-
-

Landing Page
-
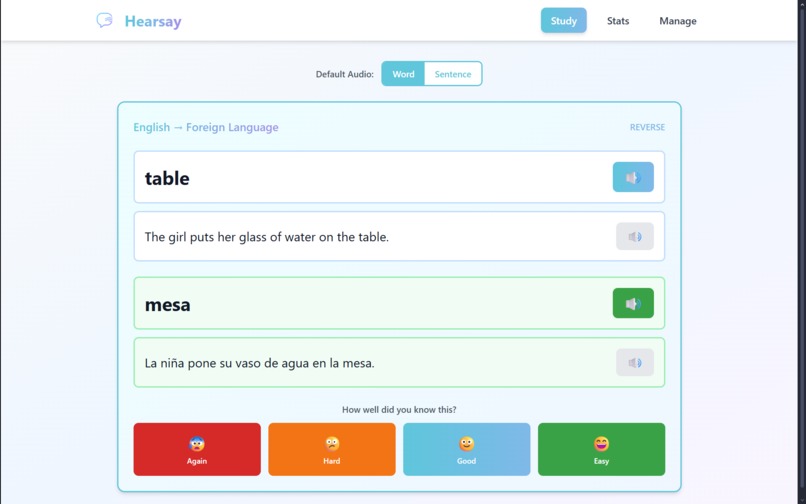
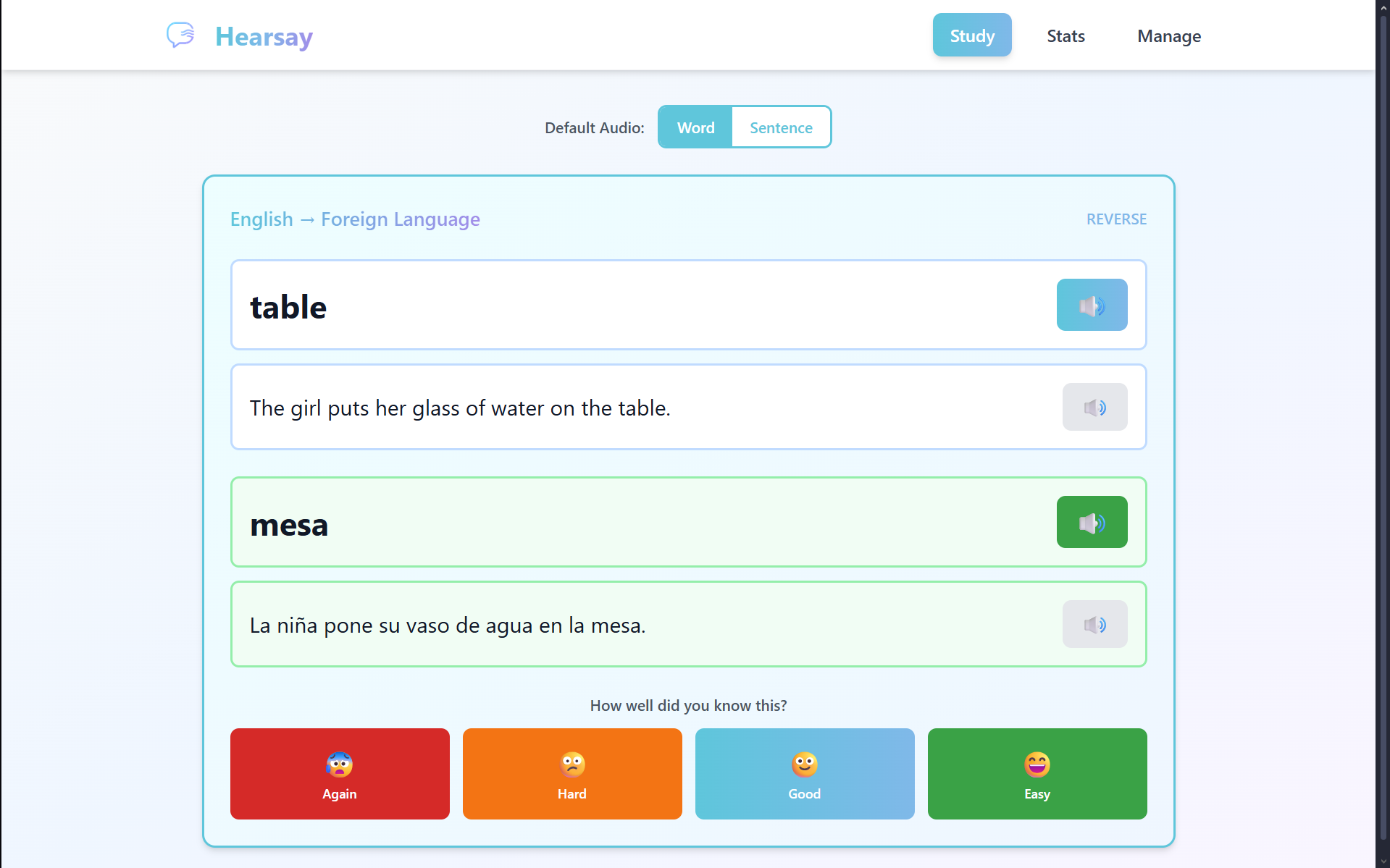
Study Page
-
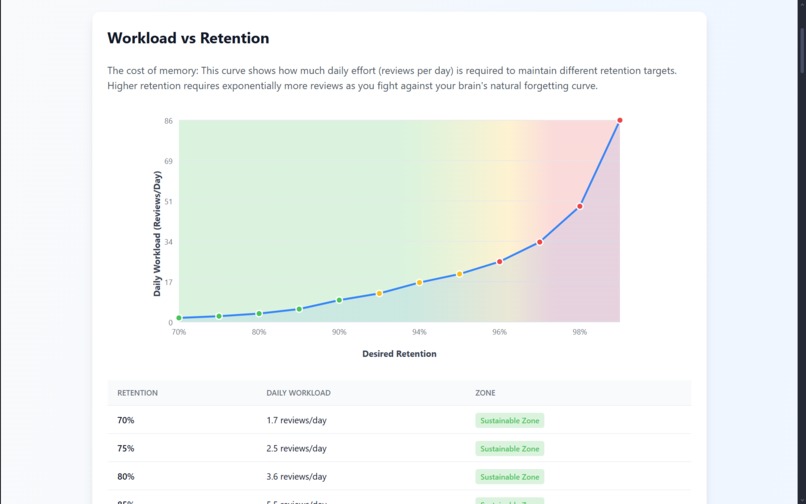
FSRS Stats
-
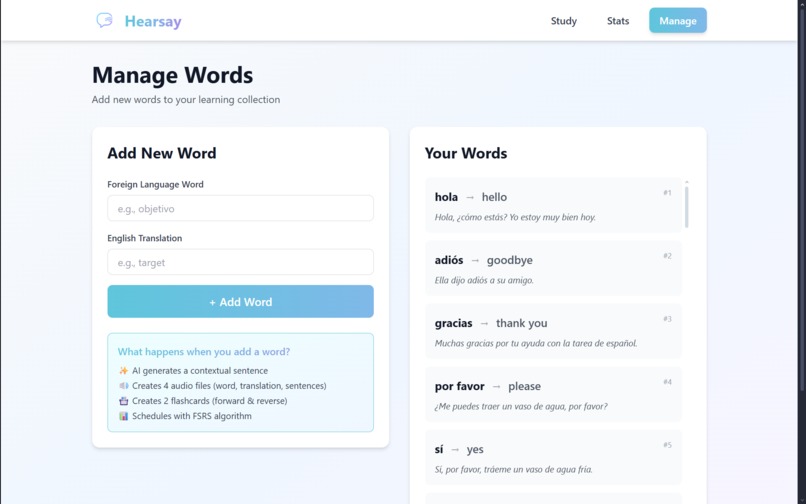
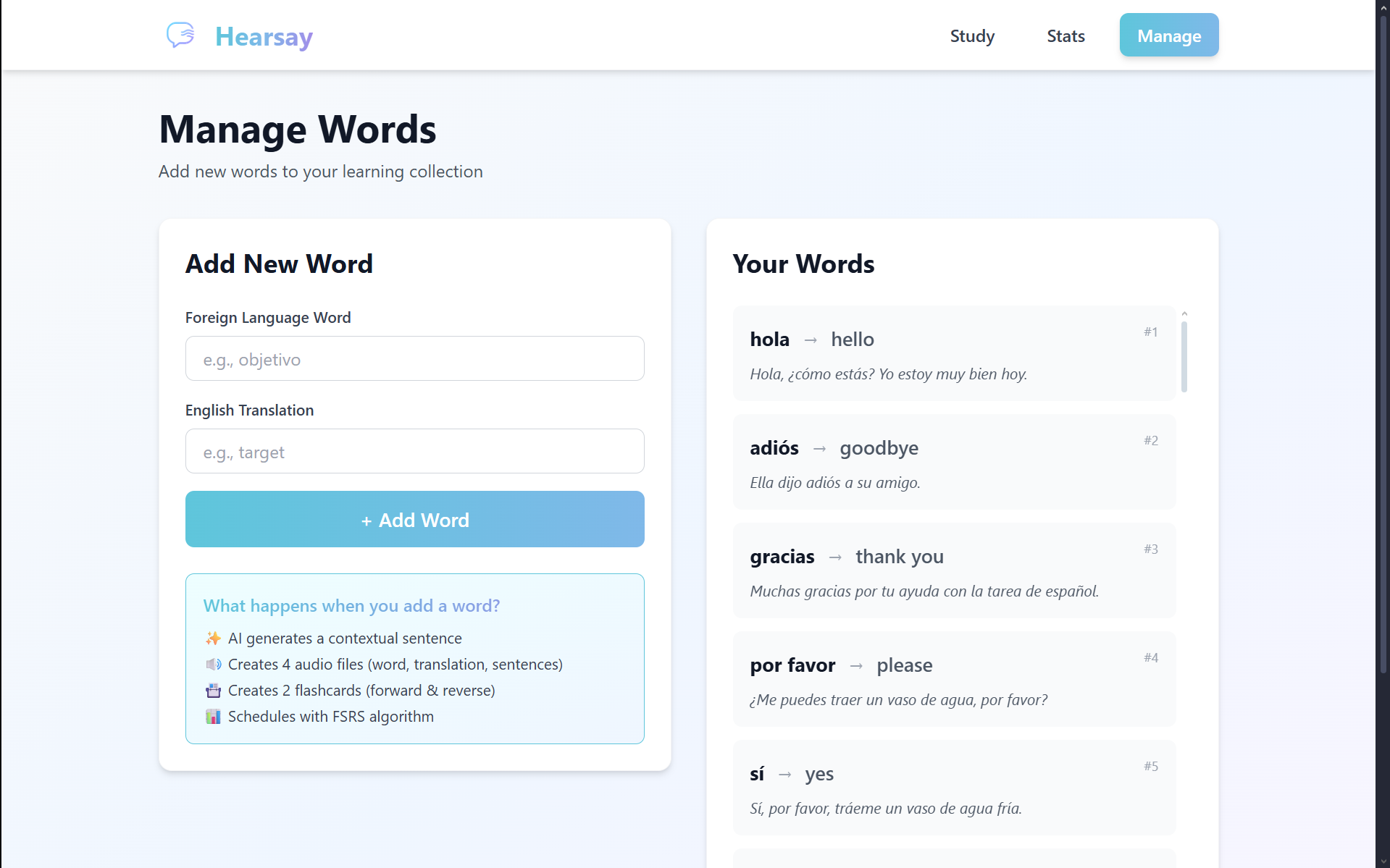
Manage Page
-

4 buttons input
-

2 sensors input



Inspiration
We come from a background of different languages, so we are language learning enthusiasts. However, we noticed some critical issues in current language learning apps, specifically around sentence mining: they don't provide context-based generation of flashcards, so surrounding words are often harder than target words. Additionally, they lack support for disabilities and require users to constantly look at a screen while using their phone or keyboard.
What it does
Hearsay solves these problems by creating an accessible, audio-first language learning platform. We provide alternative inputs like physical buttons and contactless gesture sensors, making it adapted for different movement disabilities. The app can be used audio-only, making it suitable for learners with visual impairments or those who prefer hands-free learning.
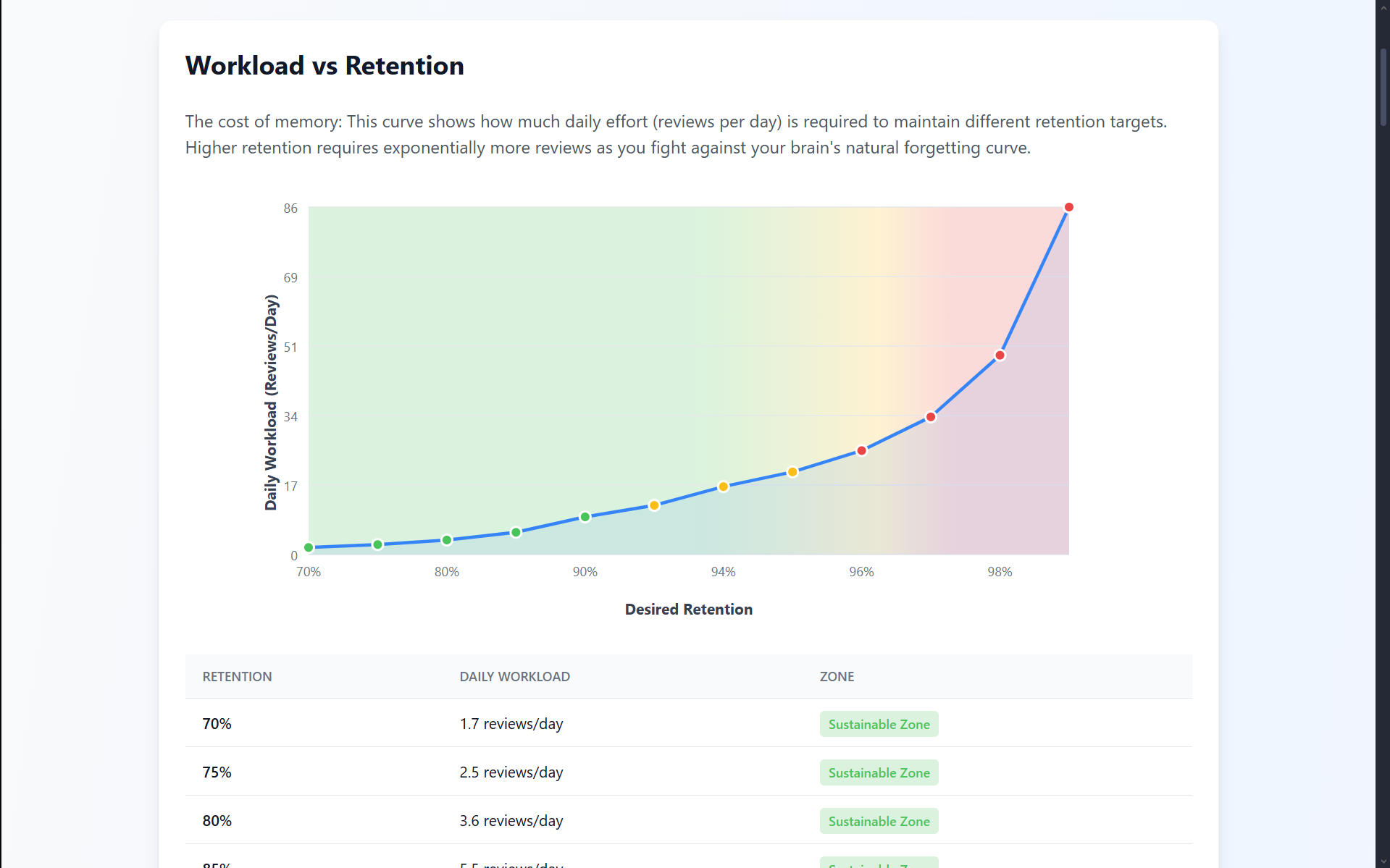
We implement FSRS (Free Spaced Repetition Scheduler), the state-of-the-art algorithm for spaced repetition with personalized optimization through parameter fine-tuning. The system uses AI-powered card generation via the Google Gemini API to create contextual sentences and ElevenLabs to produce human-like audio in multiple languages.
Furthermore, we designed a mastery metric that identifies the most "well-known" words in a user's vocabulary. We use these mastered words as context when generating new sentences, ensuring that surrounding words are never noise: the target word is always the focal point of learning.
How we built it
We architected Hearsay as three independent components:
Frontend (React + Vite + Tailwind CSS): We built a modern, responsive web interface with three core pages—Study, Manage, and Stats. The Study page features real-time audio playback and supports both traditional button clicks and hardware inputs. We implemented a polling system to detect hardware events and update the UI instantly.
Backend (FastAPI + Python): We created a RESTful API server that orchestrates all core functionality. We integrated the FSRS algorithm from the fsrs Python library to handle intelligent review scheduling with personalized parameters. For content generation, we connected to Google's Gemini 2.5 Flash model to create contextual sentences based on user mastery levels. Audio generation flows through ElevenLabs' multilingual TTS API, with MP3 files cached locally for performance. Data persistence uses a simple JSON-based database for portability.
Hardware (Arduino + Python Bridge): We programmed Arduino boards with two input modes: a 4-button configuration and contactless ultrasonic/gesture sensors. Each Arduino streams events over serial USB. Python bridge scripts (pyserial) listen to these serial ports and translate button presses or sensor triggers into HTTP requests to the backend's /hardware/input endpoint, completing the hardware-to-web loop.
The entire stack communicates via HTTP, making each component independently testable and deployable.
Challenges we ran into
Sending audio across backend and frontend proved more complex than anticipated; we had to balance between streaming audio in real-time versus caching MP3 files for offline reliability. We ultimately chose a hybrid approach where audio is generated on-demand but cached locally.
Hardware dependencies and configuring Arduino to interact with a FastAPI server required careful serial communication handling. We faced issues with port conflicts, especially when the Arduino IDE's Serial Monitor was open simultaneously with our Python bridge scripts.
Ensuring synchronization between hardware inputs and frontend state was challenging. We implemented a polling system where the frontend continuously checks for hardware events, which introduced latency considerations that we had to optimize.
Finally, making the FSRS algorithm work with personalized parameters while maintaining fast response times required some optimization of our scheduling logic.
Accomplishments that we're proud of
Everything worked out! We overcame all these challenges and achieved the final product we were hoping for:
- Built a fully functional hands-free language review system that runs smoothly across devices
- Designed an interface users can operate without a screen, enabling accessibility for all
- Successfully integrated controller-based input and AI-powered review scheduling
- Created a project that bridges language learning, accessibility, and technology
We learned a lot about hardware and human-computer interaction. We realized how challenging it is to build hardware that can meaningfully interact with people with disabilities, and how important audio-first design is for true accessibility.
What we learned
Throughout this project, we gained valuable insights:
- How to design around audio-first interactions and accessibility needs from the ground up
- How the FSRS algorithm personalizes learning through data-driven scheduling, and why it outperforms SM-2
- The value of simple, intuitive controls in reducing cognitive and physical effort for users
- How clear documentation and communication speed up development in fast-paced hackathon settings
- The complexity of hardware-software integration and real-time event handling across different interfaces
What's next for Hearsay
Consumer-oriented hardware: We're currently using Arduino prototypes, but we envision creating compact, durable, and aesthetically pleasing hardware specifically designed for this product: portable controllers optimized for language learning on the go.
Enhanced flashcard UI: The current interface could benefit from additional features like different deck organization, batch generation of cards, importing word lists, and more advanced card management options (flagging, burying, suspending) similar to Anki.
Expanded compatibility: Integrate Bluetooth and support for adaptive controllers to reach even more users.
Import tool: Allow users to upload CSV or text files with word lists, eliminating the need to type each word individually.
Broader accessibility: Continue refining the app's accessibility layer to support an even wider range of users, including those with cognitive disabilities and elderly learners.




Log in or sign up for Devpost to join the conversation.