-

-
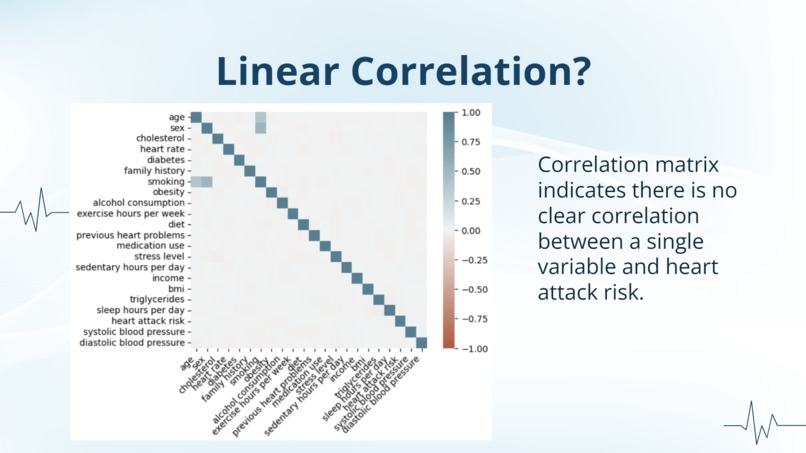
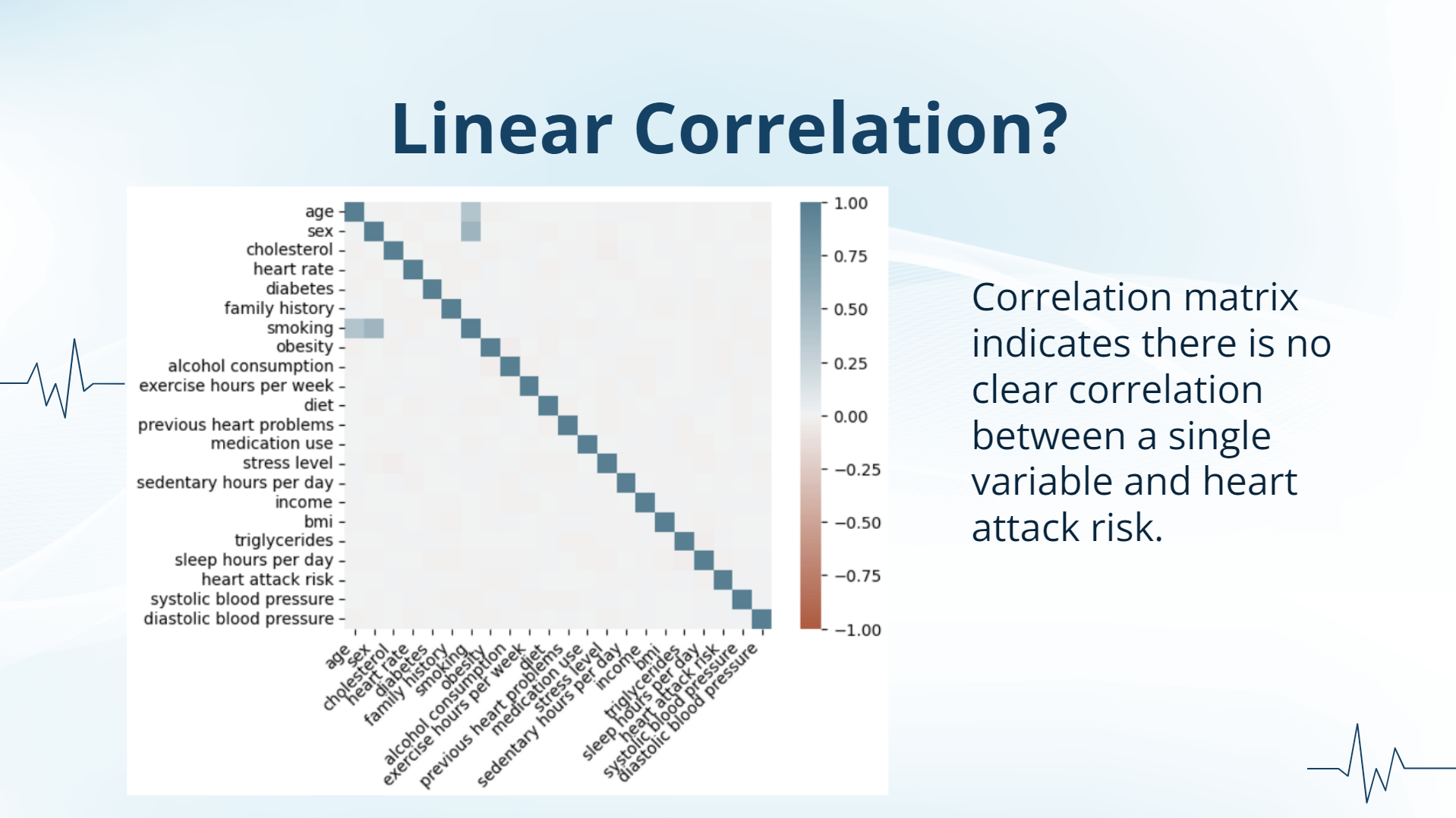
no linear correlation?
-
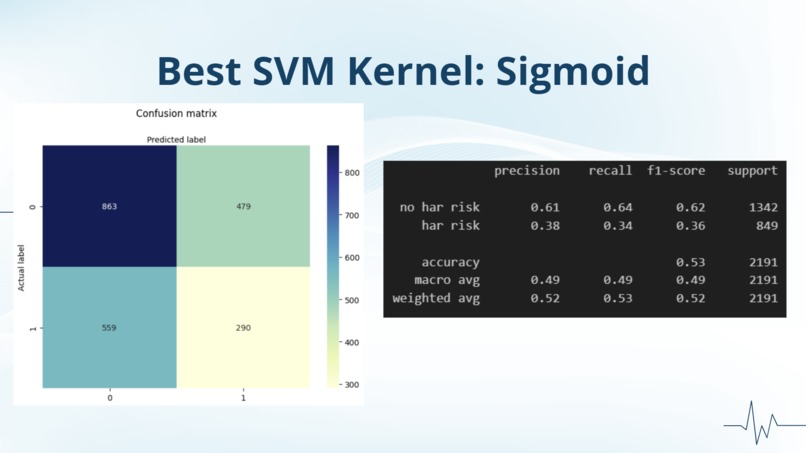
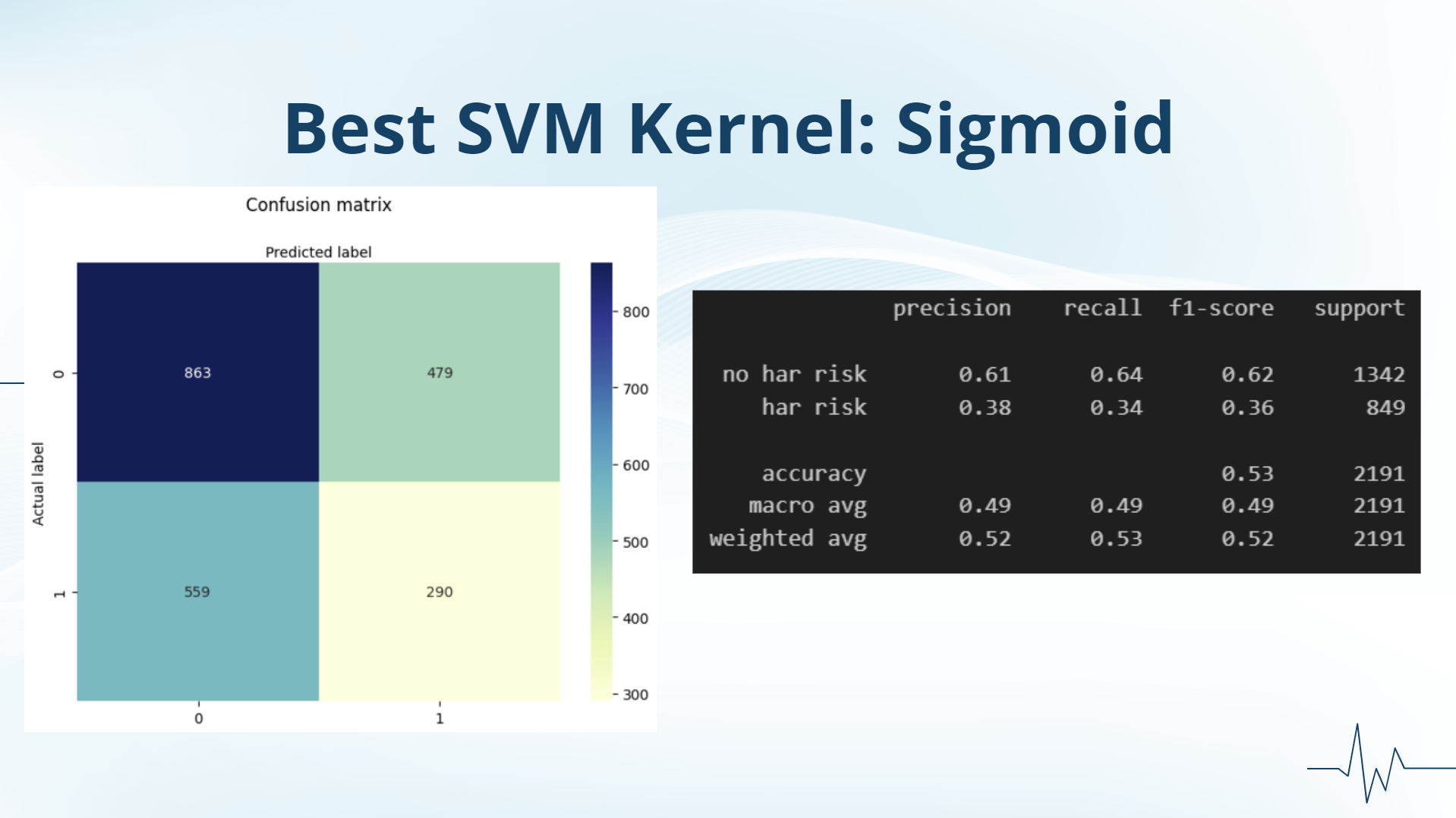
best SVM model
-
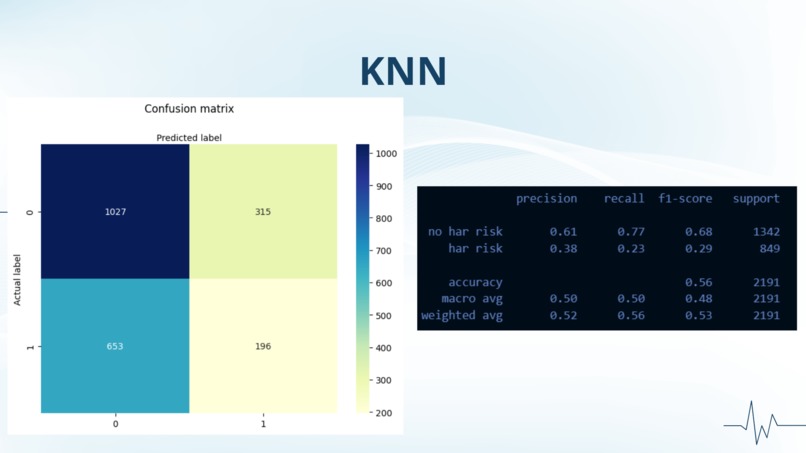
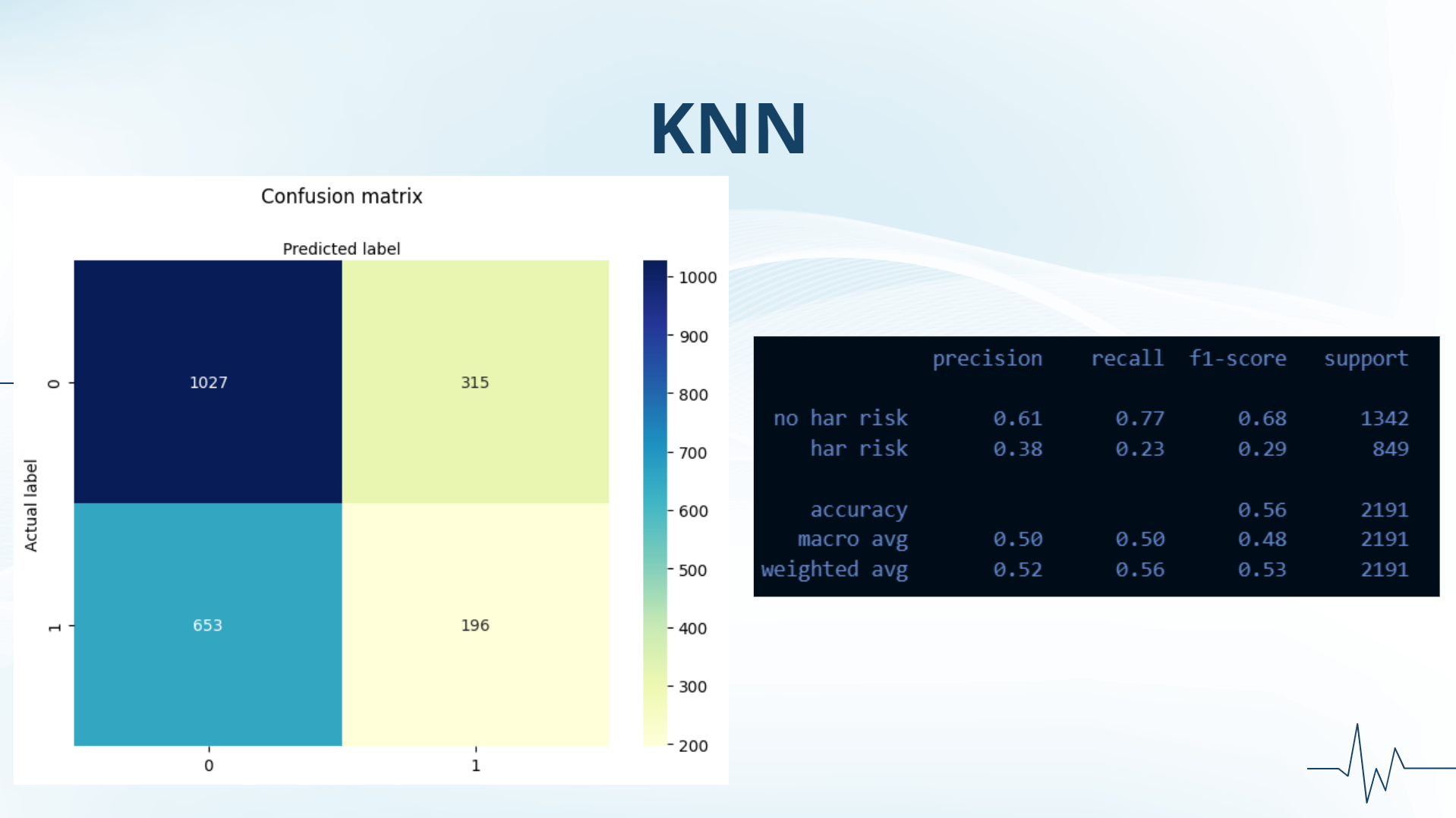
best model overall

Inspiration
As medical professionals we were concerned with what factors can cause risks in heart attacks and have embarked on this study to deepen our understanding of the factors influencing heart attacks. Our primary goal is to enhance preventive measures and interventions, empowering individuals to adopt early preventive measures that mitigate the risk of heart attacks and promote cardiovascular health.
Studying heart attacks allows the understanding of their complex interplay of factors, such as lifestyle choices which contribute to their occurrence. By delving into these aspects, we aim to unravel effective prevention strategies, encompassing maintaining a healthy lifestyle, to mitigate the risks.
What it does
Our study aims to elucidate the underlying causes of heart attacks and identify proactive strategies for prevention before they escalate to critical levels. Recognizing the multifaceted nature of this condition, we acknowledge the myriad factors that contribute to its onset, prompting us to explore comprehensive approaches to mitigate its risks and safeguard public health. By creating a machine learning model in order to predict whether a patient is at risk of having a heart attack based on their health and lifestyle, we hope to be able to use this information to implement heart attack prevention measures.
How we built it
We used python, pandas, and NumPy in JupyterNotebook for data manipulation and analysis, such as splitting the data into multiple columns, and matplotlib to create scatter plots and a heat map in order to understand our data better. For our machine learning models, we settled on a couple different models for binary classification from scikit-learn, including logarithmic regression, SVM, and KNN.
Challenges we ran into
The first challenge we ran into was absolutely no correlation to heart attack risk on all our data categories. This was surprising for us, since we expected there to be at least correlations with cholesterol, blood pressure, age, and BMI. We were worried about not being able to find anything of value from this data set, but believed perhaps individually the factors had no effect on the heart attack risk, but as a collection we might be able to see a more obvious correlation.
However, when we implemented the logarithmic regression model to our data in order to see if it was able to predict the heart attack risk of a patient with all the given stats, our model seemed to be unsuccessful. The first thing we believed was an issue was the amount of stats that a single patient had, so we decided to use SelectKBest feature select to select the most influential five factors on heart attack risk. We ended up with using the top five: cholesterol, exercise hours per week, income, triglycerides, and systolic blood pressure, all of which we expected there to be the highest correlation to heart attack risk. But even then, we were unable to get a more successful model.
Thus, we tried different kinds of models, including SVM and KNN, both of which yielded us the highest accuracy for prediction but still not as good as we expected. Another way we tried to reduce the error was to balance our data. We realized that there was a much higher percentage of patients in our data with no heart attack risk than those with heart attack risk, so we tried random oversampling which duplicates random data values for heart attack risk, but that proved unsuccessful. Our final attempt at trying to balance the data was using SMOTE, which creates synthetic data points for heart attack risk, but, unfortunately, was unable to give us a successful model.
Accomplishments that we're proud of
Though we were unable to end up with an excellent model for our data, we were able to fine tune certain aspects of our model, such as the type of model, reducing the amount of features, and data balancing in order to make our model as accurate as possible. Of course, data is not perfect, so we are very proud to be able to have a model that produces as best results as possible.
What we learned
For all of us, this is our first time trying to use a machine learning model with a large dataset. We learned about different methods on how to yield a model with the highest prediction success rate.
What's next for Heart Attack Prevention
As the datathon comes to an end, we decided it would be better to find a different heart attack risk dataset, since the one that we had did not yield the results that we expected. I believe that a different dataset may have a more obvious correlation between the different factors of heart attack risk, and will be able to train a more accurate machine learning model for heart attack risk prediction.








Log in or sign up for Devpost to join the conversation.