Inspiration
Home security systems are expensive, intrusive, and often fail to adapt to real-world threats. Traditional systems rely on motion sensors and cameras—reactive tools that tell you something happened, but not what. We wanted to build a system that actually listens. Glass breaking, smoke alarms, screams—these sounds carry urgent information that gets lost in silence-focused security. As engineering students, we saw an opportunity to combine edge computing, machine learning, and modern AI to create something that feels less like a corporate security product and more like a genuinely intelligent guardian for the home.
What it does
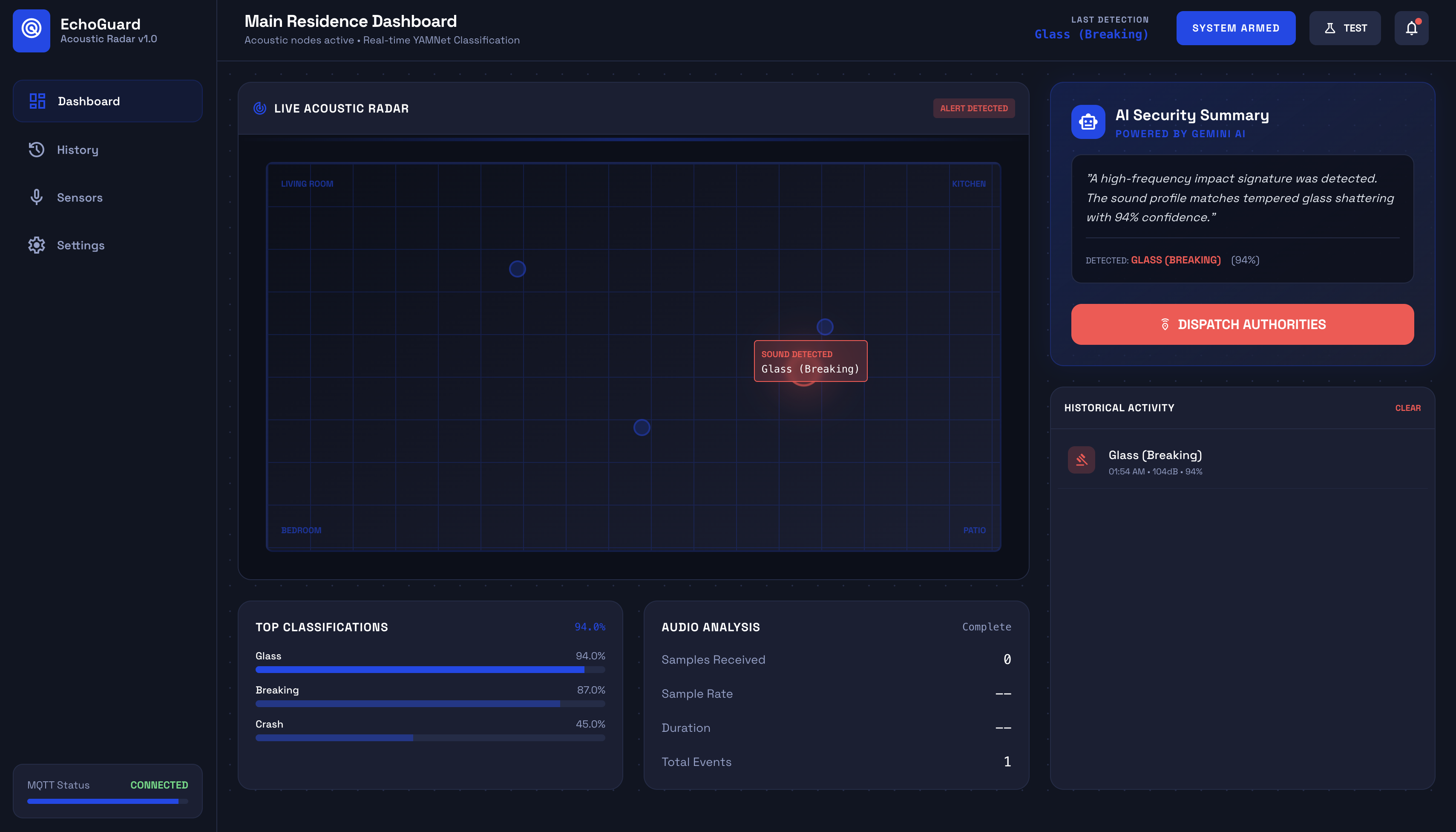
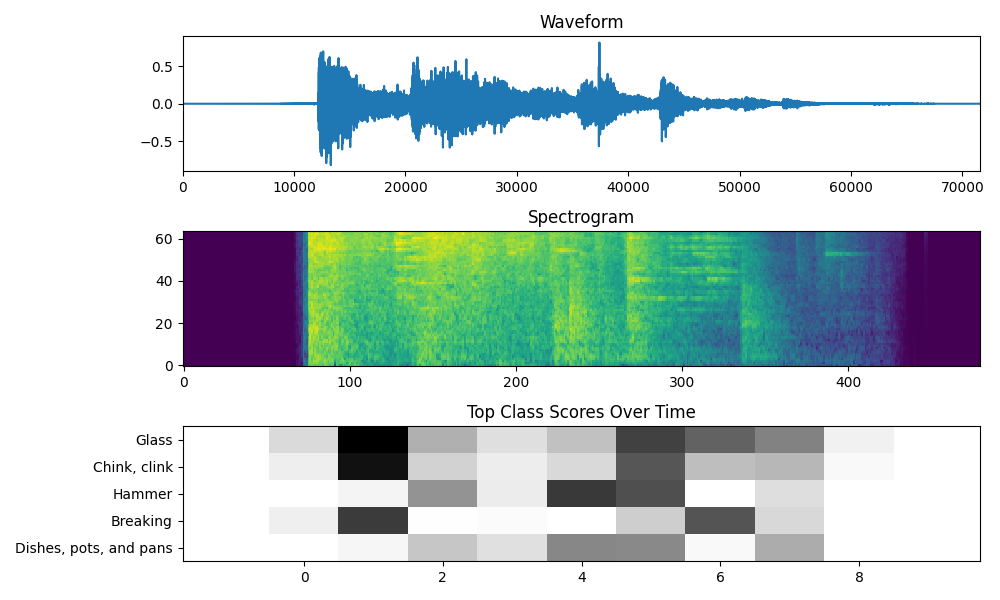
EchoGuard is a distributed acoustic threat detection system. A network of low-cost microcontrollers (ESP32 and STM32) captures audio throughout a home and streams it to a central server via MQTT. The server runs YAMNet, a 521-class audio classifier, to identify sounds in real-time—distinguishing glass shattering from a dropped plate, or a smoke alarm from a TV. When threats are detected, Gemini AI generates contextual analysis explaining what the sound likely means and what the homeowner should do. ElevenLabs then synthesizes a natural voice alert that plays through the dashboard, transforming raw classification into actionable, human communication. The web dashboard visualizes sensor locations, event history, and threat levels on a live map, giving users immediate situational awareness.
How we built it
We built edge nodes using ESP32 (PlatformIO) and STM32G4 (HAL/C) for audio capture and MQTT transmission. The server runs Flask with Flask-SocketIO for real-time WebSocket updates to the dashboard. YAMNet (via TensorFlow Hub) handles sound classification, processing 8-bit audio resampled to 16kHz. We integrated Google's Gemini API for threat analysis and ElevenLabs for text-to-speech alerts. The frontend uses Leaflet.js for the sensor map and vanilla JavaScript for real-time event rendering. MQTT (via Mosquitto) handles lightweight pub/sub messaging between nodes and server, chosen for its low overhead on constrained devices.
Challenges we ran into
Audio processing on resource-constrained microcontrollers was harder than expected. The STM32's ADC timing, DMA configuration, and sample rate consistency required significant debugging. We also struggled with 8-bit to float conversion and resampling artifacts that initially confused YAMNet. Balancing classification sensitivity was tricky—we needed to catch real threats without flooding users with false positives from ambient noise. Tuning the threat keyword mapping and confidence thresholds took multiple iterations to feel reliable.
Accomplishments that we're proud of
We built a complete end-to-end system: from microcontroller firmware capturing raw audio, through ML classification, to AI-generated voice alerts in the browser. The voice alerts feel genuinely useful—hearing "Glass breaking detected in the kitchen with 94% confidence. Consider checking the area immediately." is far more actionable than a generic beep. We're also proud of the real-time dashboard; watching events populate live as audio streams in makes the system feel alive and responsive.
What we learned
We gained deep appreciation for the complexity of audio ML pipelines. Sample rates, bit depths, and resampling all have massive impacts on classification accuracy. We also learned how powerful combining multiple AI services can be—YAMNet provides the "what," Gemini provides the "so what," and ElevenLabs makes it human. The MQTT pub/sub pattern proved ideal for IoT, letting us add nodes without changing server code.
What's next for EchoGuard
We want to implement acoustic triangulation using time-difference-of-arrival (TDOA) across multiple nodes to pinpoint exactly where in a home a sound originated. We'd also like to add on-device classification using TensorFlow Lite on the ESP32 to reduce latency and enable offline detection. Finally, a mobile app with push notifications would make the system practical for everyday use.

Log in or sign up for Devpost to join the conversation.