-
-

Landing Page
-

Live Transcription
-

Circuit
-
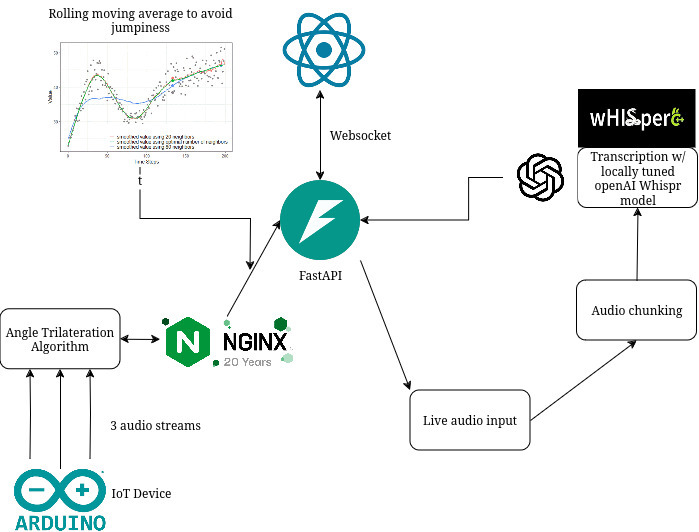
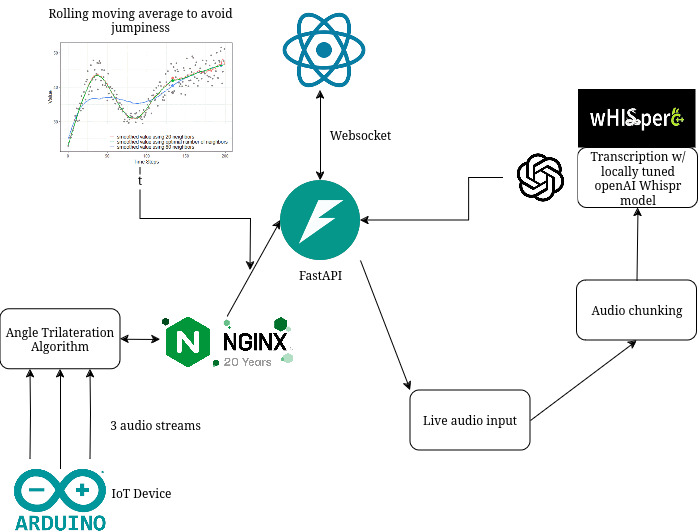
Project Architecture
-





Inspiration
The inspiration for Tritone came from the desire to improve accessibility for individuals with hearing impairments. We aimed to create an IoT system that not only amplifies sound but also intelligently processes and visualizes audio, enabling users to focus on specific sounds in their environment, whether nearby or at a distance.
What it does
Our solution is an IoT system that:
- Allows users to toggle between Nearby Mode (for focusing on sounds close to the user) and Long-Distance Mode (for amplifying distant sounds).
- Captures audio through three embedded microphones or, as a fallback, through computer microphones.
- Calculates the angle of an audio source relative to the microphone setup using trilateration.
- Streams audio data in real-time, processes it to isolate key sounds, and provides live transcription.
- Displays an audio visualizer interface to help users understand the direction of voices in their environment along with what is being said.
How we built it
1. Embedded System:
We designed a circuit with an ESP32 microcontroller, integrating three microphones with bias resistance and coupling capacitance. Then, we used a low-pass filter and ADC pins to capture sound data. Lastly, we transmitted processed audio data over WebSocket connections to the backend for further processing.
2. Backend:
We developed a server capable of handling audio data streams via WebSockets. Next, we processed audio streams for triangulation, transcription, and visualization.
3. Frontend:
Our focus to be ADA compliant and the user led us to build a user-friendly landing page. Here, users can toggle between Nearby and Long-Distance Modes. Furthermore, we also integrated an audio visualizer component to represent sound directionality and intensity in real-time.
4. Fallback System:
We implemented computer microphones to act as a backup when embedded microphone quality was suboptimal. To accomplish this, we use Python scripts to stream audio from computer microphones to the backend, where it was processed and transcribed.
Challenges we ran into
1. WebSocket Networking Constraints:
Running WebSocket connections over a local area network was challenging due to UTD firewall restrictions. As it goes, debugging connectivity issues between embedded devices and the backend required significant time.
2. Embedded Microphone Quality:
The ESP32's onboard ADC pins and connected microphones produced inconsistent data due to noise and sensitivity issues. We somewhat resolved this by integrating computer microphones as a fallback solution for capturing high-quality audio.
3. Real-Time Audio Processing:
Ensuring low latency while streaming, processing, and transcribing audio was complex, especially with varying network conditions.
4. UI Visualization:
Creating a real-time audio visualizer that accurately represents sound directionality and intensity required careful integration of backend data with frontend components.
Accomplishments that we're proud of
- Successfully integrating embedded hardware, backend processing, and frontend visualization into a full stack web application.
- Building a fallback mechanism with computer microphones. This ensured the system's reliability despite challenges with embedded hardware.
- Developing a user-friendly interface that allows for visualizing sound directionality in real time.
- Implementing real-time transcription and sound trilateration with very little delay.
What we learned
- The importance of having fallback mechanisms, especially when dealing with hardware that does not meet expectations.
- Challenges in real-time audio processing, especially over WebSocket connections with varying network conditions.
- How to integrate embedded systems with web technologies for seamless data transmission and visualization.
What's next for Tritone
We initially wanted to be able to display and transcribe multiple speakers at once, but weren’t able to implement this due to time constraints. We also want to upgrade our microphones and implement better signal processing techniques for noise reduction and higher accuracy, along with utilizing ML algorithms to isolate speech from background noise.




Log in or sign up for Devpost to join the conversation.