: Heart disease (0 = no, 1 = yes)
When developing the model, I prioritized achieving the maximum level of accuracy. I could improve them by further adjusting their hyperparameters.
The Given method for predicting heart disease improves medical treatment and decreases costs. This project provides substantial insights that can aid in the prediction of heart disease patients. It utilizes the .pynb file format.
Correct patient diagnosis and successful therapy delivery have grown to be fairly difficult nowadays. The majority of hospitals now handle their patient data, which can take the form of statistics, text, charts, and photographs, using hospital information systems. Disease diagnosis is a crucial and challenging task in medicine. A patient with a cardiac condition must pay a significant amount of money for treatment, which not all patients can afford. The diagnosis of heart disease based on a variety of symptoms is a puzzling issue that is usually accompanied by impulsive behaviors and a number of incorrect assumptions. In order to effectively anticipate heart attacks, it is necessary to propose an efficient method for identifying important patterns from heart disease data warehouses.
To eventually achieve 100% accuracy, I'm working on using a variety of additional machine learning models, such as CNN, Random Forest, etc. Additionally, including this in webapps supported by different health departments like pharmacies and hospitals can assist spread knowledge of healthcare-related concerns.
Built With
- datascience
- googlecolab
- logisticregression
- machine-learning


Log in or sign up for Devpost to join the conversation.