-
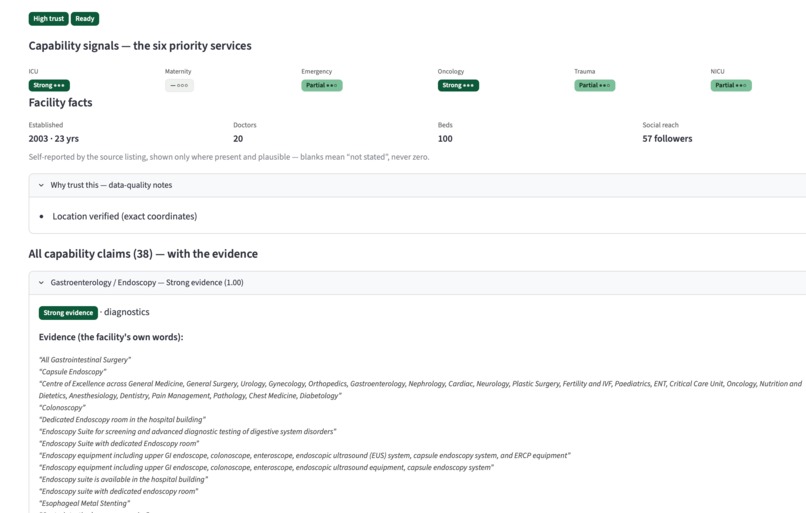
Drill into claims
-
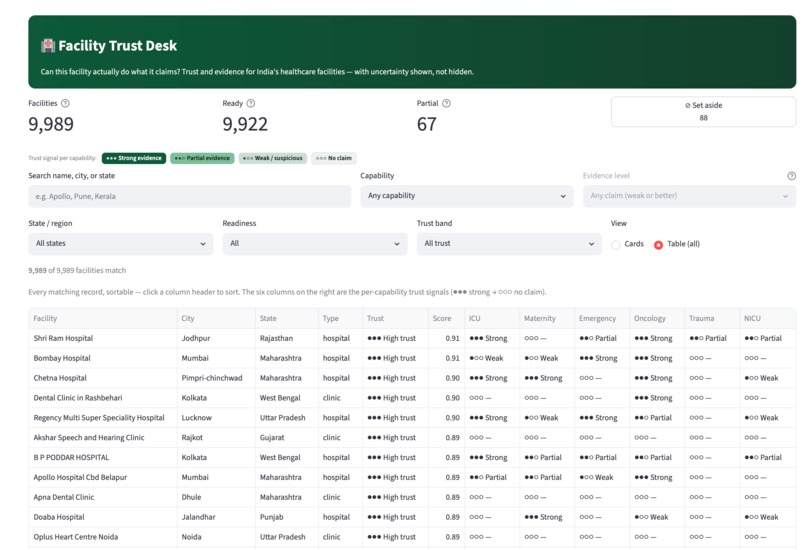
Table view
-
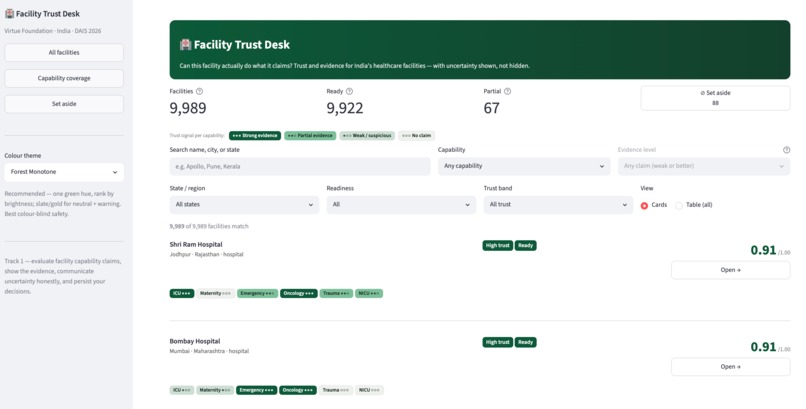
Home page
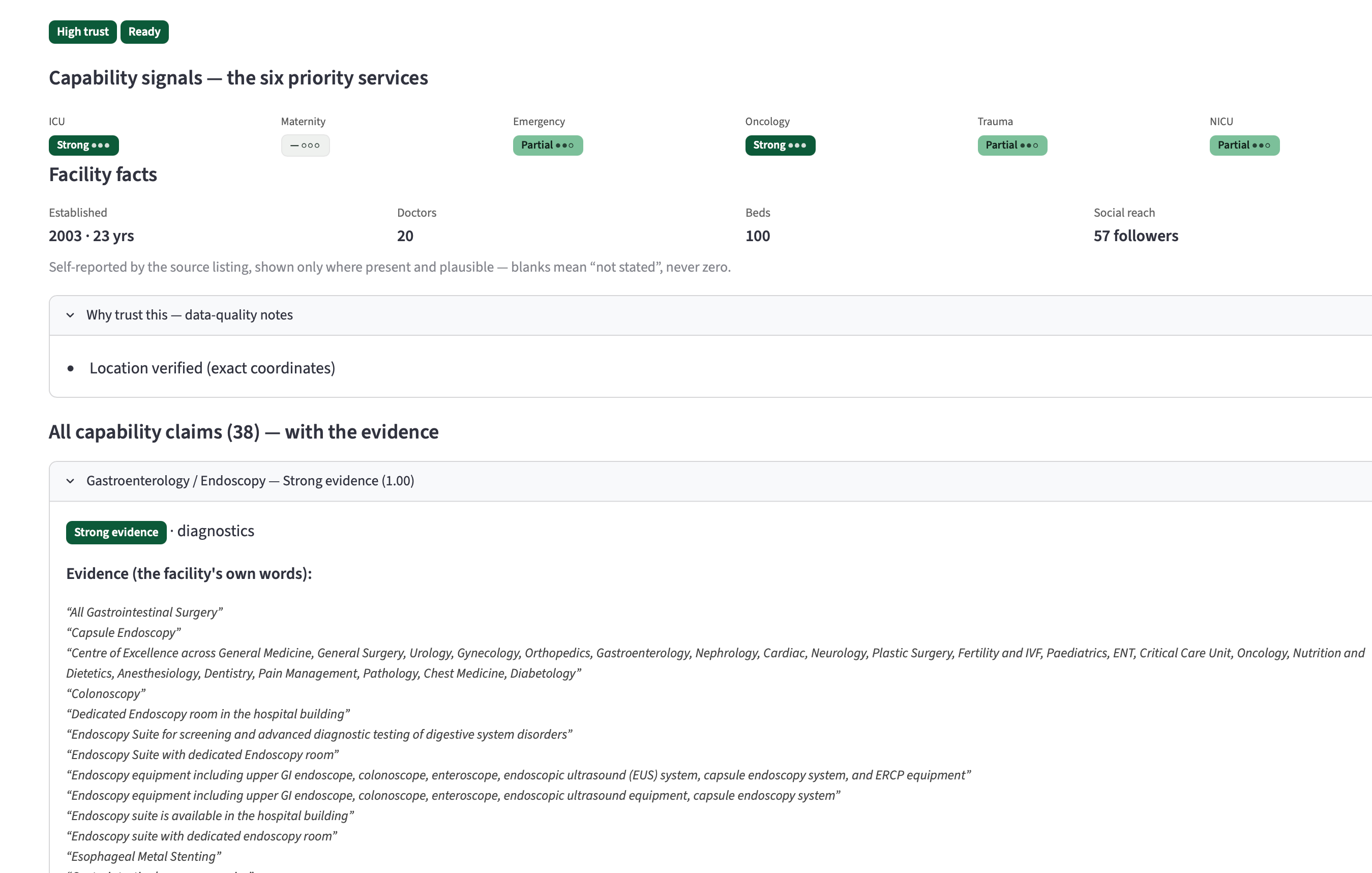
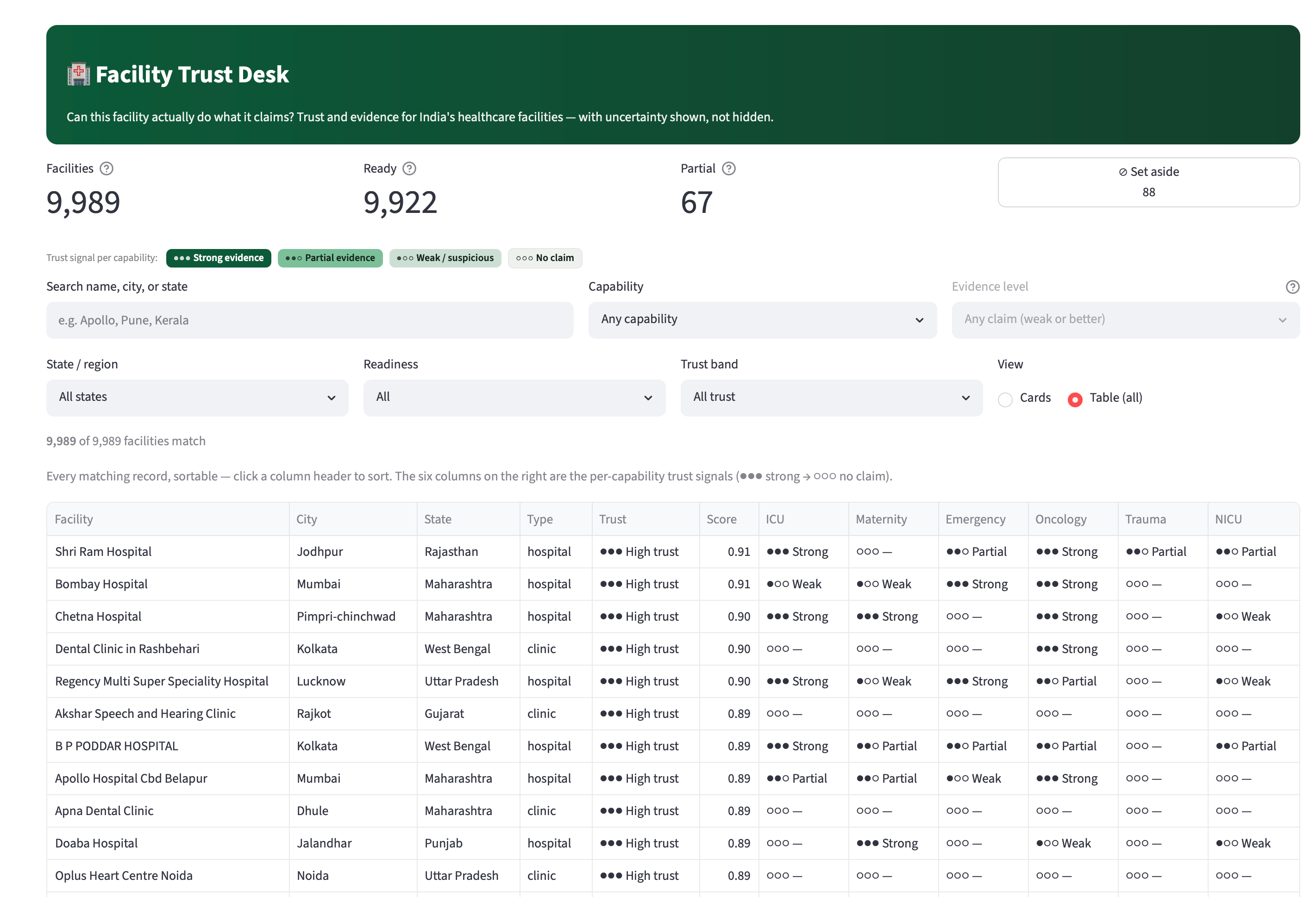
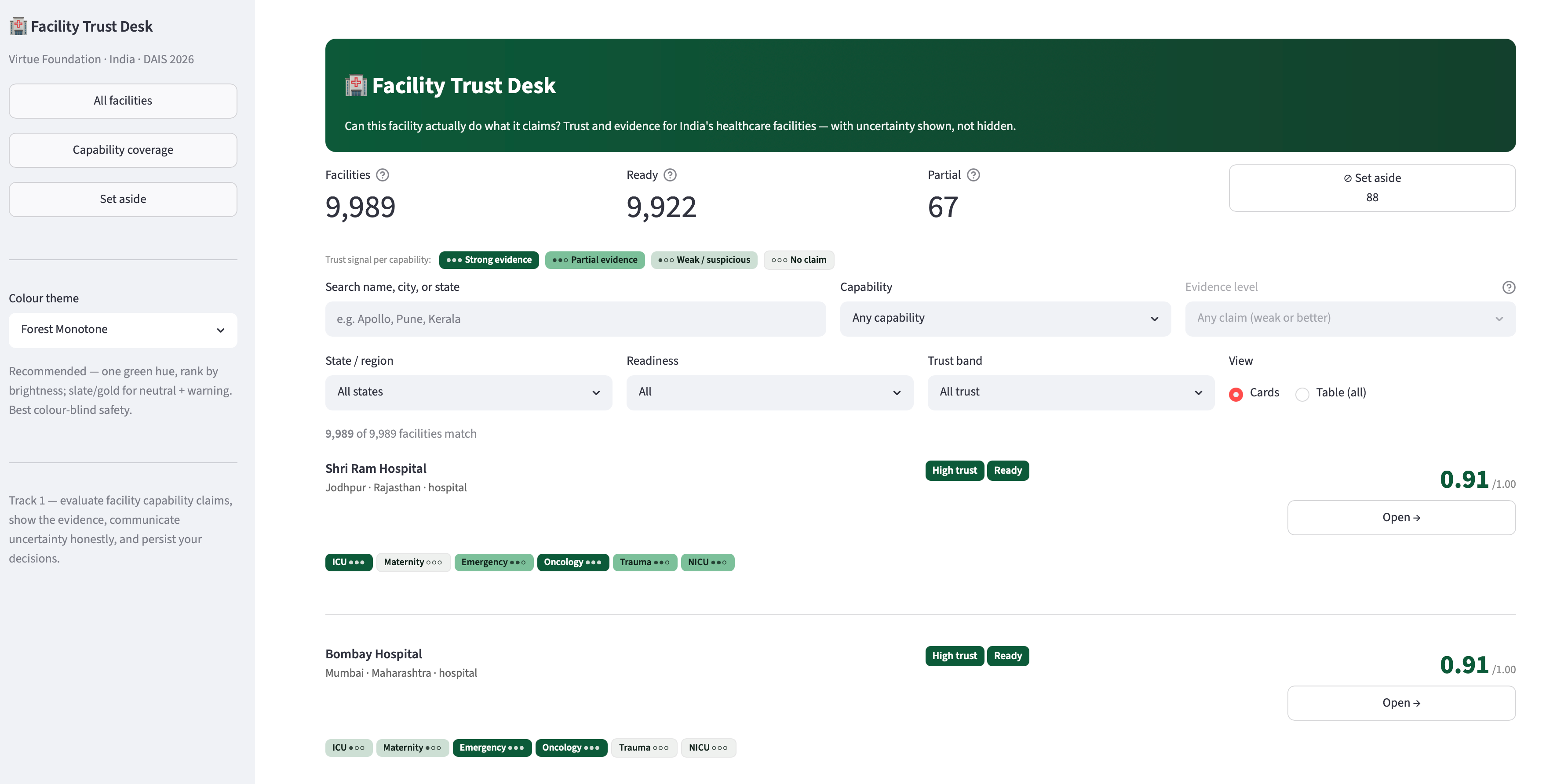
Inspiration Virtue Foundation's dataset is ~10,088 healthcare facilities across India, scraped from the open web into 51 messy columns: free-text capability blurbs, duplicate listings, missing or wrong geocoordinates, and capability claims that range from credible to clearly templated marketing. An NGO trying to route a surgical mission or a donation can't act on a spreadsheet like that — they need to know, per facility and per capability, how much to trust what the data says, and why. The trap with messy data is to either trust it blindly or throw the bad rows away. We wanted to do neither. We were inspired by the hackathon's four-part challenge — extract structure, show evidence, communicate uncertainty honestly, and persist the user's decisions — to build a tool that treats "we're not sure" as a first-class, defensible answer instead of hiding it. What it does Facility Trust Desk turns 10,088 noisy records into a per-facility, per-capability trust signal that always shows its work. Per-capability trust signals. For eight priority capabilities (surgery, maternal care, diagnostics, emergency, etc.) every facility gets a signal — strong / partial / weak / no claim — instead of one blunt "good/bad" score. Evidence, always. Every signal links back to the verbatim source text it came from. Nothing is asserted without a citation a human can check. Honest uncertainty. Records we can't responsibly use are quarantined with a stated reason, not silently dropped. Facilities surface as READY / PARTIAL / QUARANTINE based on what we actually know. Statistical outliers (e.g. a "12,000-bed" clinic) are nulled to "not stated" rather than shown as fact. Decisions persist. Users can accept or flag a facility; those decisions are written back to a Lakebase table so the desk remembers them across sessions. Sub-10ms lookups. The whole experience runs off point reads of ~3–10ms, so it feels like a product, not a notebook. Plus a map view, a sortable all-records table, a transparent excluded-records page, and a coverage page that's honest about how complete the underlying data is. How we built it End-to-end on Databricks, as a reproducible medallion pipeline feeding a low-latency app: Unity Catalog + Delta Lake — the source arrives via a Delta Sharing catalog; we land it as true raw bronze, cleanse every row in silver (dedup, DQ flags, quarantine, PIN-centroid geo recovery, capability matching), and publish gold (gold_facility_trust, gold_sync). Foundation Model APIs — our marquee feature. We run ai_query with Llama 3.3 70B over the one field with 100% coverage (the free-text description) to extract capability mentions and the verbatim span that proves each one. That found 2,385 capability signals across 1,556 facilities — 2,042 corroborating the structured fields and 355 net-new the columns missed. Determinism firewall — because an LLM isn't reproducible, its output is materialized once to a frozen Delta table that sits outside the deterministic pipeline, so our golden tests stay byte-stable. Lakebase (managed Postgres) + synced tables — gold is synced to a Postgres gold_trust table via a DATABASE_TABLE_SYNC pipeline and served through a managed online catalog, giving the app PK-indexed point reads in single-digit milliseconds. User decisions write back to a separate Lakebase table. Databricks Apps — the UI is a Streamlit Databricks App, bound to Lakebase via a service-principal grant managed in Unity Catalog. Databricks Asset Bundles + Jobs + Serverless — one DAB owns the whole thing: a serverless Job runs the medallion as a per-layer bronze → silver → gold → sync DAG with full run history. Reproducibility gate — the SQL pipeline is wrapped in a typed, frozen PySpark package that runs the validated SQL verbatim, guarded by a byte-identity golden oracle (md5 content hash) and a pytest suite, runnable via Databricks Connect or the Statement Execution API. Challenges we ran into Geo-only "accuracy" was the wrong idea. Our first cut graded facilities mostly on exact coordinates — punishing good facilities for a missing field. We re-grounded the trust model on geo_known (exact or PIN-approximate) and made it multi-signal, so geography is one input, not the verdict. Recovering data instead of discarding it. Thousands of rows had no coordinates but did have a postal PIN, so we recovered approximate geography from a PIN-centroid table — without pretending the precision is better than it is. Making an LLM safe inside a deterministic pipeline. ai_query is non-deterministic; our golden tests demand byte-stability. The fix was the determinism firewall — extract once, freeze to Delta, keep it off the golden path. Sub-10ms on a lakehouse. Delta scans are built for batch, not per-facility point reads, so we added Lakebase as a serving tier and proved the ~3–10ms reads against a real PK index. A platform failure mid-build. Our Lakebase endpoint became system-disabled and unrecoverable via every API on Free Edition. Rather than wait, we migrated the entire serving layer to a fresh project via the Databricks SDK — recreating the online catalog, synced table, SP role, and grant, with zero data loss because everything is reproducible from the gold Delta source. Deploy gotchas. App-in-bundle terraform collisions and a firewalled provider download both silently hung deploys; we learned to bind the existing app into bundle state and pre-seed the terraform provider cache. Streamlit at 10k rows. The all-records table lagged because a pandas Styler emits inline CSS per cell and defeats grid virtualization. We carried the signal in-text via a colour-blind-safe glyph instead, and scrolling went smooth. Accomplishments that we're proud of We met all four challenge pillars — structure, evidence, honest uncertainty, persisted decisions — instead of faking three of them. 355 capability signals that no column contained, each backed by a verbatim quote a human can verify — the dataset getting more trustworthy, not just summarized. Production-grade reproducibility in a hackathon — a byte-identity golden oracle over the whole transform. We recovered data others would have thrown away (PIN-centroid geo) and were transparent about the rows we couldn't (quarantine with reasons). The infra survived a real outage — when the managed endpoint died, we rebuilt the serving layer from code with no data loss. It feels like a product: single-digit-ms reads, a map, a trust matrix, and a clean, honest UI. What we learned Honest uncertainty beats false precision — calibrated doubt is something an NGO can actually act on. LLMs need a determinism firewall — AI extraction is hugely valuable, but inside a reproducible data product it must be materialized and pinned, never live on the golden path. Match the storage tier to the access pattern — Delta for batch, Lakebase for app point reads; forcing one to do the other's job is where latency explodes. Managed-platform constraints are architecture — a single sync slot and a daily app-run cap genuinely shaped our design. Evidence is a feature, not a footnote — once every signal cited its source, the tool went from "a model said so" to "here's why, check it yourself." What's next for Trust Desk Fuzzy de-duplication with ai_similarity / Vector Search — collapse near-duplicate listings the exact-match pass can't (the seam is already stubbed). Hard data gates — promote soft DQ flags into real RAISE_ERROR contracts so bad data can't reach gold. Wider, multilingual AI extraction — more capabilities, regional-language descriptions, per-span confidence. Close the human-in-the-loop — feed accept/flag decisions back into the trust model and a reviewer queue. Beyond India — generalize the medallion to new geographies and ingest more of the 51 source columns. Revive the Medical Desert Planner (Track 2) on the same gold layer — per-facility trust → per-region care-gap analysis.
Built With
- ai-query
- amazon-web-services
- aws-grouped
- database-table-sync
- databricks
- databricks-apps
- databricks-asset-bundles
- databricks-asset-bundles-(dab)
- databricks-cli
- databricks-connect
- databricks-foundation-model-apis
- databricks-jobs
- databricks-lakehouse
- databricks-sdk
- databricks-serverless
- databricks-sql
- databricks-sql-warehouse
- databricks-workflows
- delta-lake
- delta-sharing
- git-folder
- here's-the-built-with-list-?-copy-paste-this-comma-separated-set-of-tags-into-devpost:-python
- lakebase
- lakeflow
- llama-3.3-70b
- llama-3.3-70b-instruct
- pandas
- postgresql
- psycopg
- pyspark
- pytest
- python
- spark-sql
- sql
- statement-execution-api
- streamlit
- terraform
- unity-catalog

Log in or sign up for Devpost to join the conversation.