




## Inspiration
Mental health support often feels clinical and intimidating. We wanted to create something that meets people where they are - through music. The idea: what if you could tell your story and hear it back as a song? Music therapy is clinically proven to not only reduce anxiety and depression, but many more mental health issues, however access is limited. We built Hear Me Out to make it creative, personal, and available to anyone with a browser!
## What it does
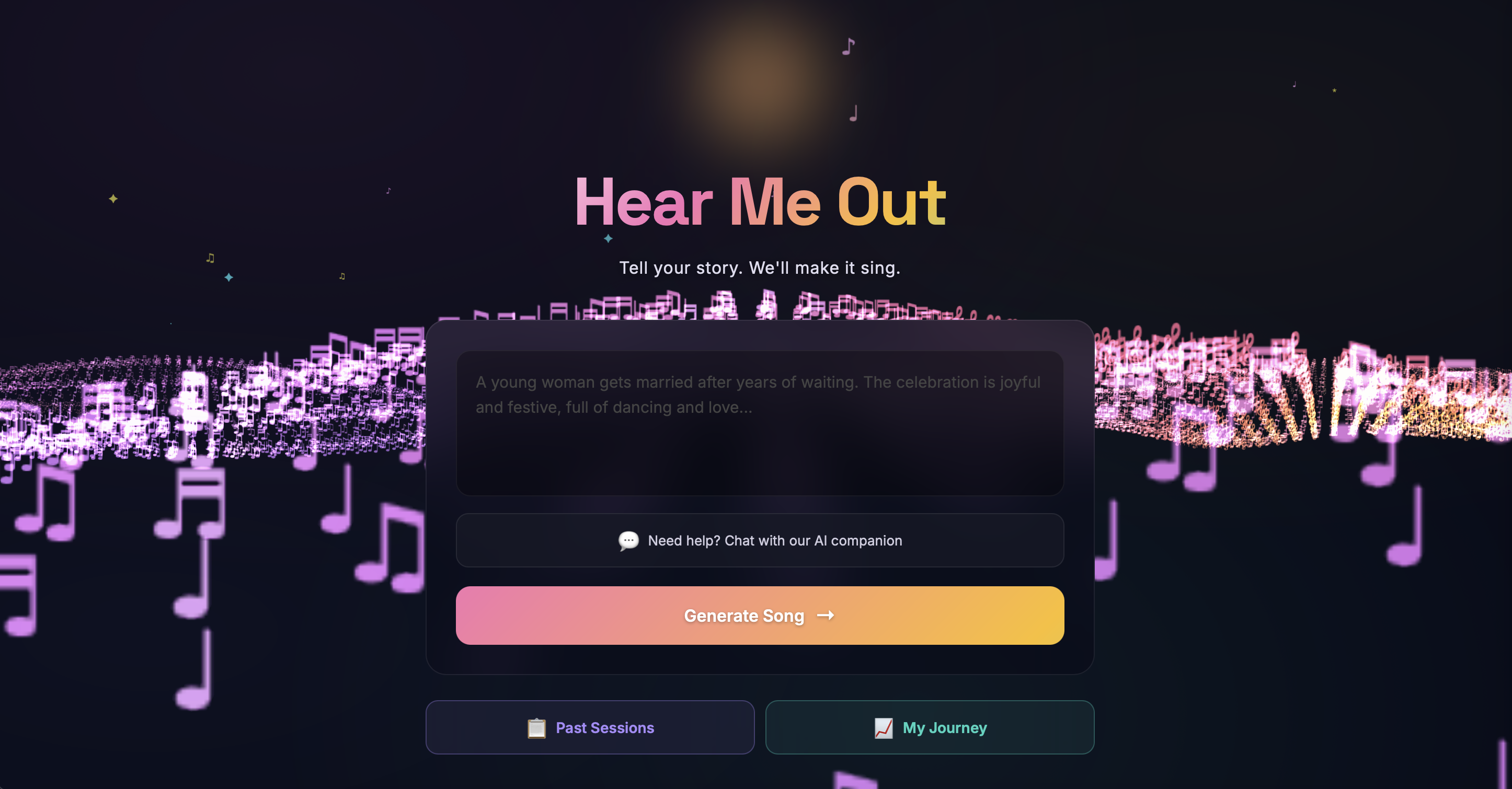
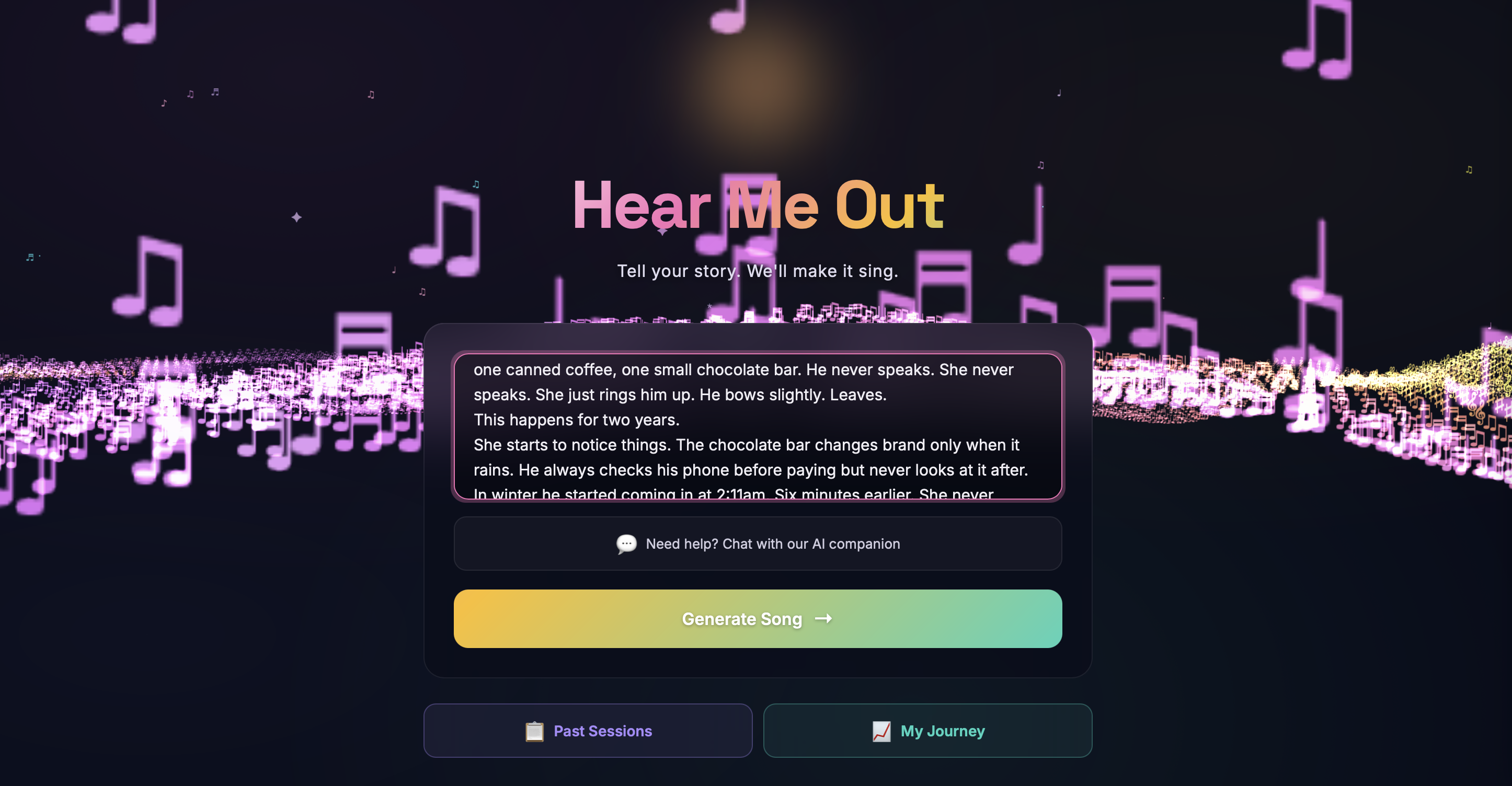
Hear Me Out is an AI music therapy web app that transforms emotional stories into personalized songs.
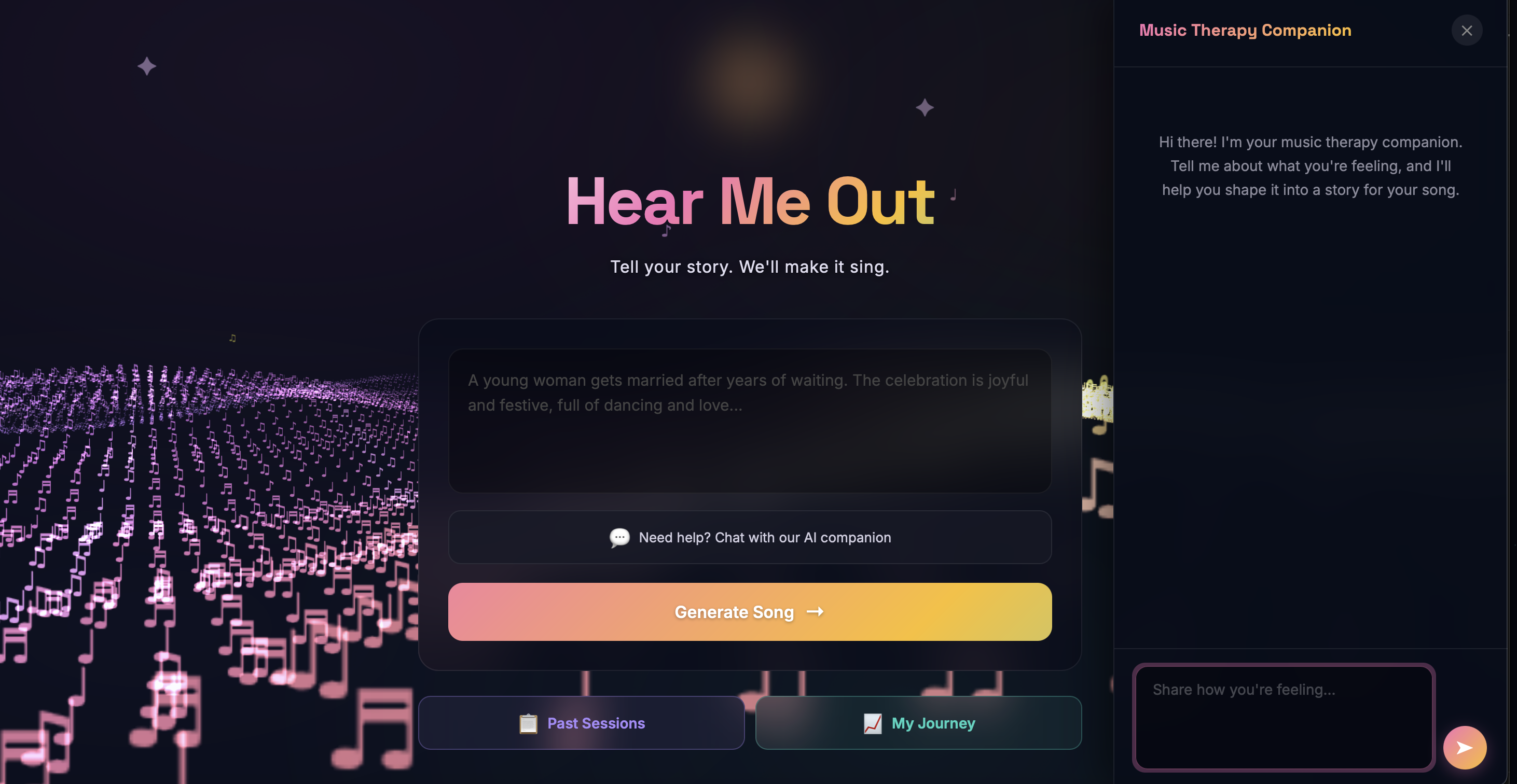
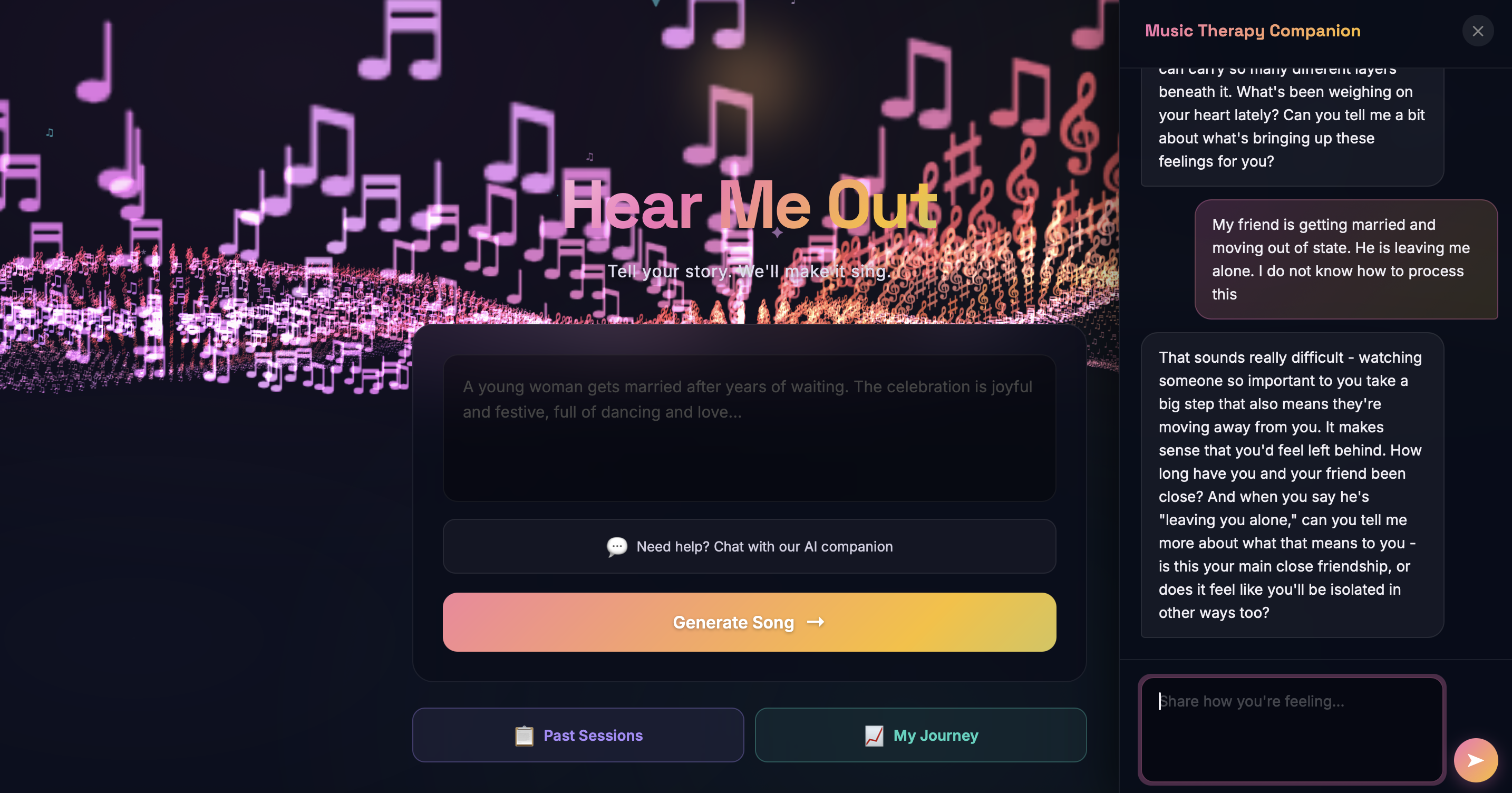
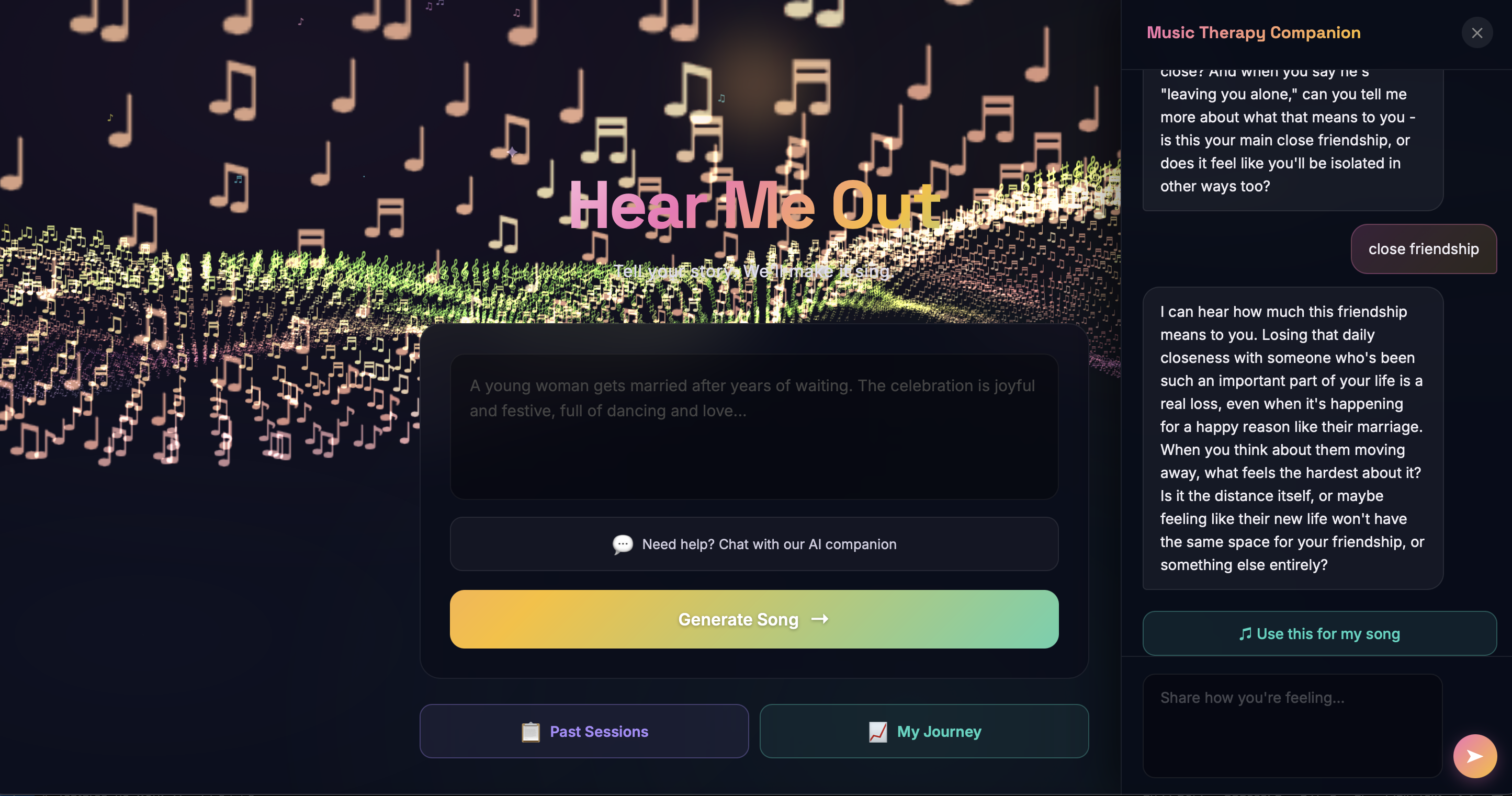
AI Companion Chatbot - A Claude-powered therapeutic chatbot that guides users through emotional exploration in a conversational flow. After appropriate exchanges, it synthesizes the conversation into a structured story summary and emotional profile that becomes the song generation prompt. The system also runs real-time crisis detection - if suicidal ideation or self-harm language is detected, an immediate full-screen intervention pop-up appears with the 988 Suicide & Crisis Lifeline and international resources, prioritizing user safety above all else.
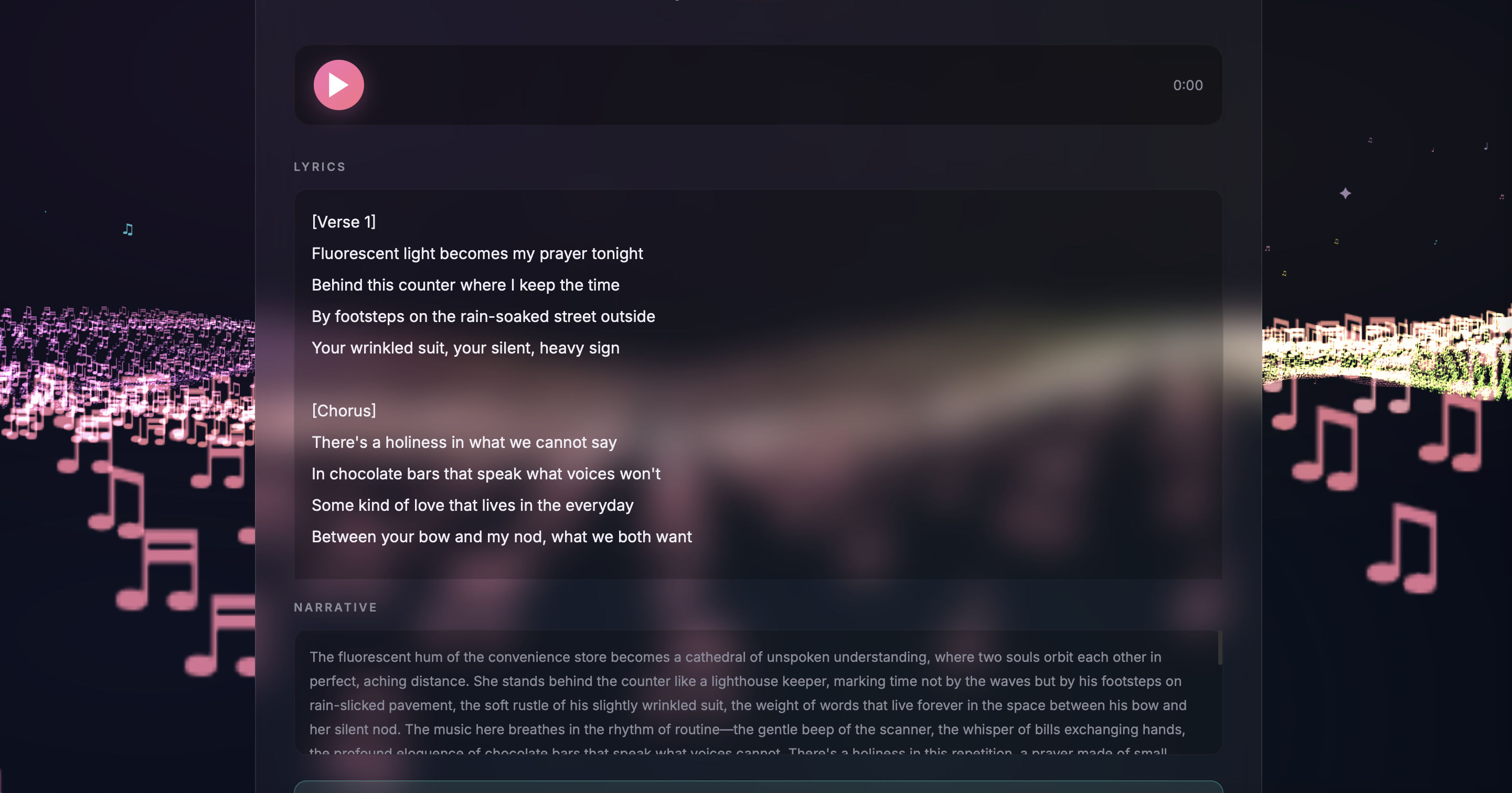
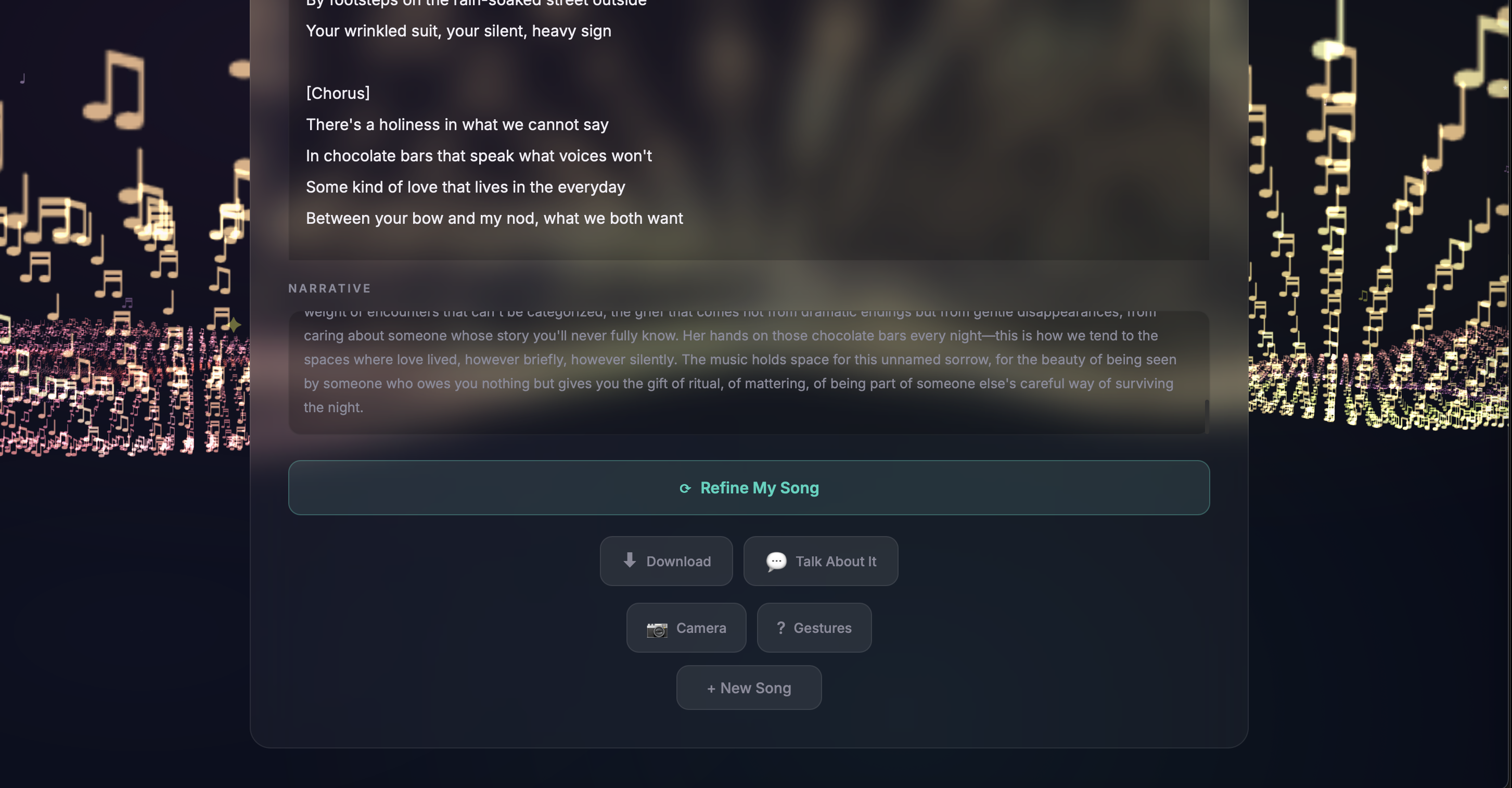
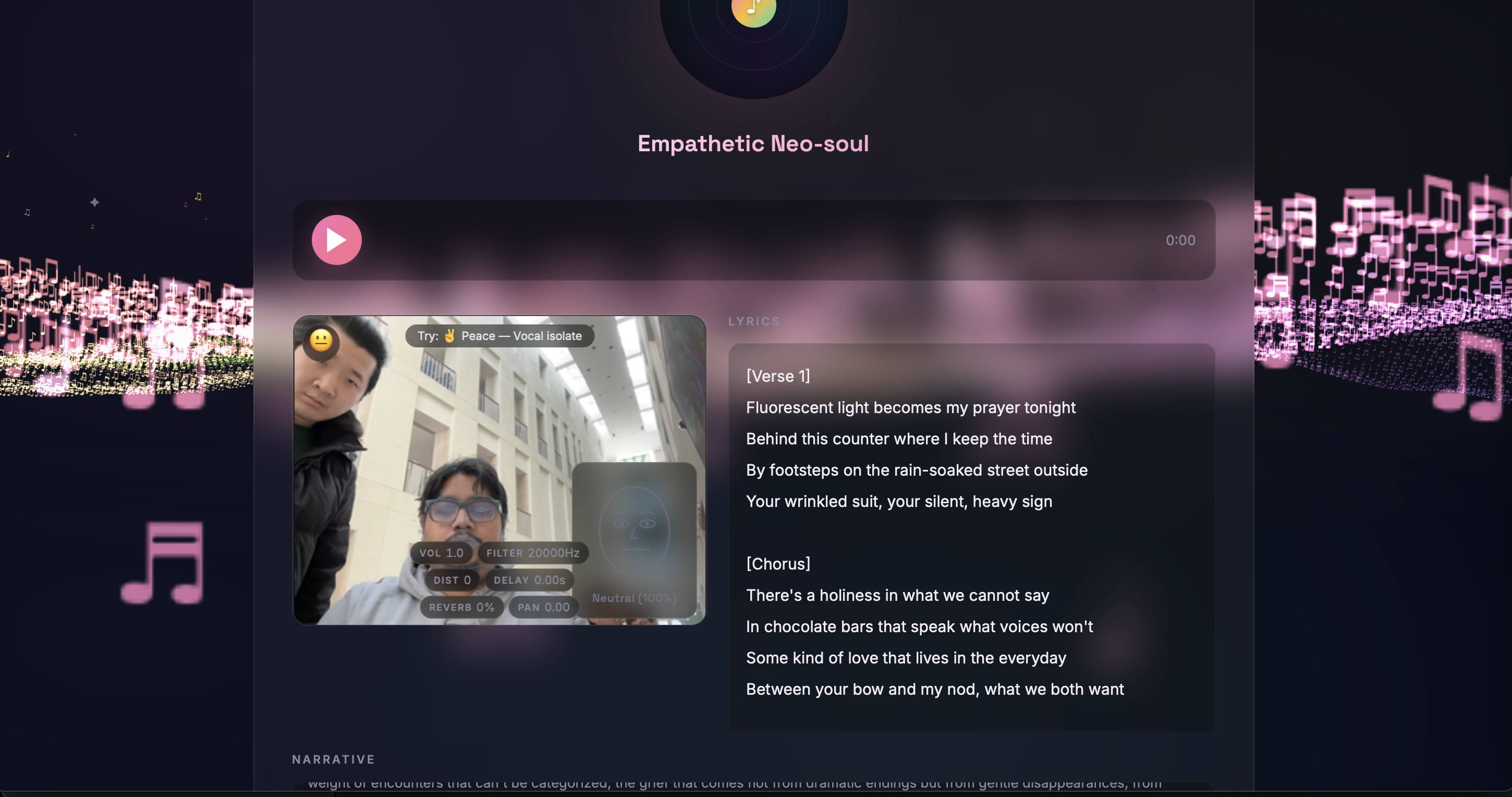
Personalized Song Generation - Stories pass through a multi-stage AI pipeline: Claude analyzes the emotional narrative and generates a detailed music prompt capturing mood, tempo, and themes. This feeds into an iterative generation loop producing lyrics, instrumentation, and vocal synthesis via ElevenLabs API. Users can listen, refine with different emotional angles, and download their personalized song.
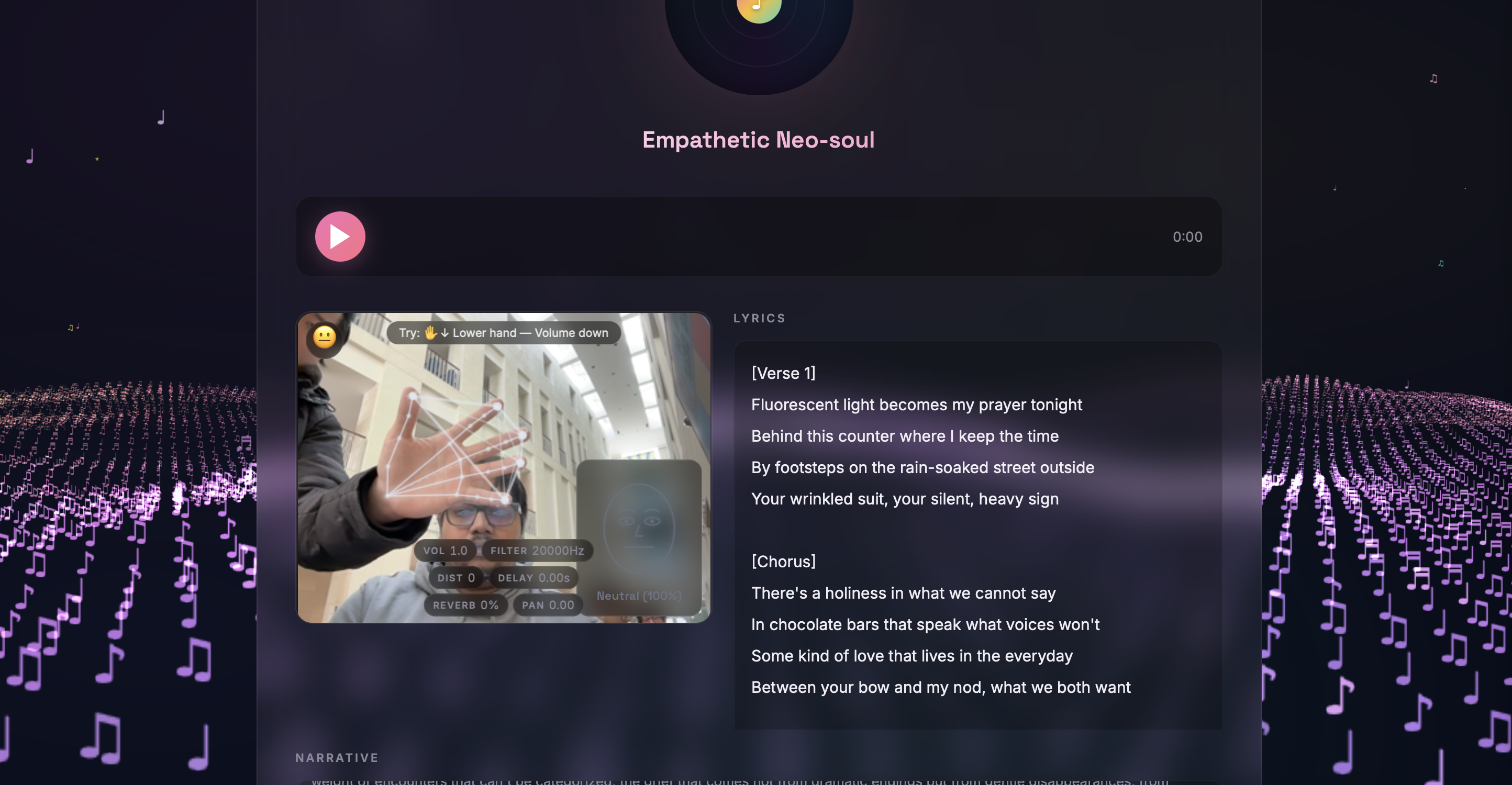
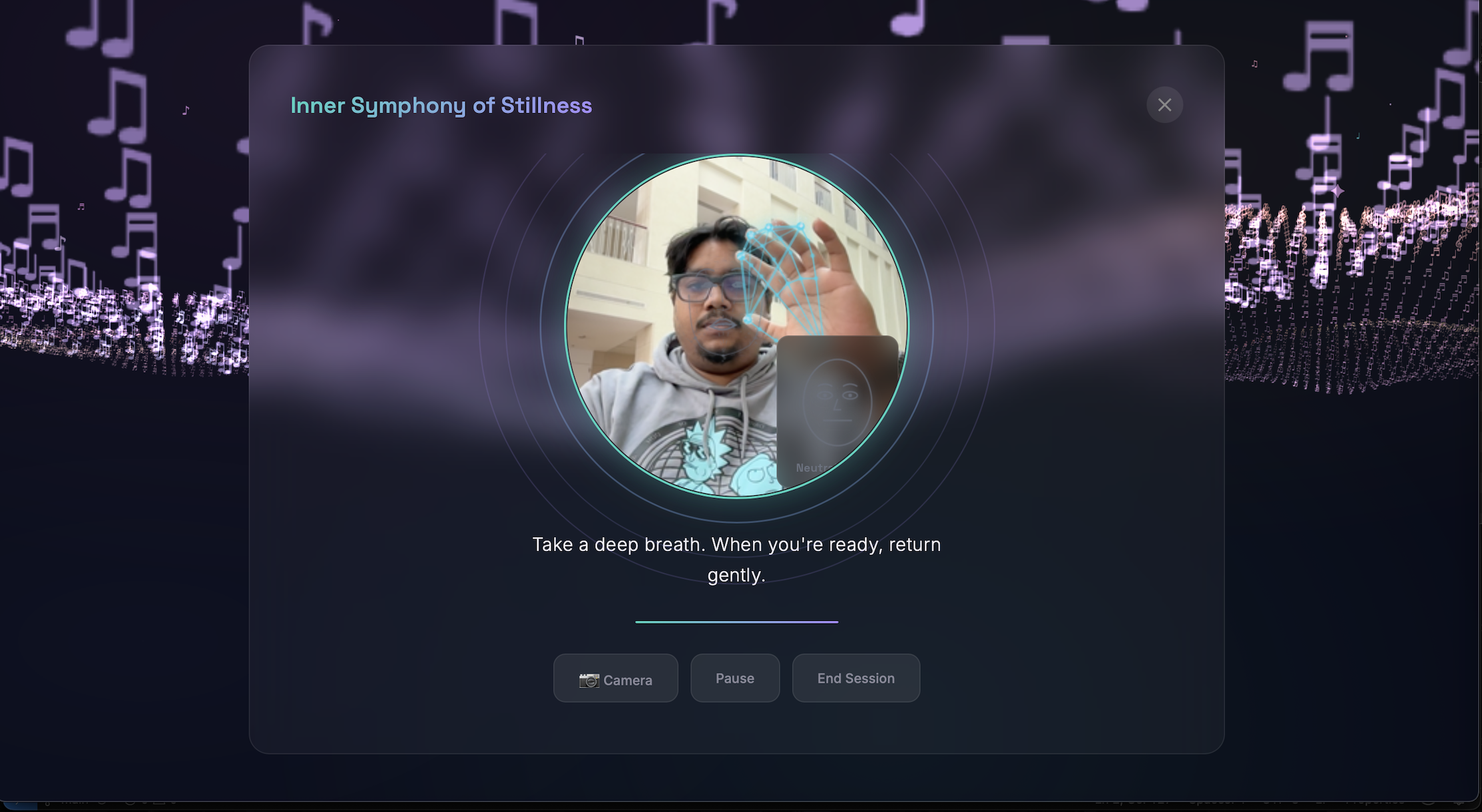
Hand Gesture Audio Controls - MediaPipe hand landmark detection through the webcam enables real-time audio manipulation via the Web Audio API effect chain. Hand height maps to continuous volume control. Peace sign activates a filter sweep, fist engages distortion, OK sign adds reverb, open palm triggers a mastered preset. All gestures work simultaneously - volume stays responsive while any effect is active. Beyond audio, a two-handed heart gesture spawns floating heart particles and a DBZ-style energy charge launches fireballs across the 3D landscape - expressive, playful actions that give users a sense of control over their environment and serve as creative emotional venting points, turning physical expression into visual catharsis.
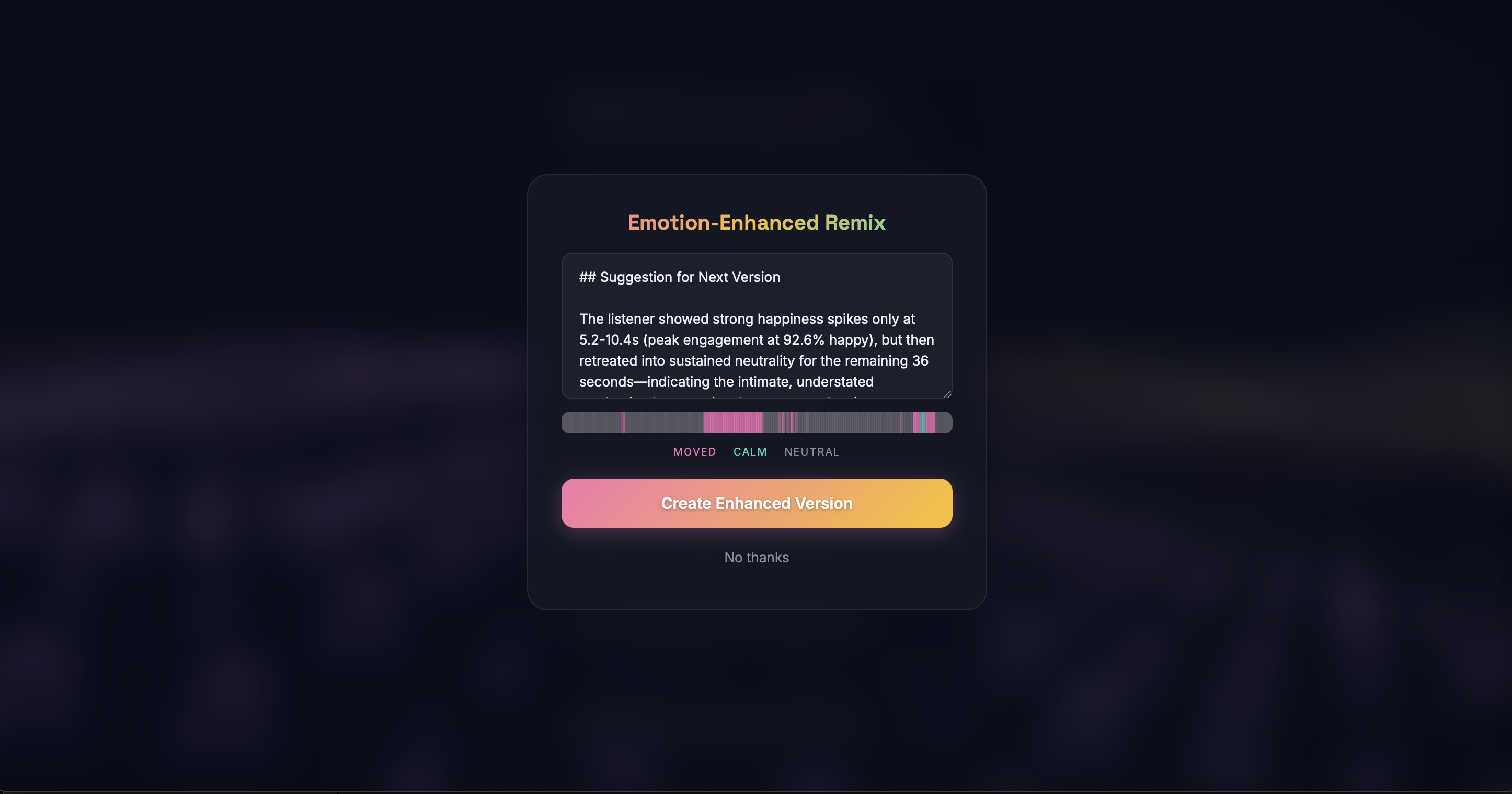
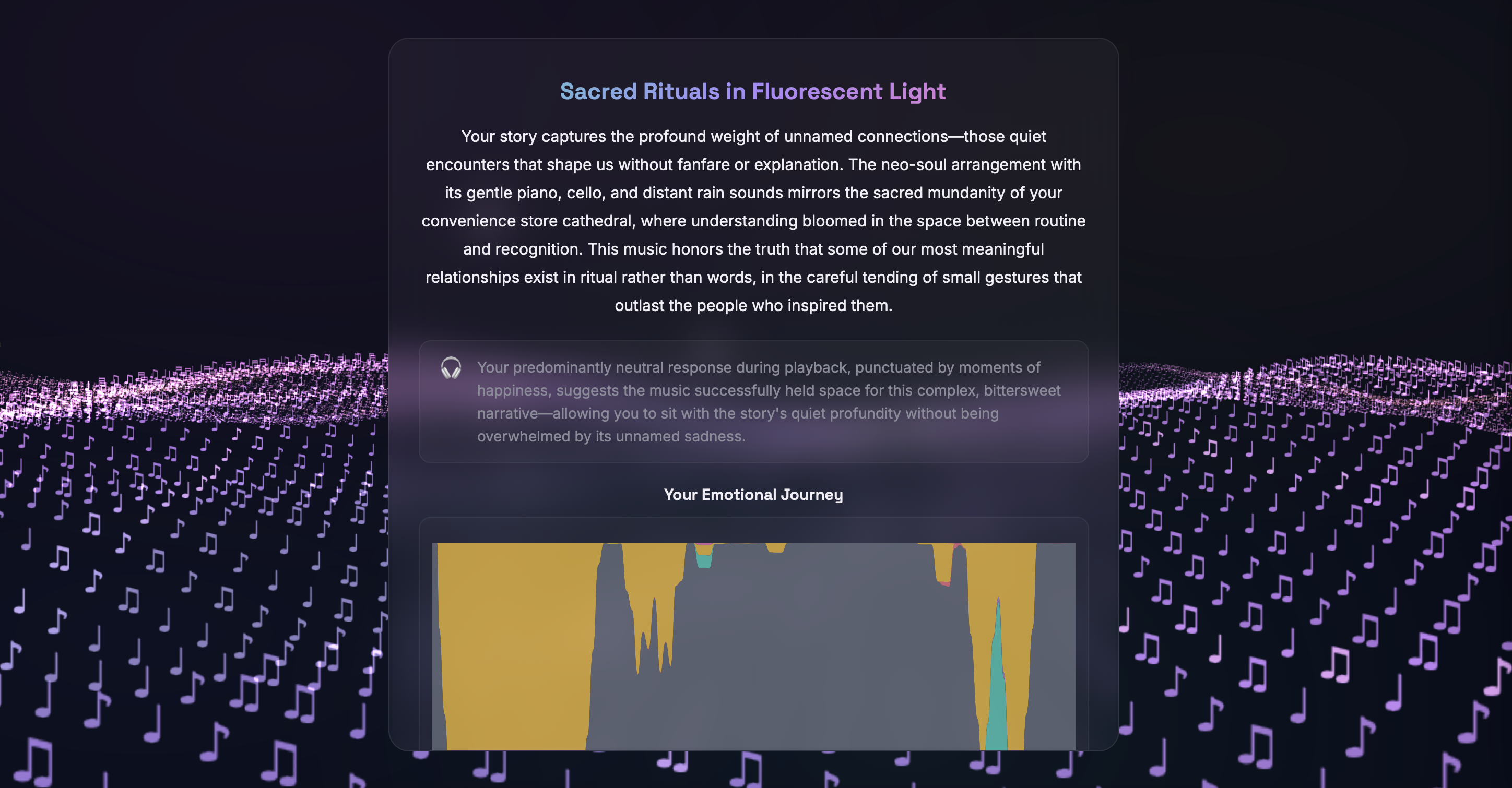
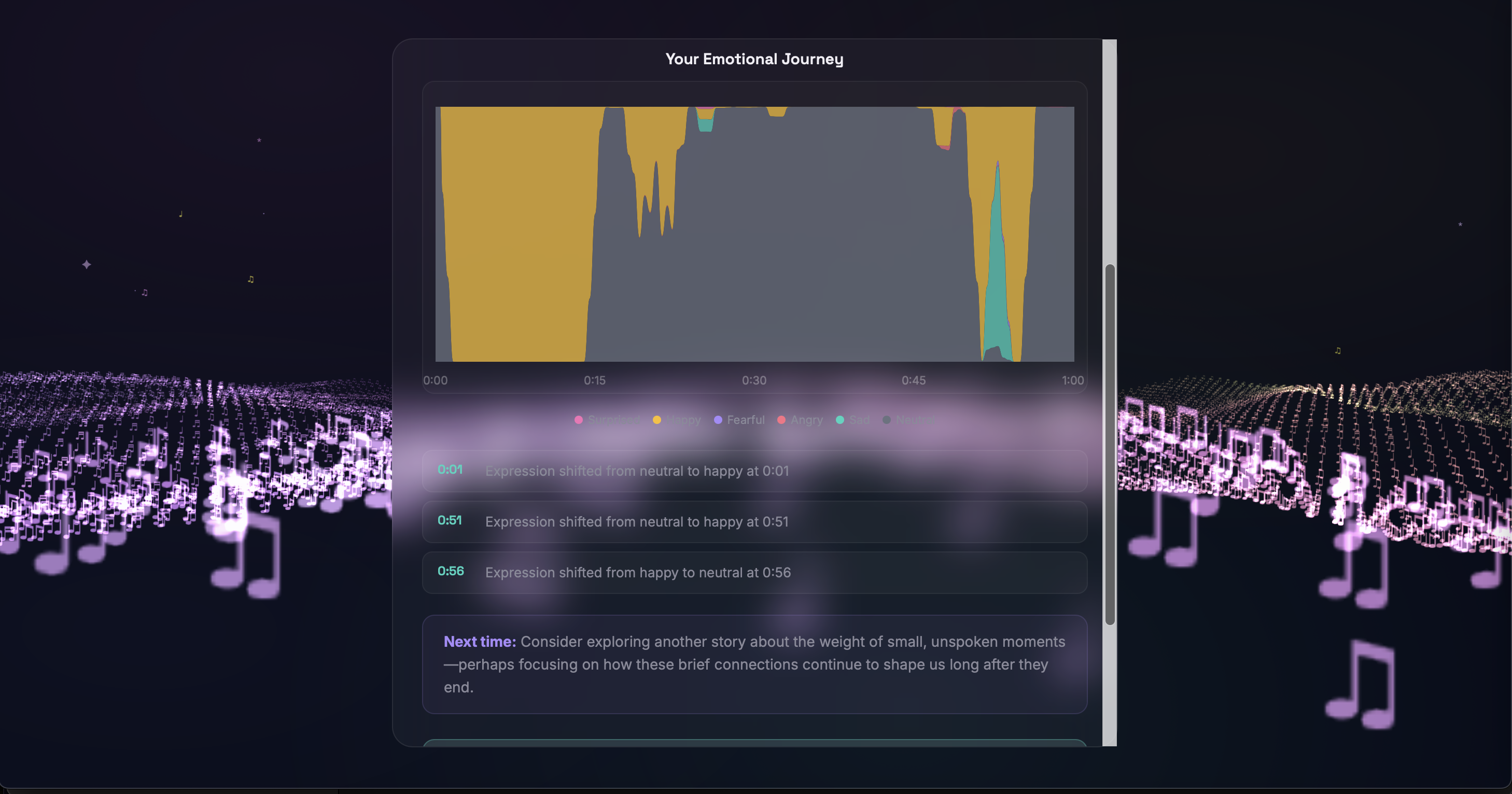
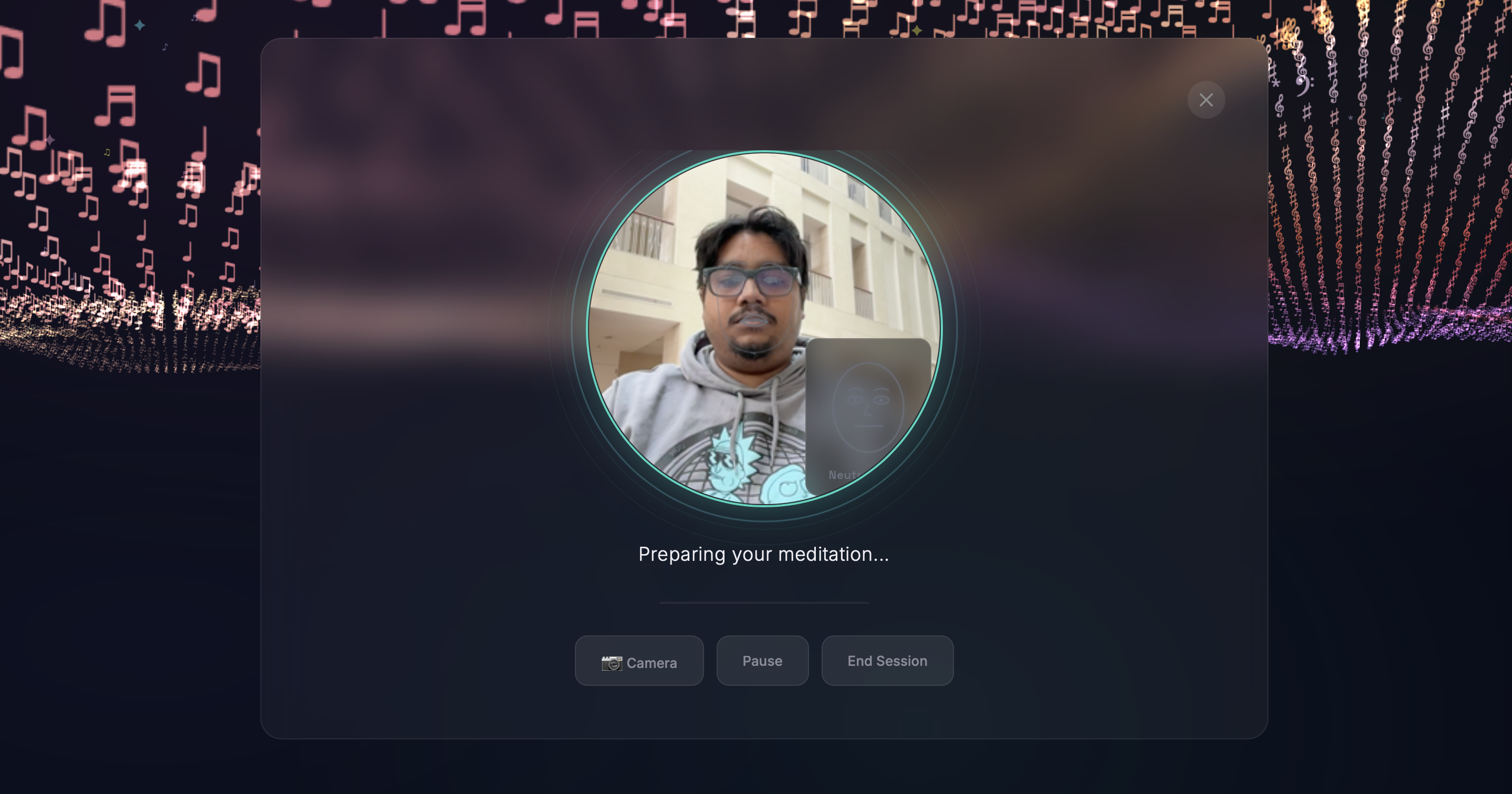
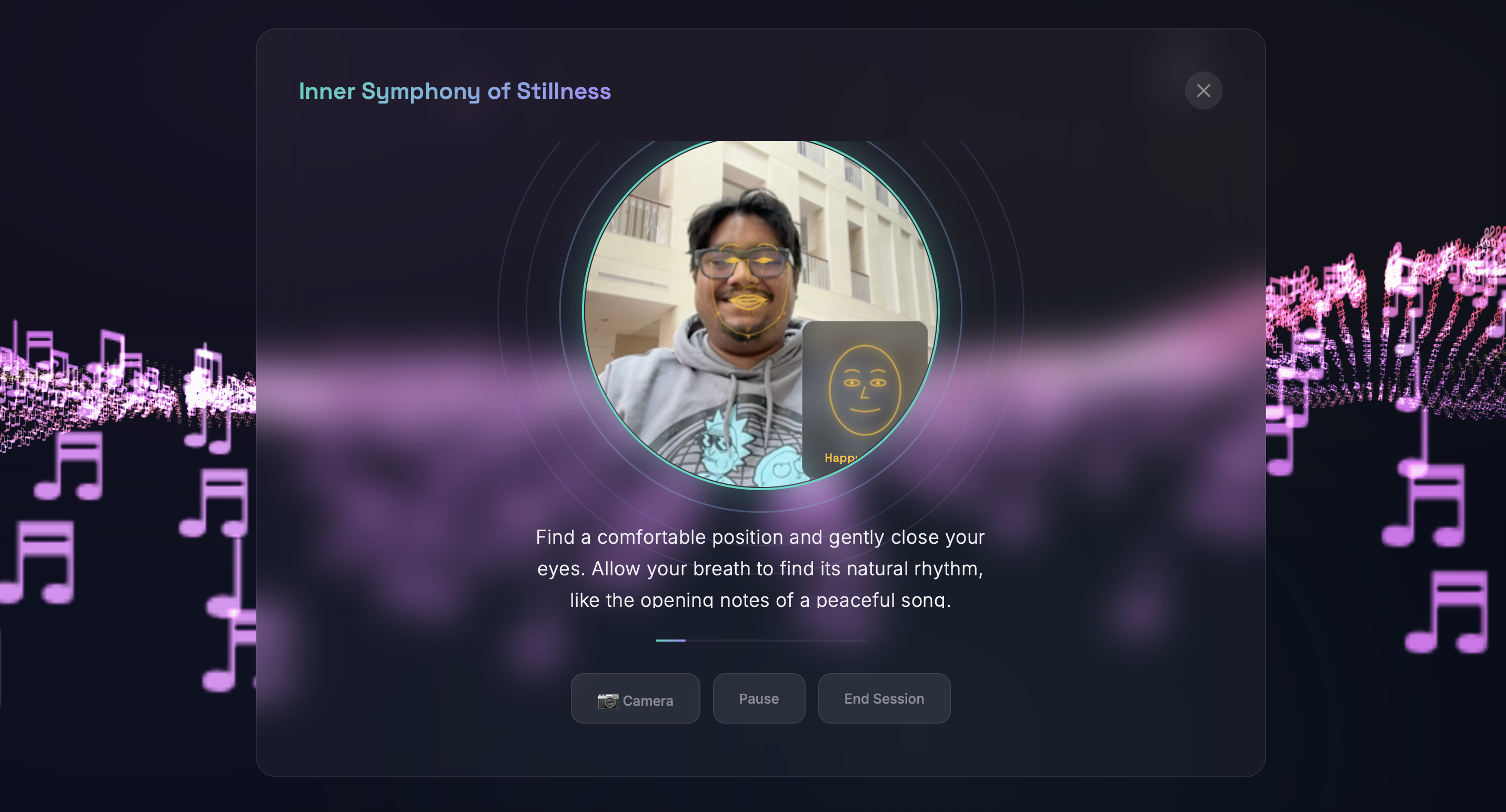
Facial Emotion Tracking - Using face-api.js for real-time facial landmark detection, the app reads micro-expressions and maps them to emotional states. The detected emotion dynamically tints the 3D landscape and particle colors, creating a visual mirror of your feelings. The system also suggests AI-generated emotional reflections after song playback based on detected mood shifts!
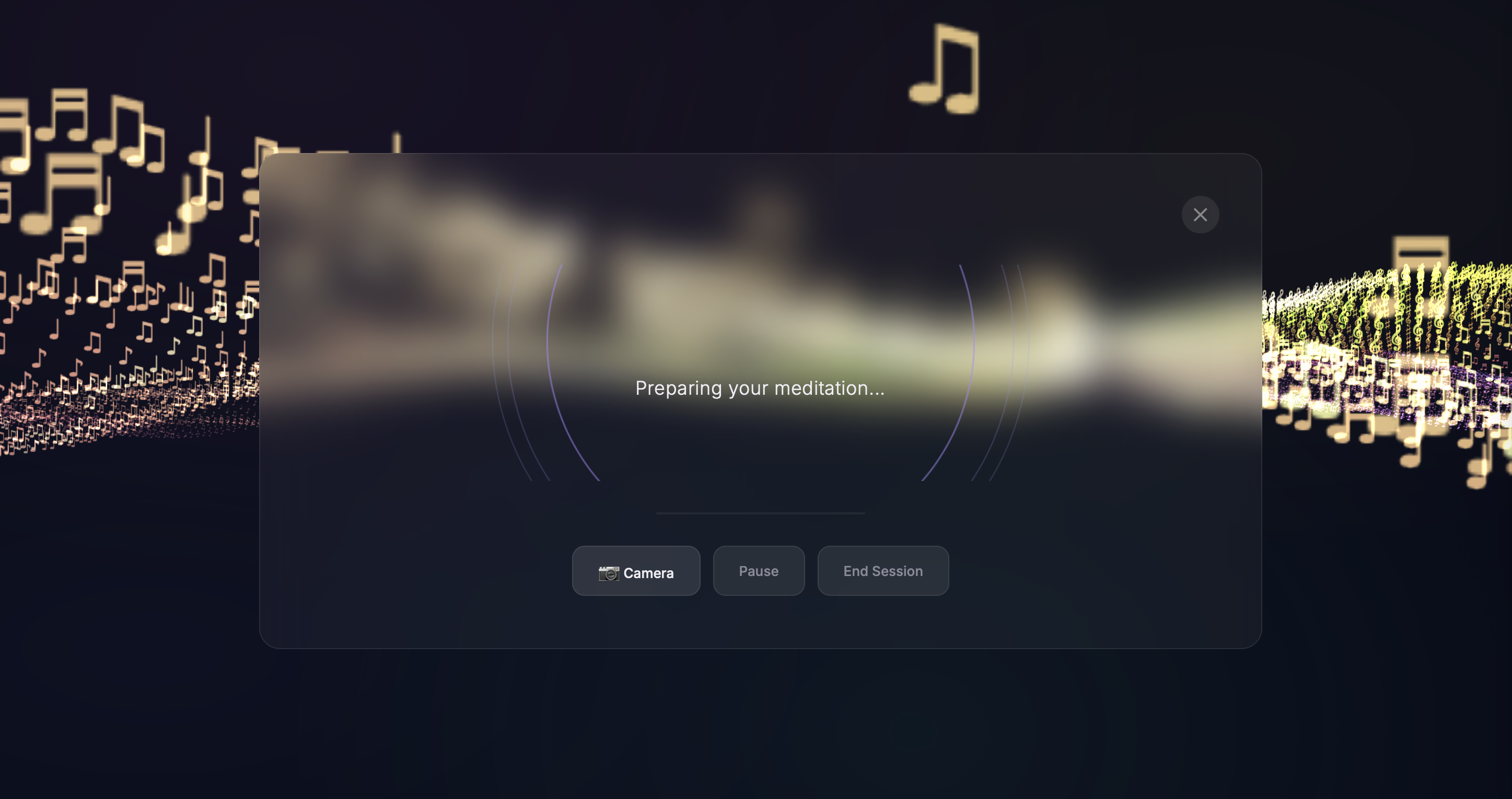
Guided Meditation - AI-narrated breathing exercises with concentric breath-ring animations synchronized to inhale/exhale cycles. The webcam tracks the user's presence during meditation, and the session adapts pacing based on engagement. A calming dedicated view removes all other UI distractions.
Immersive Musical Landscape - A fully custom Three.js background built from a glyph atlas of musical notation characters (♪ ♫ 𝄞 ♯ ♭). A 250x80 grid of points uses custom vertex/fragment shaders with procedural simplex noise for terrain generation, ocean-like wave undulation, per-point sparkle effects, and HSV color cycling through aurora palette colors. Features an immersive field, star field with sun/moon arcs, shooting stars, and a cinematic fly-through camera that slowly glides through the terrain.
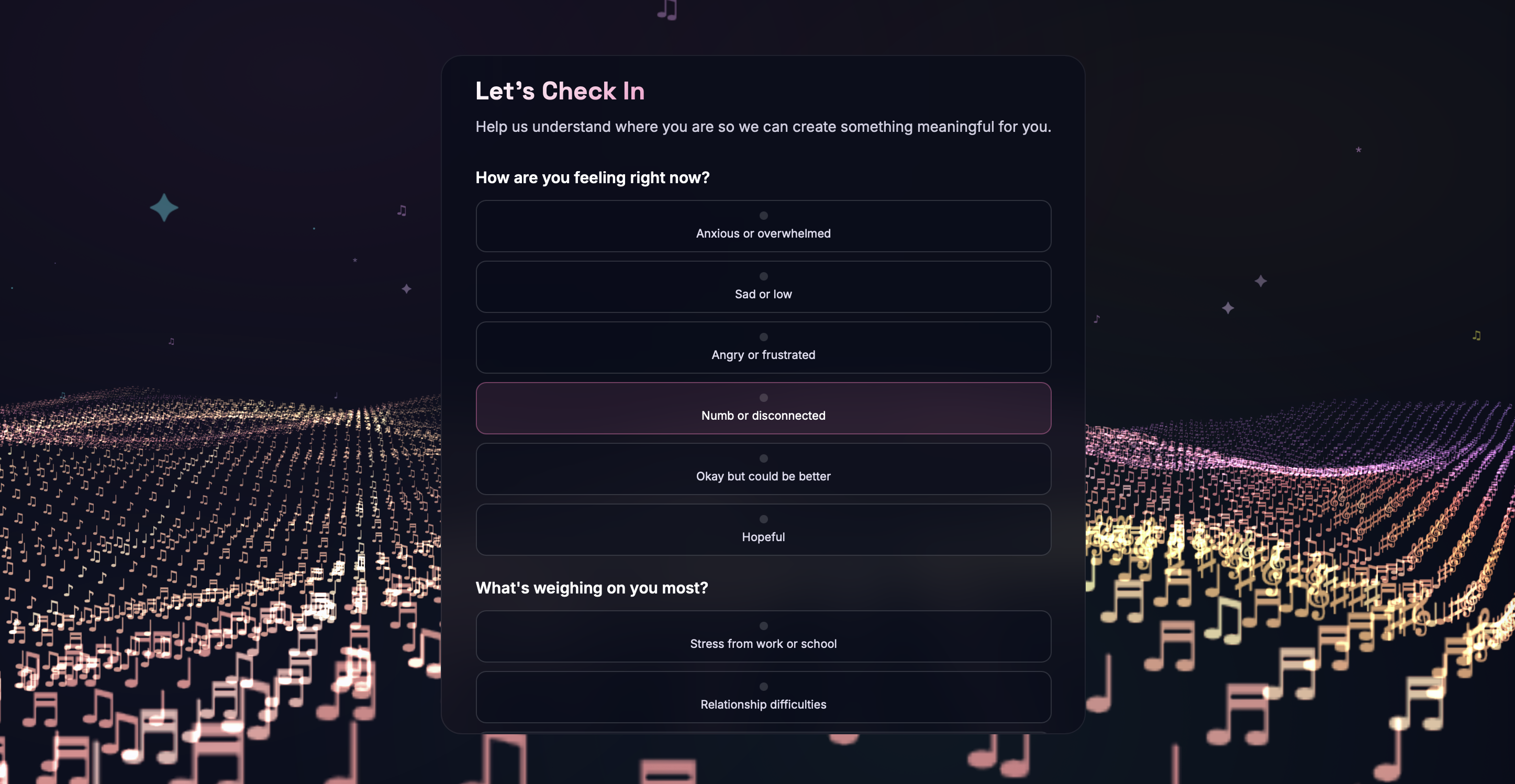
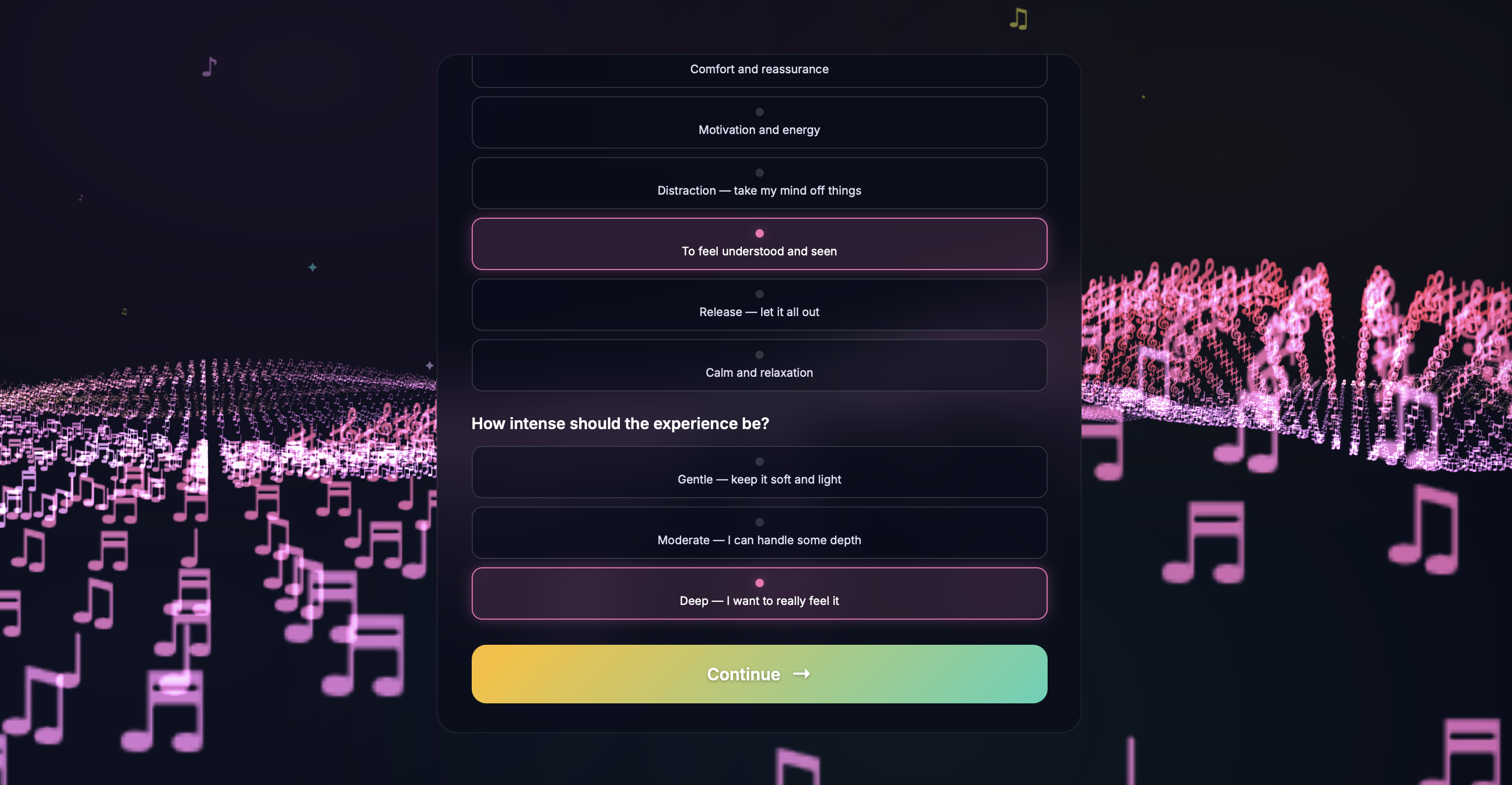
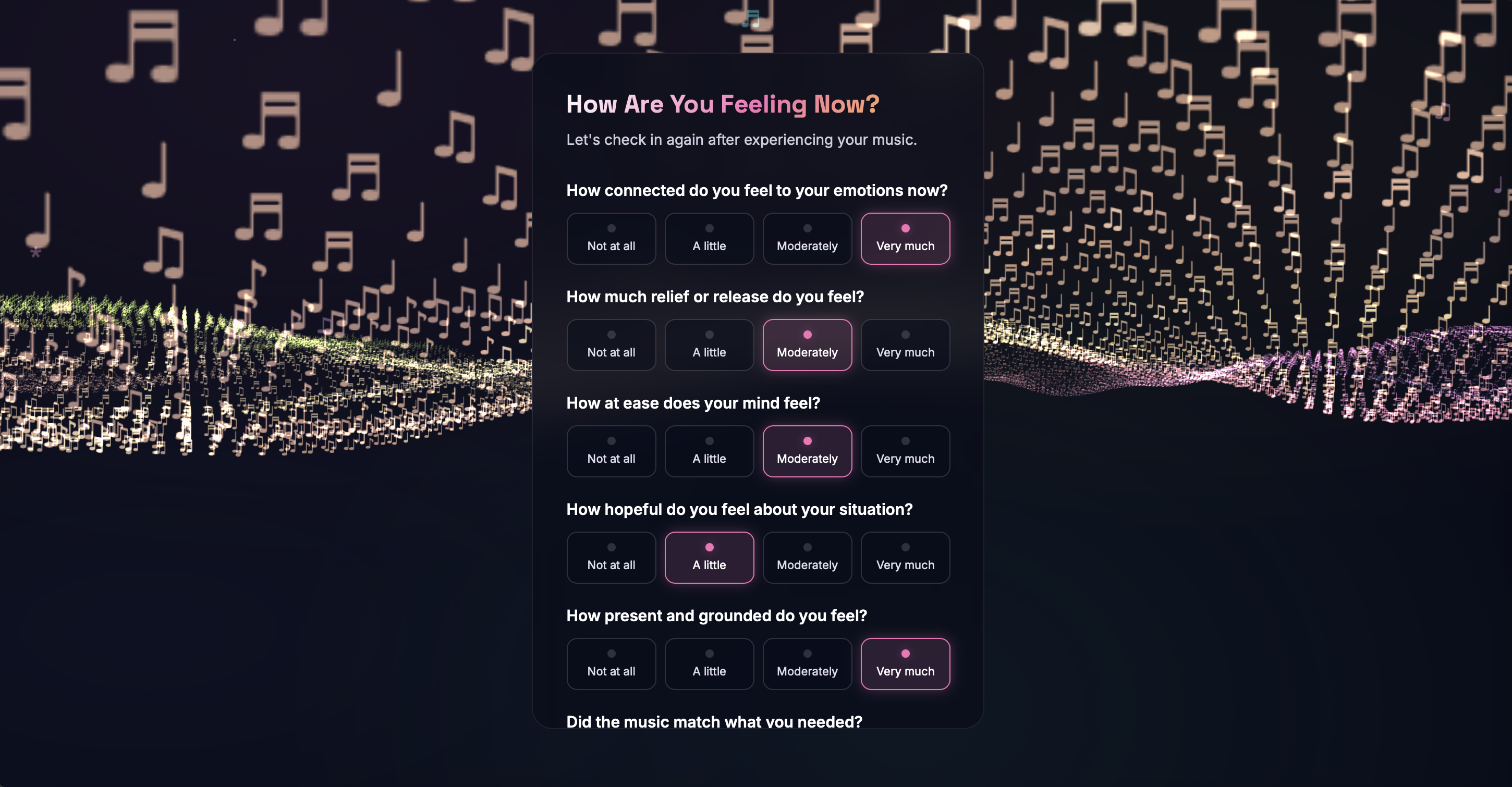
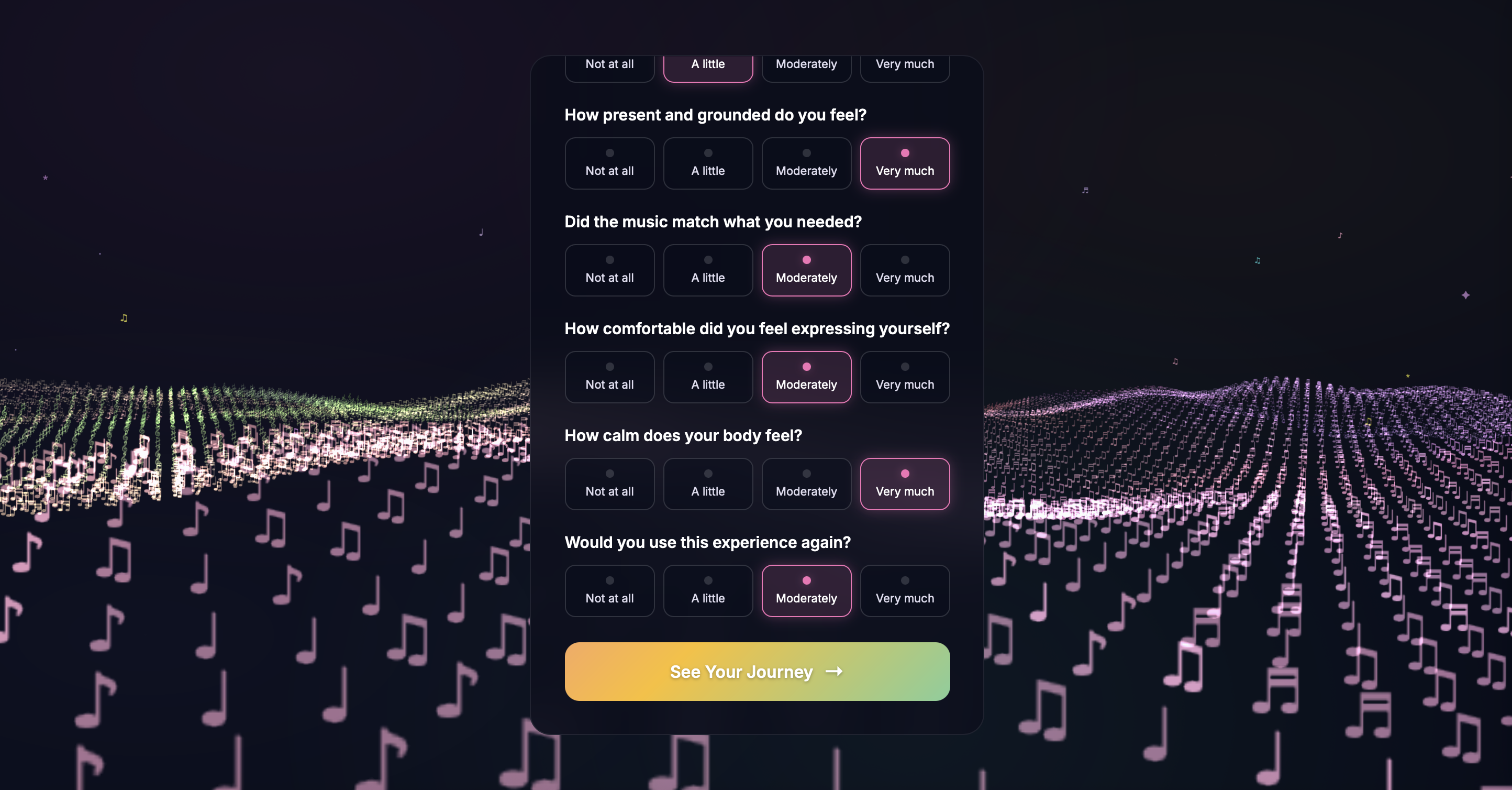
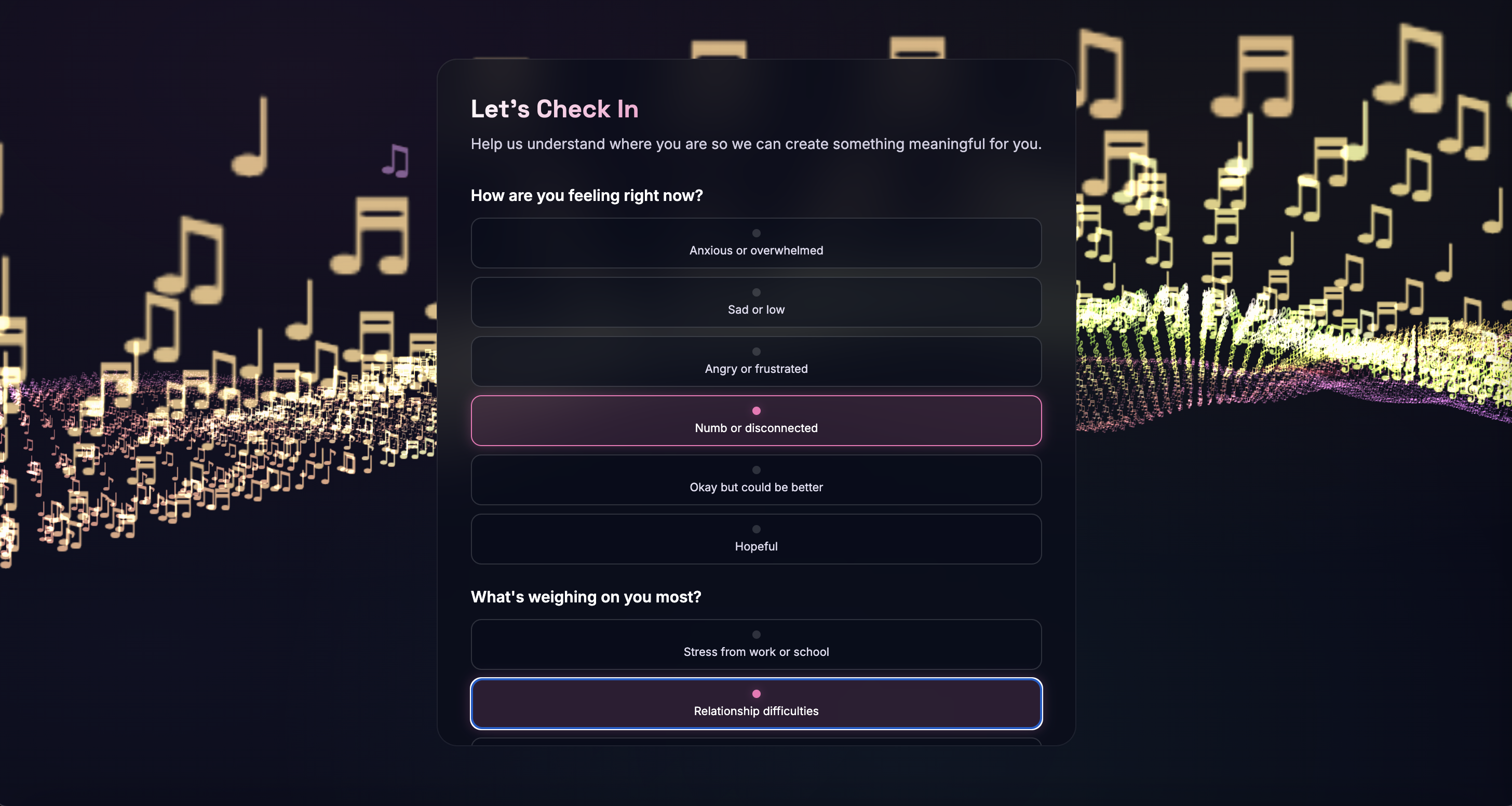
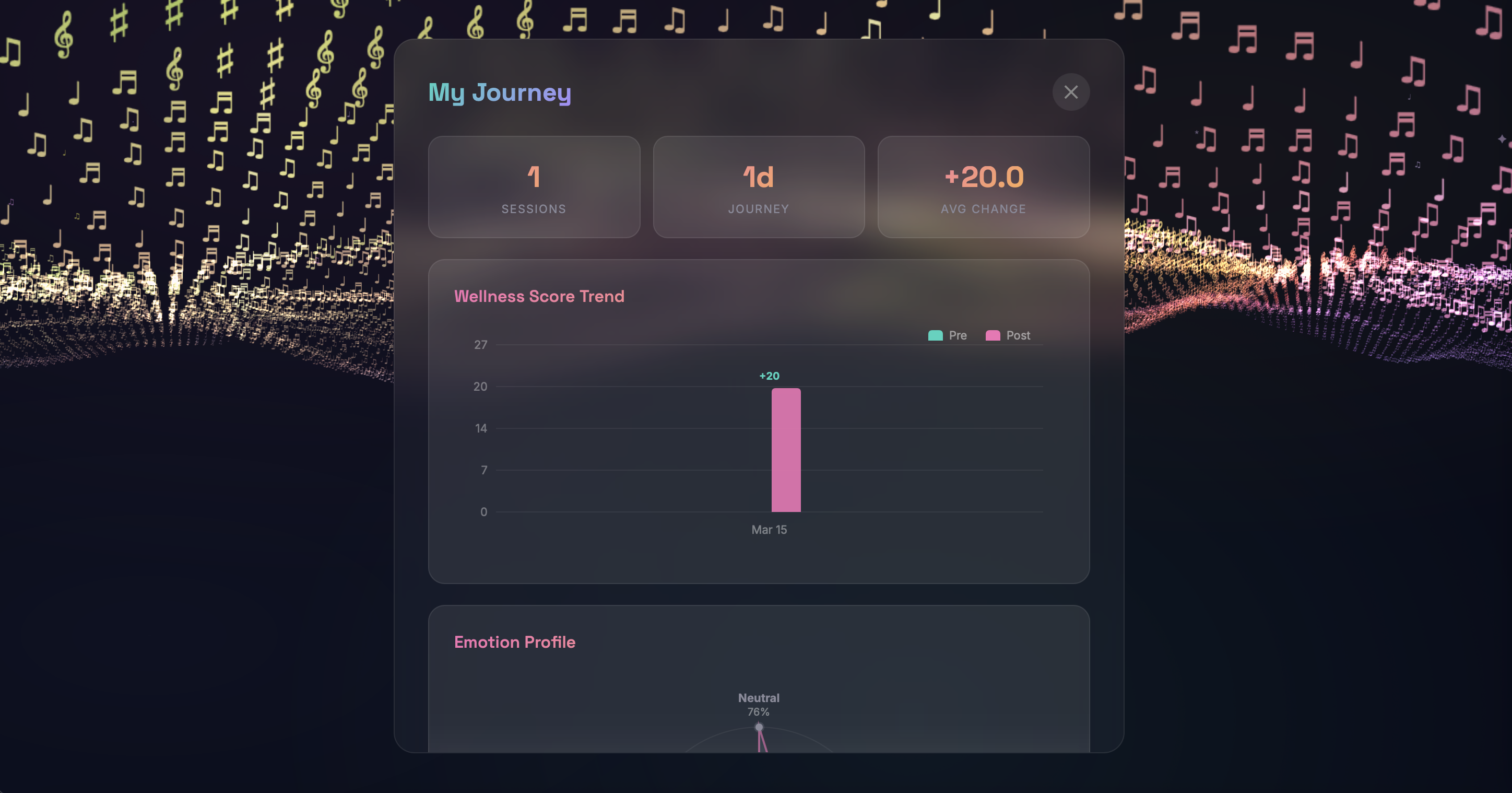
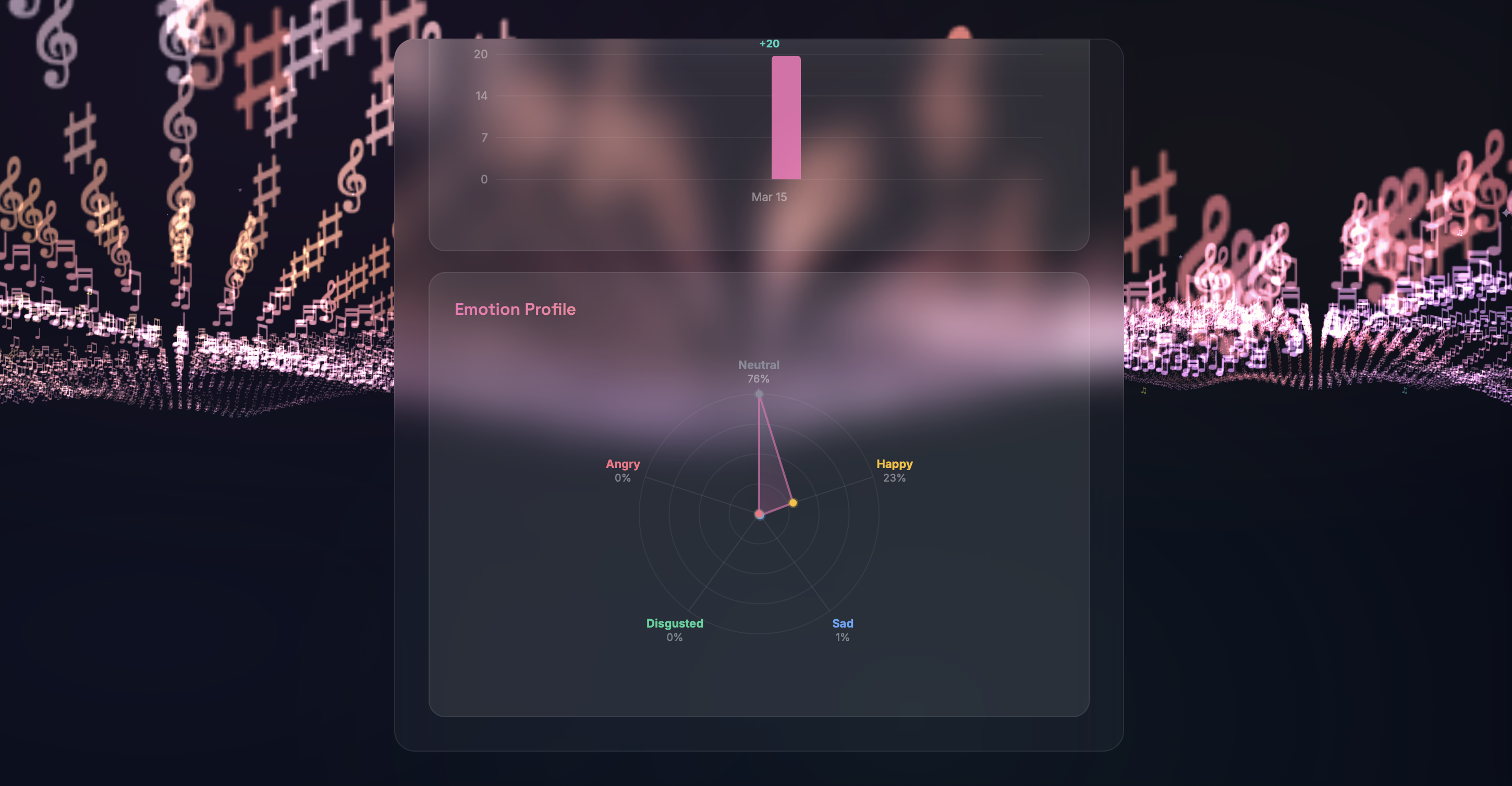
Mood Check-In & Journey Dashboard - PHQ-style questionnaires assess emotional state at session start, tracking anxiety, mood, stressors, and coping preferences. Results are stored per session and visualized in a longitudinal journey dashboard, helping users and potential providers identify emotional patterns over time.
## How we built it
- Backend: Python/FastAPI serving the API, Claude Sonnet API for the chatbot and emotion suggestions, Claude Opus 4.6 for iterative lyric/music generation, ElevenLabs for vocal synthesis
- Frontend: Vanilla JS with a glassmorphism UI, Three.js for the 3D musical landscape, MediaPipe Hands for gesture detection, face-api.js for emotion tracking, Web Audio API for real-time audio effects
- Architecture: Plain script tags (no bundler), all modules communicate through global functions. The background system is modular: glyph atlas → landscape grid → sky system → immersive playground → integration
## Challenges we ran into
- Emotion-to-music algorithm - Writing the algorithm that extracts emotional features from a user's story and converts them into musical parameters (tempo, key, mood, instrumentation style) and coherent lyrics was one of the hardest barriers. Mapping nuanced human emotions to concrete audio characteristics required extensive prompt engineering and iterative refinement. Another problem was understanding the mental health struggles user faces while also ensuring AI safety and ethics was imperative to our mission statement.
- Facial emotion integration into song generation - Feeding real-time facial emotion data back into the prompt generation pipeline for the user's next song was technically complex. The detected emotions needed to be weighted, averaged across a session, and seamlessly merged with the story-based emotional profile without overriding the user's intent.
- Session persistence and user pipeline - Constructing the full data pipeline - connecting user_id to the user_table, persisting session history, and remembering previous emotional journeys across multiple visits required careful database architecture. Getting the chatbot to recall prior context and the dashboard to display longitudinal data was tricky to get right.
- HTTPS deployment for camera access - Browser security policies require HTTPS for webcam access (MediaPipe, face-api.js). Our initial HTTP deployment on Vultr couldn't access the camera at all, forcing us to purchase a domain and configure SSL certificates before any CV features could be tested in production.
- API costs and testing - Every debugging cycle and new feature integration required end-to-end testing through the full generation pipeline, consuming ElevenLabs credits each time. We spent upwards of $50 on API costs alone to get the project working, making each test run a deliberate decision.
- Gesture system architecture - Getting hand gesture volume control to work simultaneously with other gestures (filter, distortion, reverb) required restructuring the entire gesture priority system. Volume had to be decoupled from mode-based effects so hand height stays responsive while any other gesture is active.
- Three.js musical landscape - The custom vertex/fragment shaders with glyph atlas UV mapping had several surprises - characters rendered upside down initially due to WebGL's gl_PointCoord Y-axis convention, and getting the terrain to wrap infinitely around a moving camera required careful coordinate math.
- Chatbot prompt quality - Making the AI chatbot produce usable, structured song prompts after some exchanges instead of requiring lengthy conversations required adding explicit early-summary triggers and careful system prompt engineering.
## AI Safety & Ethics
Mental health is a sensitive domain, and we took deliberate steps to ensure Hear Me Out does no harm:
- Crisis intervention - The system actively monitors all chatbot conversations and user inputs for signs of suicidal ideation, self-harm, or crisis language. When detected, it immediately halts the conversation flow and presents a full-screen intervention with the 988 Suicide & Crisis Lifeline, Crisis Text Line, and international resources. User safety always takes priority over engagement.
- Guardrails against harmful AI outputs - Claude's system prompt is carefully engineered to never encourage self-harm, validate destructive behavior, or provide medical diagnoses. The chatbot is positioned as a supportive companion, not a therapist or clinician, and explicitly redirects users to professional help when conversations indicate severity beyond its scope.
- Camera opt-in, not opt-in by default - All webcam features (hand gestures, facial emotion tracking, meditation tracking) are strictly opt-in. Users must explicitly activate the camera, and the app functions fully without it. No video data is transmitted to any server - all CV processing happens entirely client-side in the browser using MediaPipe and face-api.js.
- No data exploitation - Emotional data from questionnaires and sessions is used solely to serve the user's own journey dashboard. Stories and chat conversations are processed for song generation and are not used to train models or shared with third parties.
- Transparency - The app clearly identifies itself as an AI-powered tool, not a substitute for professional mental health care. All AI-generated content (songs, chatbot responses, meditation narration) is labeled as such.
## What we learned
- Music lowers the barrier to emotional expression - users who might hesitate to describe their feelings directly opened up naturally when framing it as a story that would become their song. This reinforced that creative mediums can reach people where traditional mental health tools struggle.
- Real-time computer vision in the browser (MediaPipe hand tracking, face-api.js emotion detection) is surprisingly production-ready, but gesture disambiguation is a real engineering challenge. A fist and a thumbs-up share most of the same landmark positions - the difference comes down to a single thumb distance threshold.
- Building with AI in the mental health space demands constant ethical vigilance. Every prompt, every response path, every edge case needs to be evaluated through the lens of "could this cause harm?" We learned that safety isn't a feature you bolt on - it has to be woven into every layer, from crisis detection in the chatbot to guardrails against harmful song lyrics to making camera access strictly opt-in.
- Claude's ability to simultaneously act as an empathetic conversational companion and extract structured emotional data (mood, themes, intensity) into a usable generation prompt is remarkable. The dual role - therapeutic presence and data pipeline - worked better than we expected with careful system prompt design.
- WebGL shader programming with glyph texture atlases opened up an unexpected visual language - rendering entire landscapes from musical characters at 60fps. The technique of encoding text into a sprite sheet and sampling it per-point in a custom fragment shader is broadly applicable beyond our use case.
- Responsible AI development costs more - in time, in API credits, in testing cycles. But when the domain is someone's mental health, cutting corners isn't an option. The extra $50+ in ElevenLabs credits and the hours spent on safety guardrails were non-negotiable investments.
## What's next
- Collaborative sessions where multiple users contribute to one song
- Spotify/Apple Music export for generated songs
- Therapist dashboard for providers to review patient emotional journeys
- Mobile app with native gesture controls
- Integration with wearable devices for biometric mood tracking
Built With
- claude-api-(anthropic)
- elevenlabs-api
- face-api.js
- fastapi
- gemini-api
- html/css
- javascript
- mediapipe-hands
- python
- sqlite
- three.js
- vultr
- web-audio-api
- webgl

Log in or sign up for Devpost to join the conversation.