-
-
flow presentation: 1aAFu5Dy_EAYc5FeU4liAD0xJowNiPn9r
-
alternative presentation 1VaowjqT1OTlIBzmztW5p4wNgXzSOuWaa
InnrSingr — Hear Yourself Sing Any Song with AI Voice Cloning
Inspiration
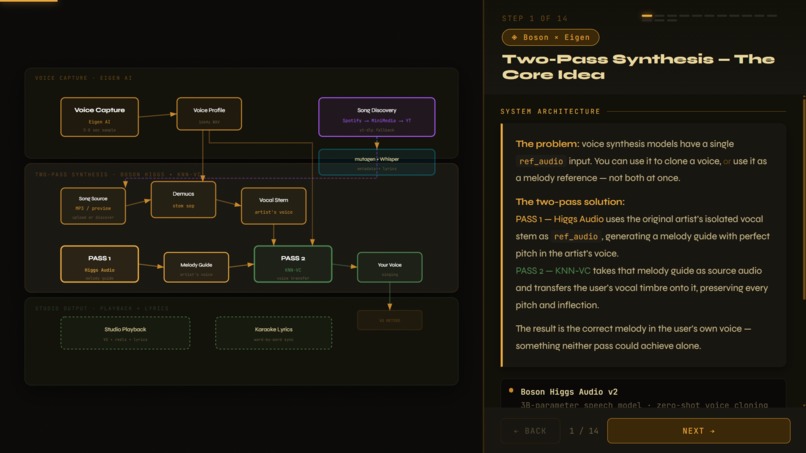
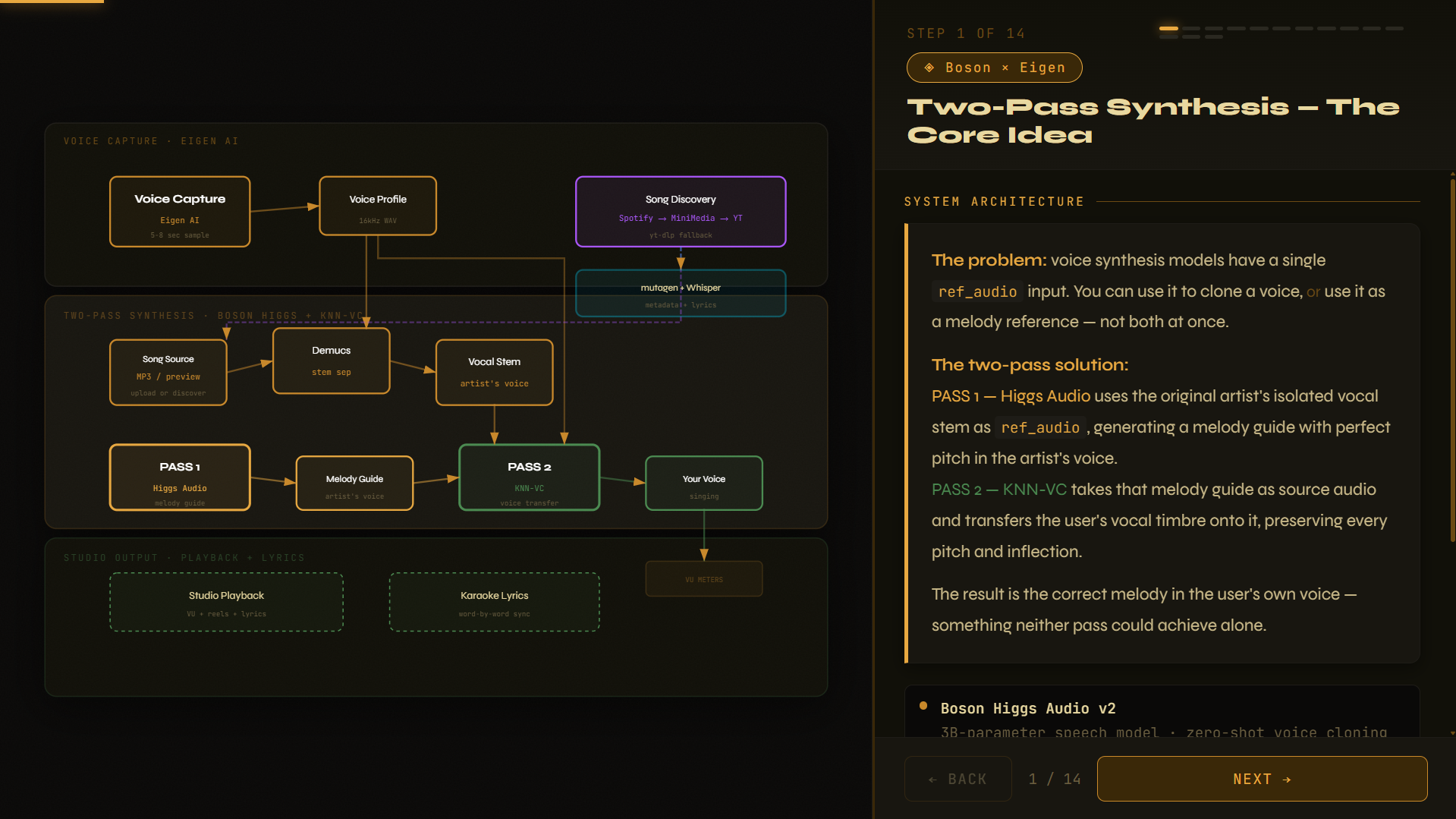
We wanted to experience the impossible: hearing our own voices sing songs we love, with perfect pitch and emotion. Existing tools could clone voice OR follow a melody — but never both. The moment we realized Higgs Audio could generate singing but had no knowledge of actual song melodies, while KNN-VC could transfer timbre but couldn't create the melody itself, we knew the answer was a two‑pass pipeline. That insight, combined with Boson’s powerful audio models and Eigen’s conversational intelligence, became the foundation of InnrSingr.
What it does
InnrSingr lets users hear their own voice singing any song. Speak 5‑8 seconds naturally to capture your voice, then either upload an MP3 or simply say "Find Sweet Caroline." The system discovers the song, downloads a preview, transcribes lyrics with word‑level timing, extracts the vocal stem, then runs two‑pass synthesis: Pass 1 uses Boson Higgs Audio with the vocal stem as reference to generate a perfect melody guide (the original artist’s voice). Pass 2 uses KNN‑VC to transfer your vocal timbre onto that melody guide. The result is your voice, singing the actual song, with real‑time studio visuals—VU meters, spinning tape reels, and karaoke lyrics—all orchestrated by Eigen AI in a natural conversation. No buttons, no scripts—just talk.
How we built it
We built InnrSingr as a multi‑service architecture:
- Eigen AI serves as the conversational agent, handling voice capture, tool orchestration, and the coaching loop. The agent decides when to call
capture_voice,discover_and_prepare_song,generate_melody, andconvert_voice. - Boson Higgs Audio powers Pass 1. With the isolated vocal stem (via Demucs) as
ref_audio, Higgs generates a WAV of the original artist singing the song with precise pitch. - KNN‑VC (via torch.hub) powers Pass 2, converting that melody guide to sound like the user’s speaking voice while preserving every inflection.
- Mutagen extracts metadata (title, artist, BPM, genre) from uploaded MP3s without decoding waveforms.
- Whisper‑timestamped transcribes lyrics with millisecond‑accurate word timestamps for karaoke sync.
- MiniMediaMetadataAPI (self‑hosted Docker) provides song discovery with Spotify/Deezer preview URLs.
- yt‑dlp serves as a final fallback when no preview is available.
The frontend is a recording‑studio interface with real‑time VU meters (ballistic smoothing), spinning reels that indicate processing stages, and a lyrics display that highlights words in sync with playback.
Challenges we ran into
The
ref_audiolimitation — Higgs can only take one audio reference. If we used the user’s voice, we lost the melody; if we used the vocal stem, we lost the user’s timbre. The two‑pass design was the breakthrough.Blocking the event loop — Higgs and KNN‑VC each take 10‑30 seconds. Running them directly inside async handlers froze the entire server. Wrapping them in
run_in_executor()with thread pools solved it.Audio format detection — Eigen could send int16 or float32 PCM; the wrong assumption crashed voice capture. We added automatic detection by checking byte length and value ranges.
Word‑level lyrics sync — Whisper returns segment timestamps, not word timestamps. We used
whisper‑timestampedfor word‑level output, then distributed words evenly across segment durations with a 500ms cap to prevent sync drift.Song discovery without commercial APIs — We built a fallback chain: Spotify (if token provided) → MiniMediaMetadataAPI (self‑hosted) → MusicBrainz (metadata only) → YouTube (yt‑dlp). This keeps the system functional even without paid services.
Thread‑safe singletons — Higgs, KNN‑VC, and the song database each need to load once. Using a single lock caused blocking; we gave each its own lock with double‑checked locking.
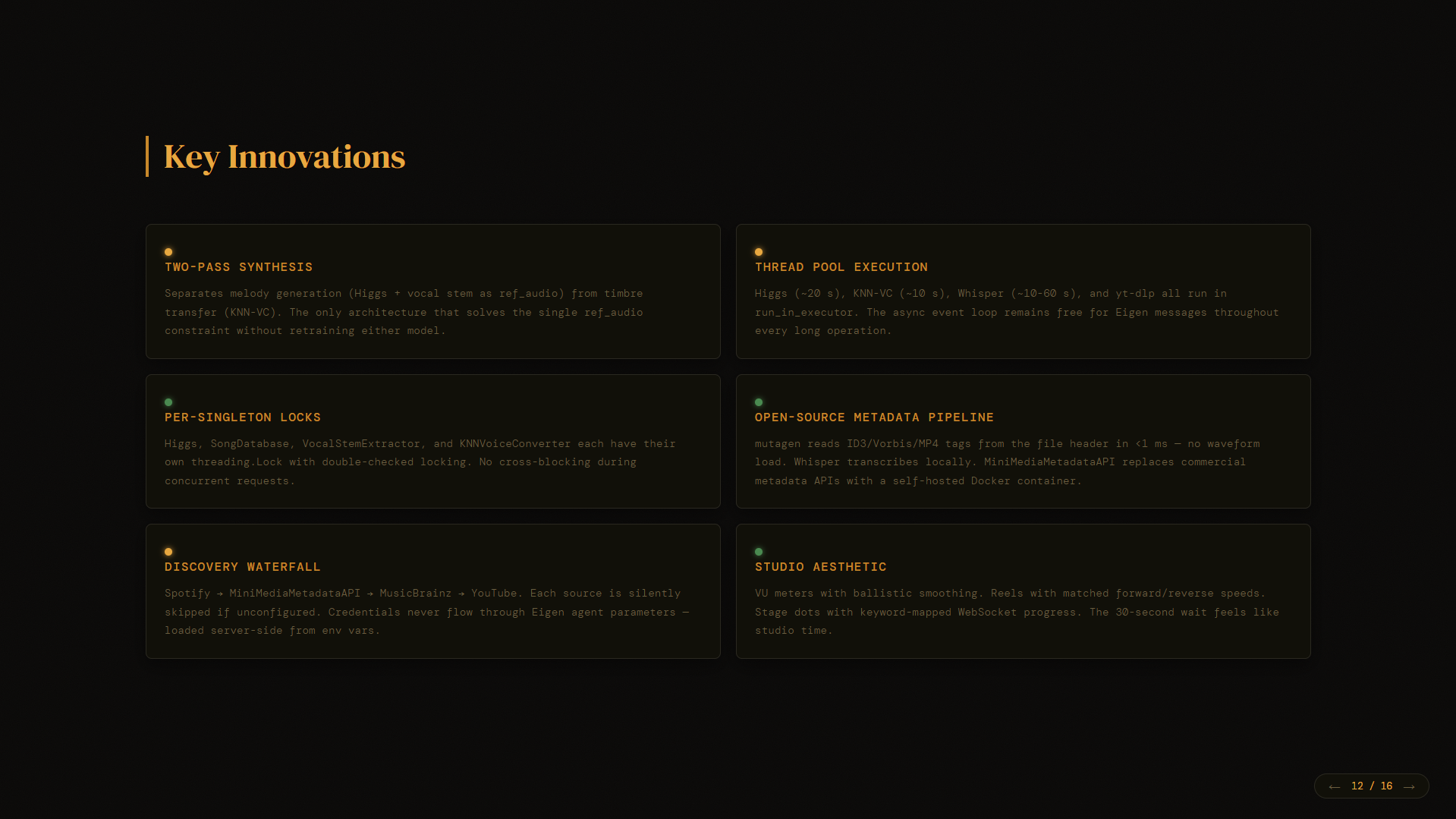
Accomplishments that we're proud of
Two‑pass synthesis that actually works — The first time we heard a user’s voice singing Sweet Caroline with the correct “Caro‑LINE” pitch, the room went silent. Then everyone smiled.
Fully conversational experience — Users never touch a button. They speak, Eigen talks back, and the pipeline runs. The coaching loop (“a bit higher,” “softer”) is natural dialogue.
21 bugs fixed — From float32 detection to
_use_fallbackrestoration to XSS in error messages. Every fix is documented.Open‑source discovery stack — The system can run entirely offline (except Spotify) using MusicBrainz, MiniMediaMetadataAPI, and yt‑dlp.
Studio‑grade UI — VU meters with ballistic smoothing (fast attack, slow decay), spinning tape reels that change speed by stage, and karaoke lyrics that auto‑scroll keep users engaged during the 60‑90 second wait.
Mutagen integration — We now read ID3 tags from MP3s in <1ms without loading the waveform. Title, artist, BPM, and genre are auto‑populated.
What we learned
AI models have hidden limitations — No single model can both clone voice and follow a melody. Sometimes the right architecture is two models working together.
Event loops require care — Any synchronous CPU‑bound call in an async handler blocks everything. Thread pools and executors are essential.
Conversational agents need structured tools — Eigen’s tool system forces clean separation between “what the agent decides” and “what actually runs.” This made the pipeline maintainable.
Open source is not a single toolchain — We combined Mutagen (GPL), Whisper (MIT), Demucs (MIT), KNN‑VC (MIT), and MiniMediaMetadataAPI (MIT). Each solved one piece, and together they replaced expensive commercial APIs.
User experience hides complexity — The 60‑90 second wait is invisible when users watch VU meters bounce, reels spin, and stage dots advance. Studio aesthetic turns processing time into performance.
What's next for InnrSingr
Song database expansion — Integrate with Jellyfin/Subsonic for personal music libraries so users can sing from their own collection.
Real‑time pitch correction — Use
torchaudioto analyze the generated singing and offer live feedback (“try holding that note longer”).Multilingual support — Whisper already supports 100+ languages. We’ll add song discovery for non‑English tracks.
Mobile companion — A simplified version where users hum a melody and the system finds the song (tunebot style).
Voice‑to‑voice duets — Allow two users to record separately and generate a duet with both voices.
Export to DAW — Generate multitrack stems (vocals, harmony) for users to import into Logic Pro, Ableton, or GarageBand.
Carbon‑aware scheduling — Defer heavy jobs (stem separation, Higgs) to times when the grid is cleanest, using ElectricityMaps.
Built With
- eigen-agent
- higgs-audio-v2
- higgs-tokenizer

Log in or sign up for Devpost to join the conversation.