-
-
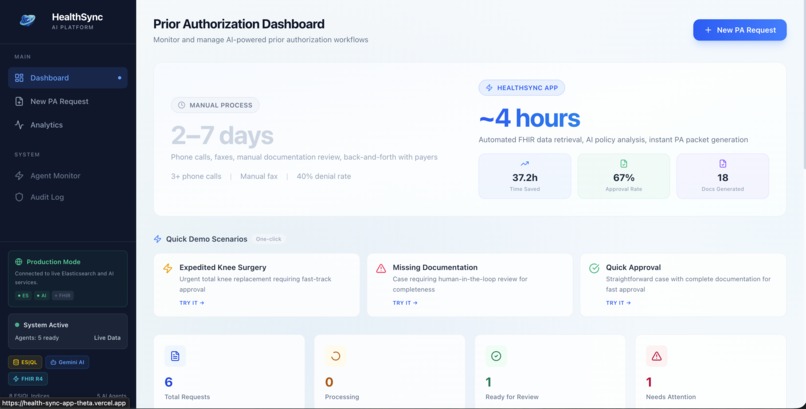
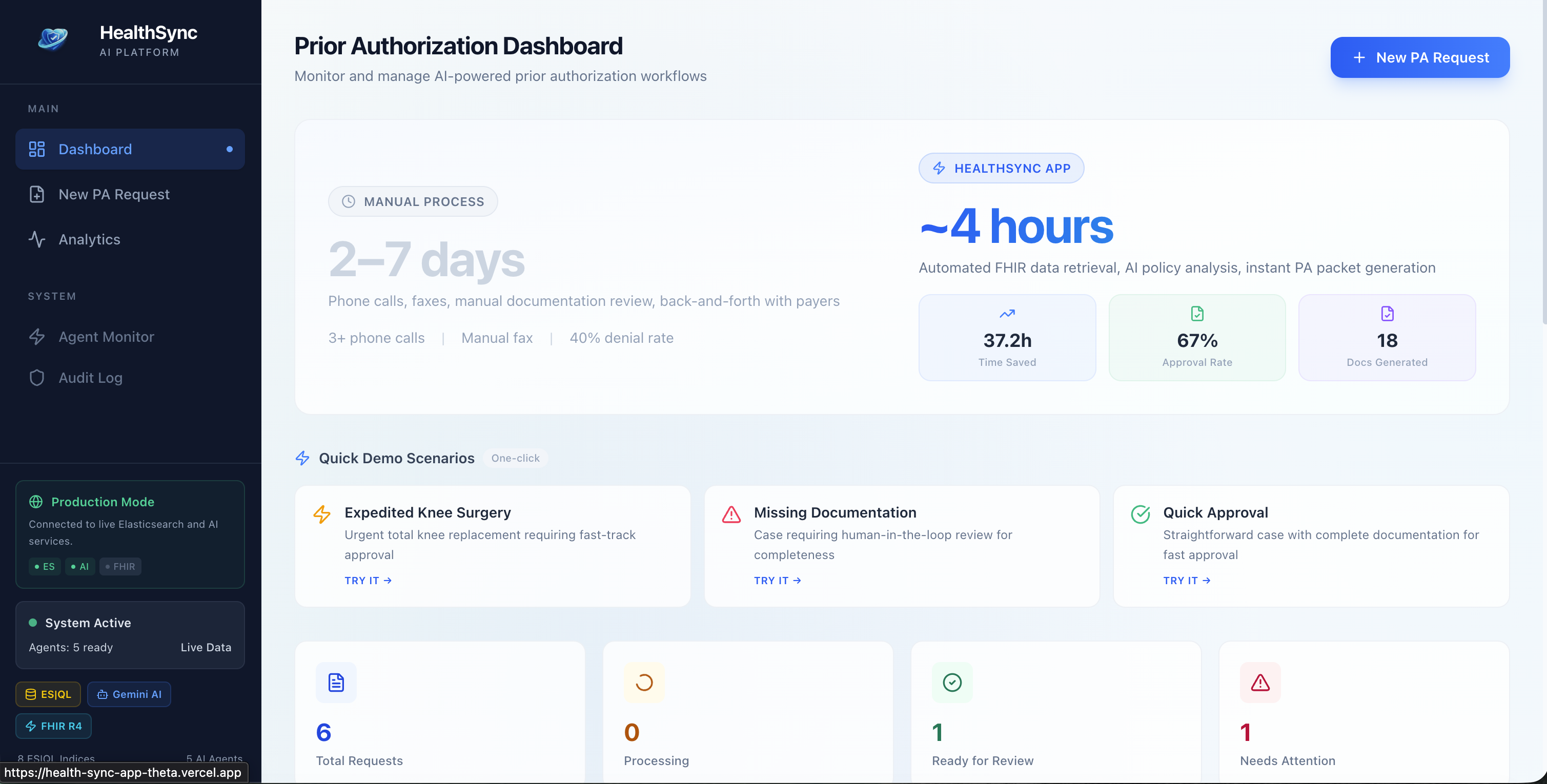
Dashboard
-
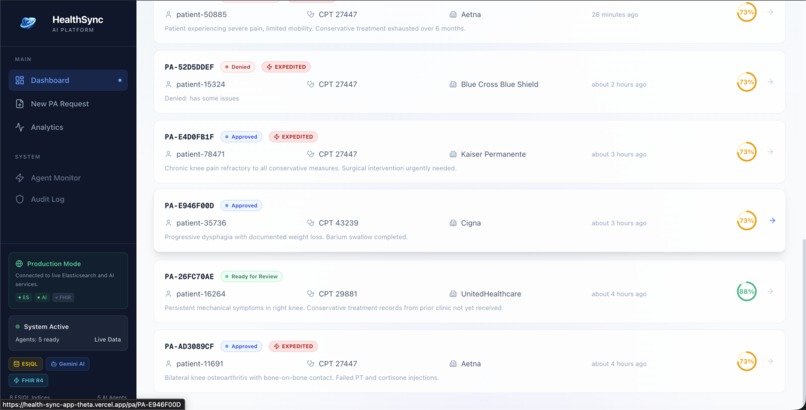
Dashboard Data
-
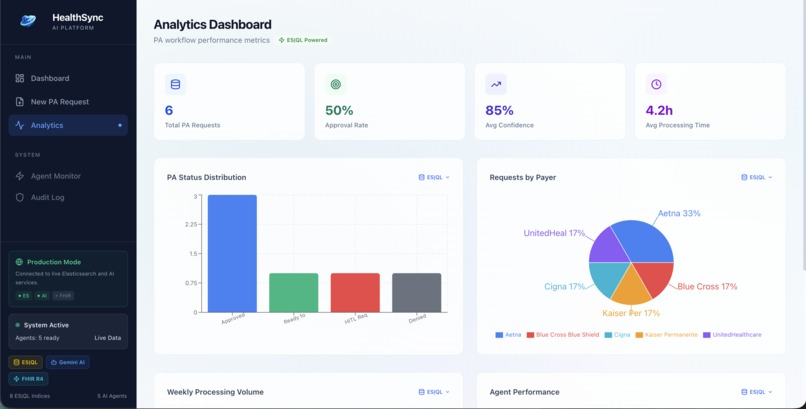
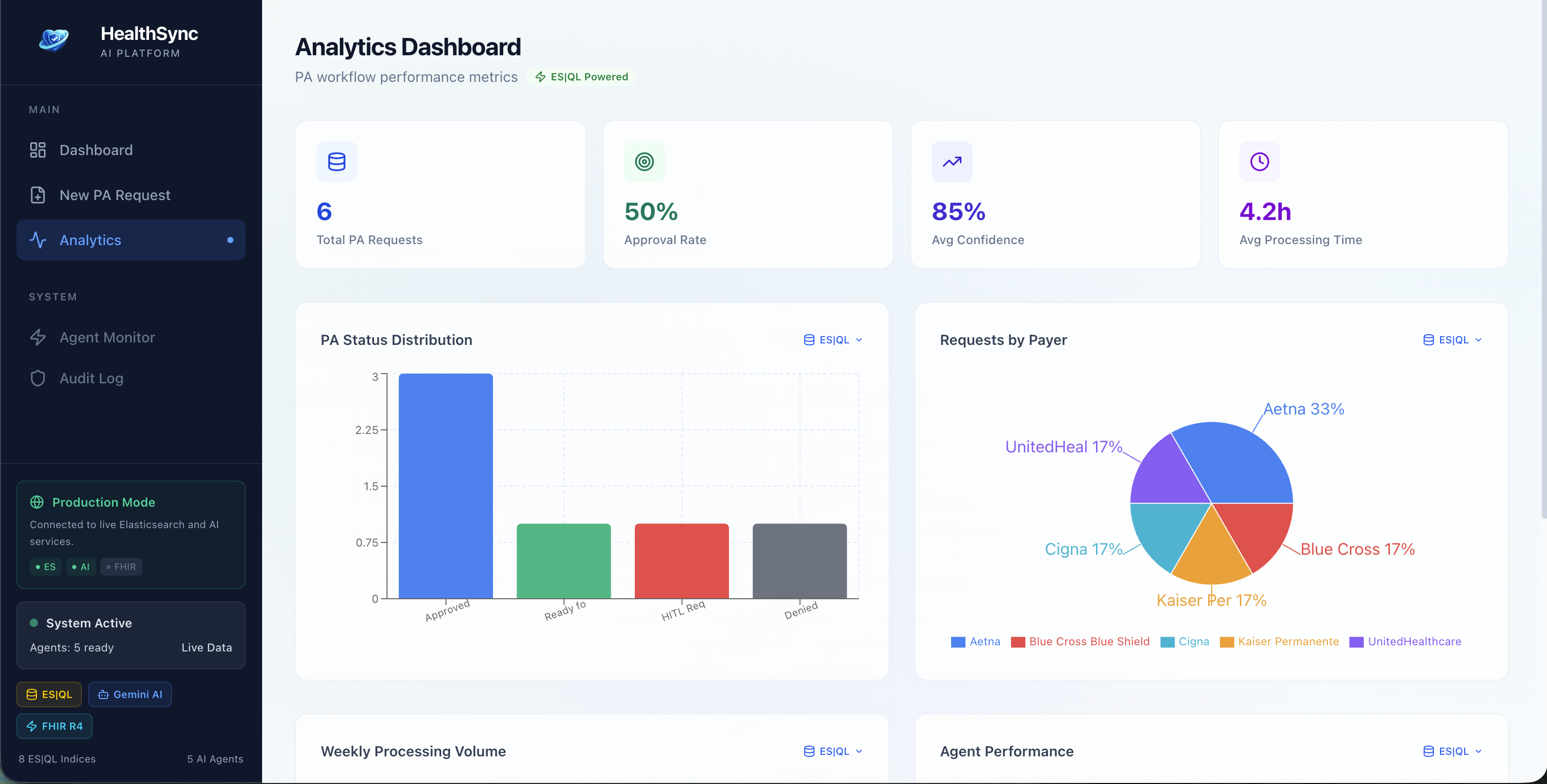
Analytics
-
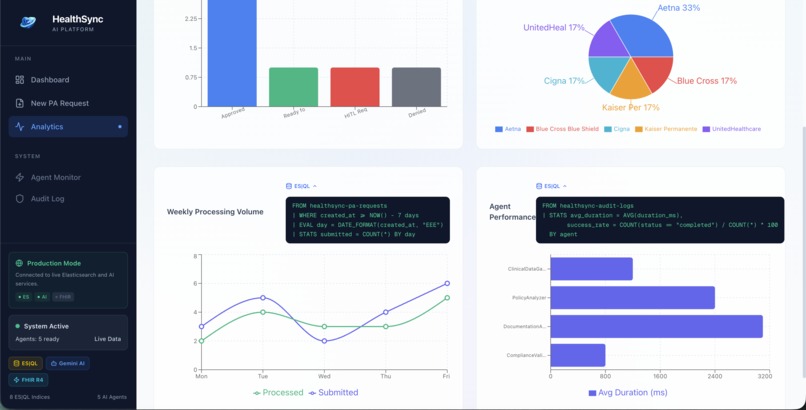
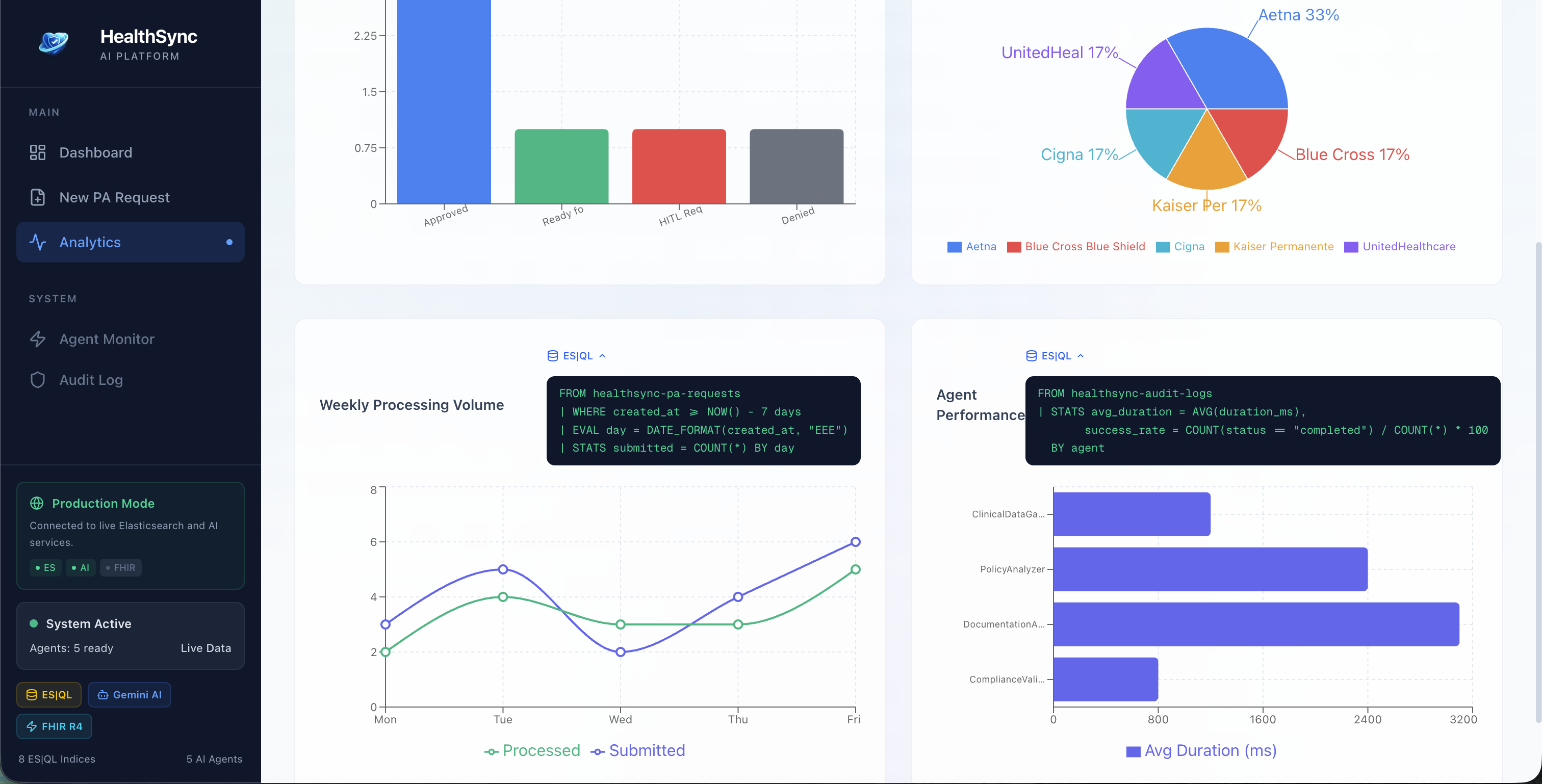
analytics | ES|QL
-
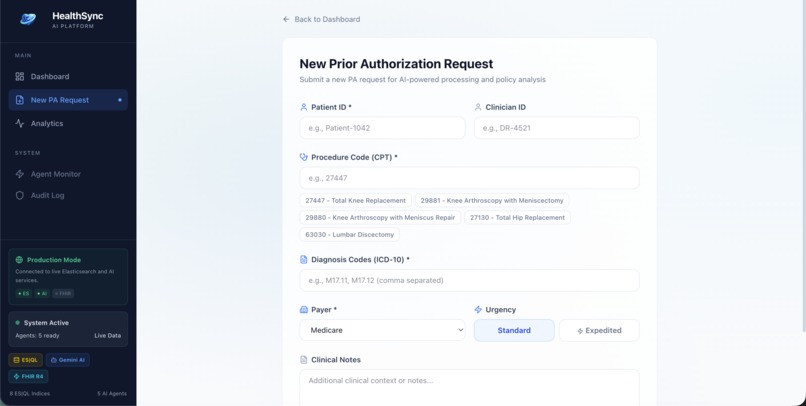
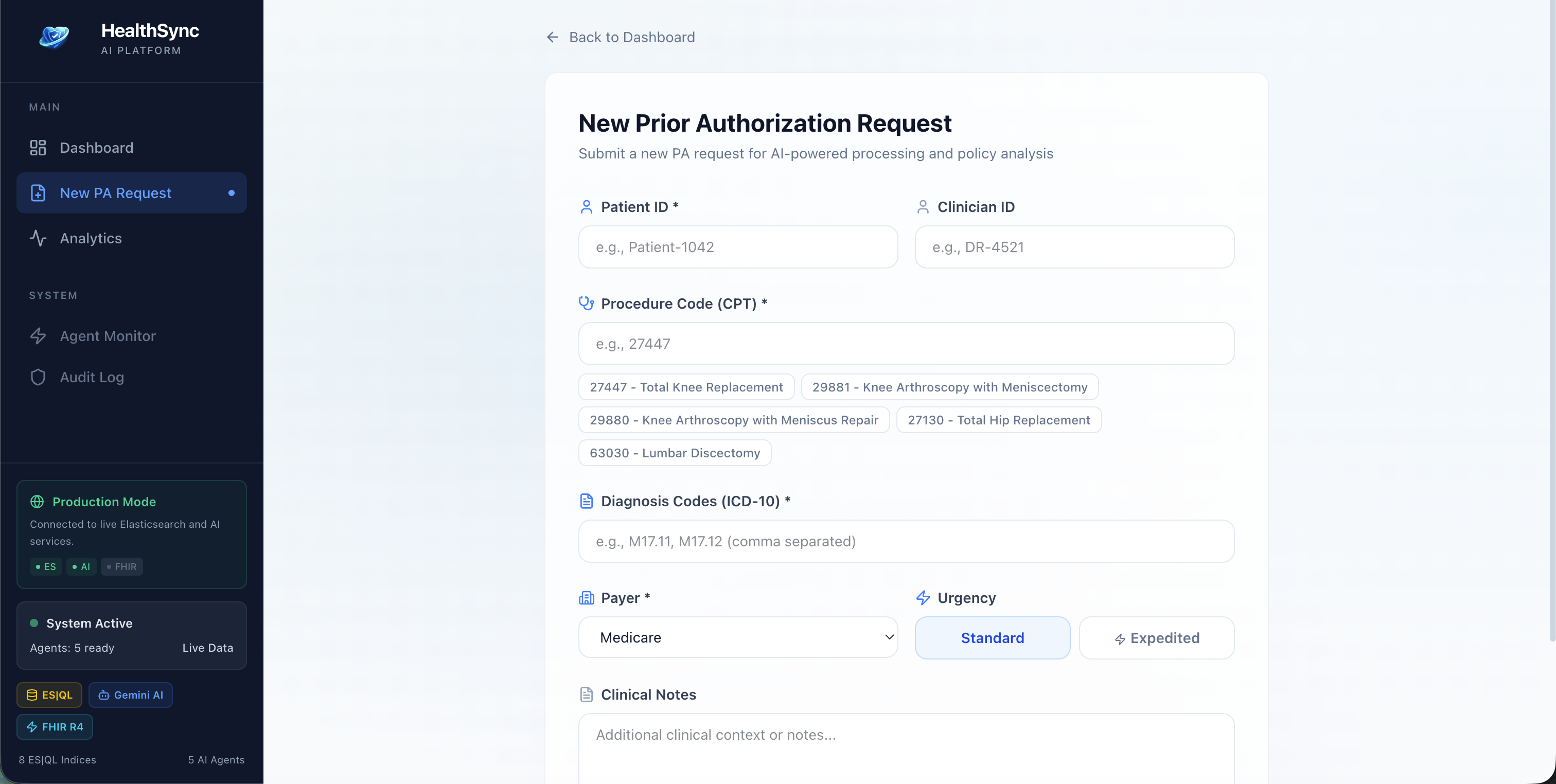
New Request
-
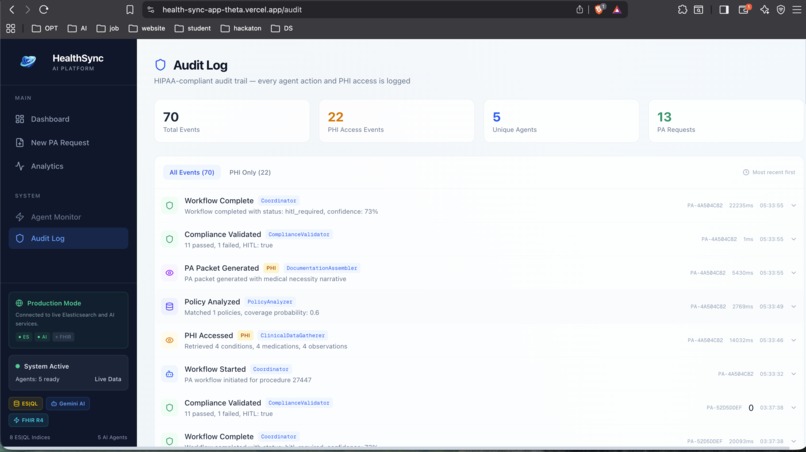
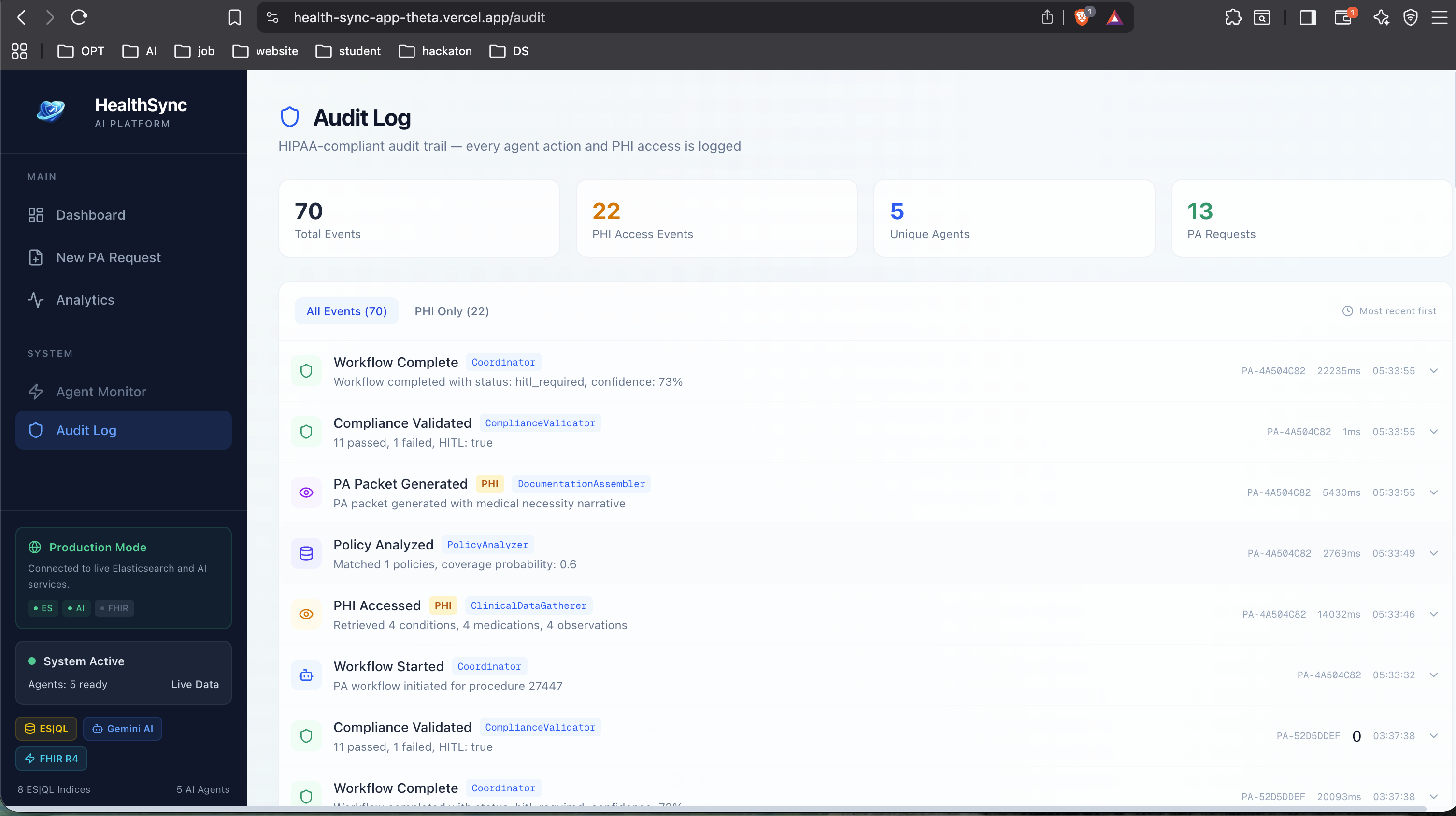
Audit Log List
-
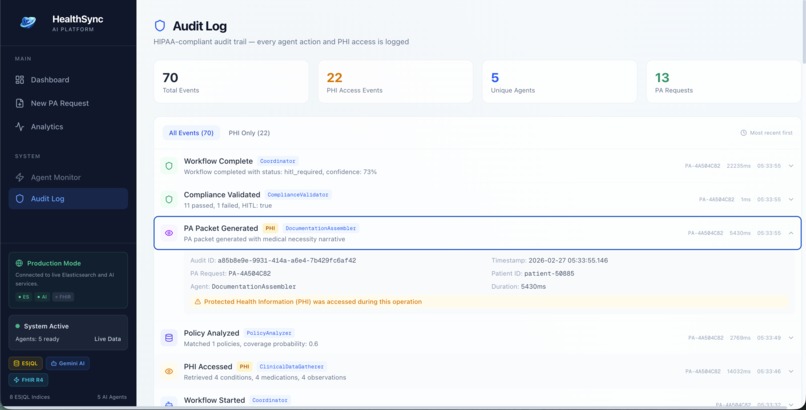
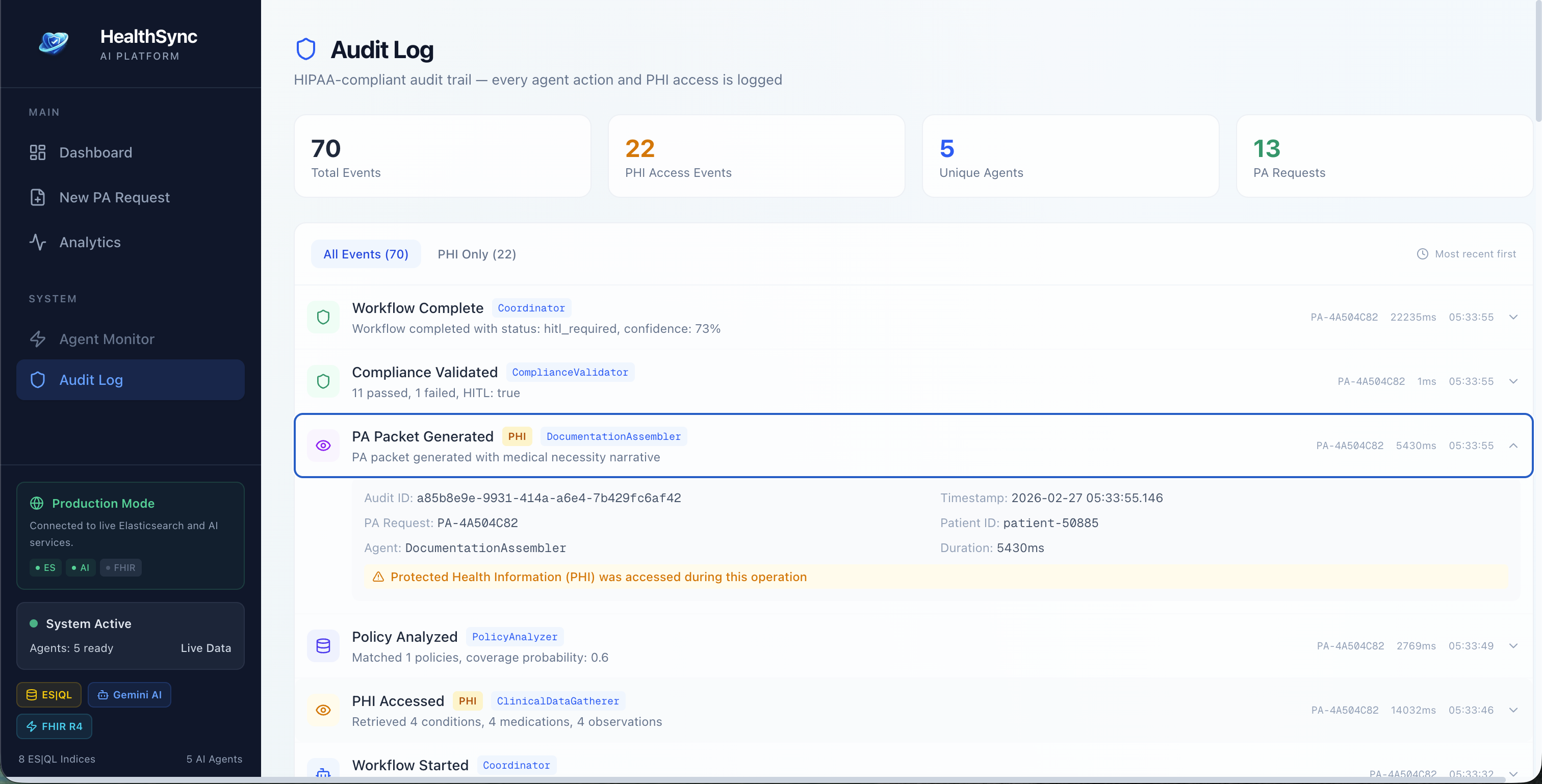
Audit Log Detail
-
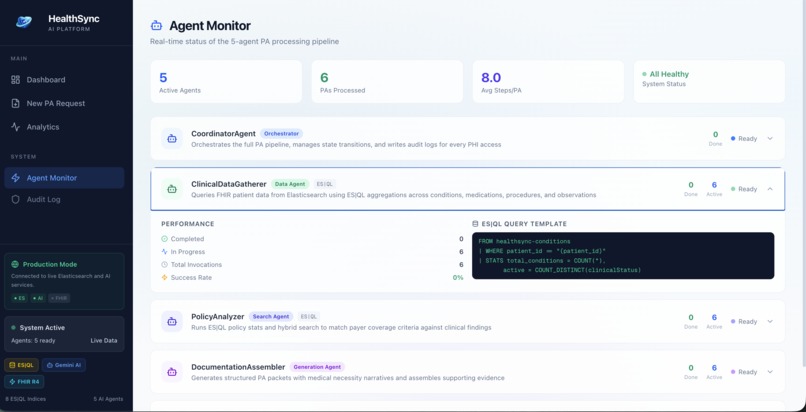
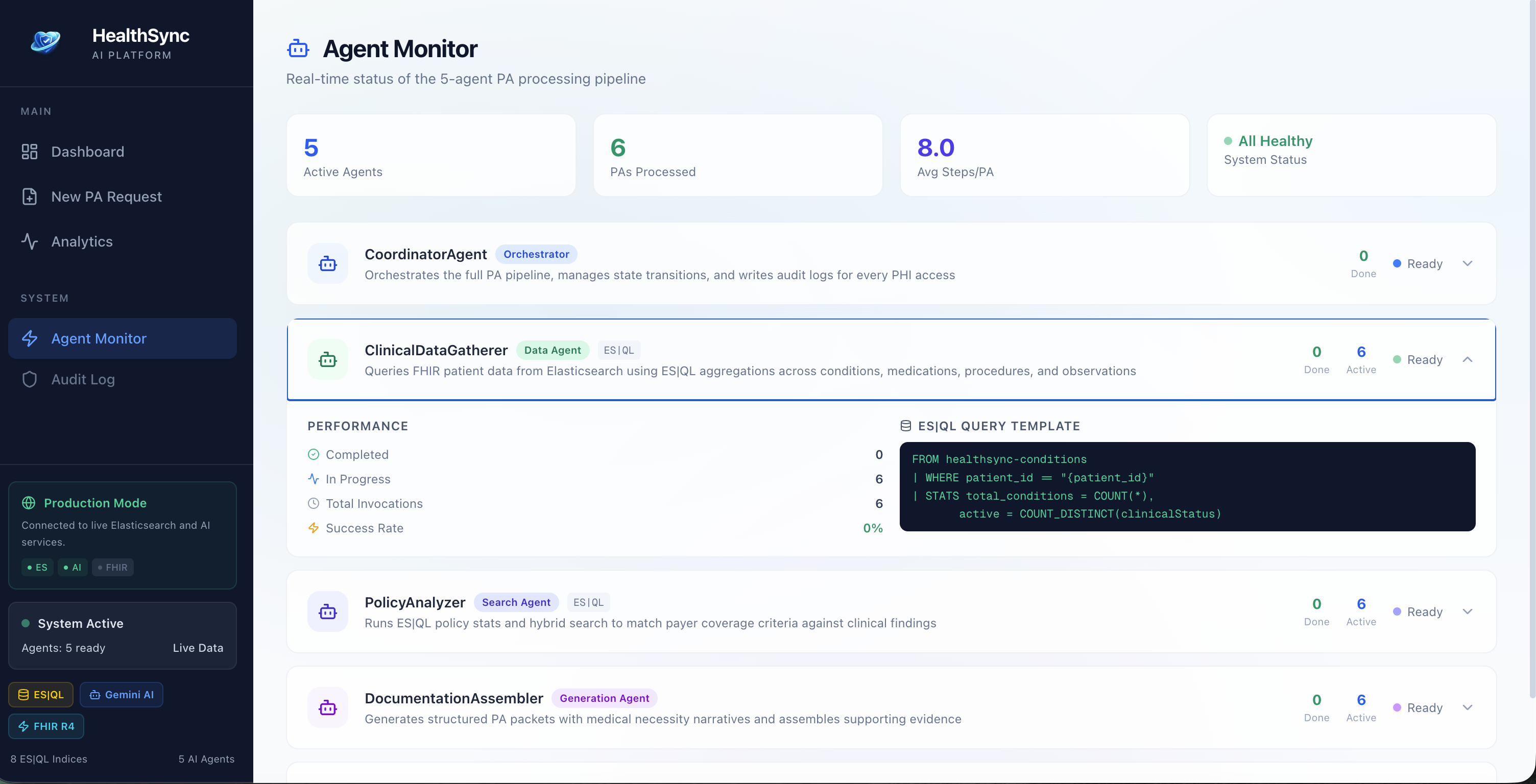
Agent Monitor Detail
💡 Inspiration
I work adjacent to healthcare - and prior authorization kept coming up as this frustrating, expensive, almost comically broken process. Doctors spend 13+ hours a week filling out paperwork just to get insurance approval for treatments they've already decided patients need. 94% of physicians say it's caused care delays. A third say it's led to serious adverse patient outcomes.
$150 billion a year. Burned on fax machines, phone hold music, and PDF forms.
When I saw this hackathon was about building multi-step agents that actually do things - not just answer questions - prior authorization jumped out immediately. It's genuinely multi-step. It touches multiple data sources. It has real compliance requirements. It's exactly the kind of messy, fragmented workflow agents are built to fix.
I wanted to see if I could build something that actually handled it end-to-end, with full transparency into what the agents were doing at every step.
⚙️ What It Does
HealthSync App replaces the manual prior authorization workflow with a pipeline of 5 specialized AI agents orchestrated through Elasticsearch:
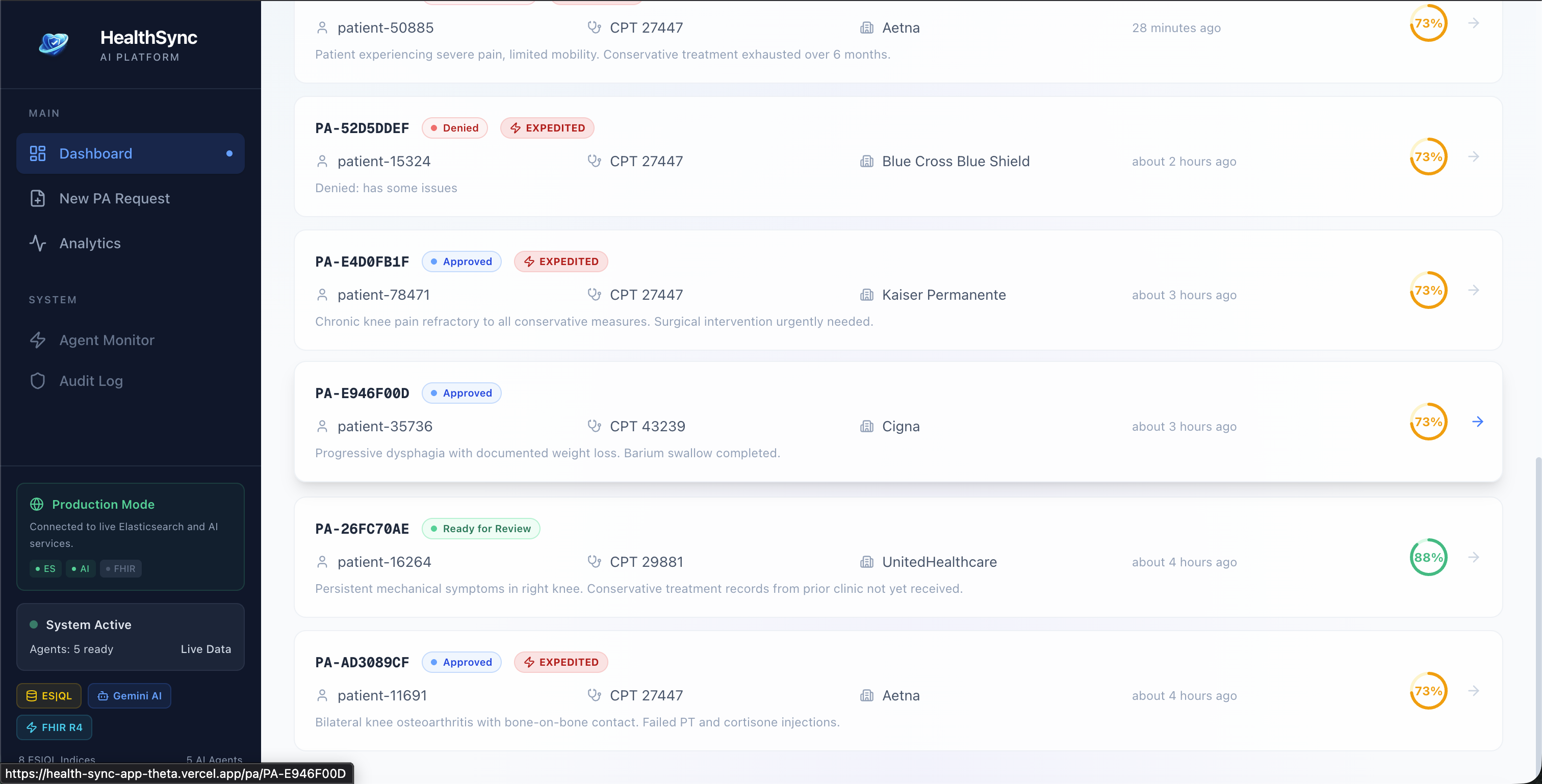
Clinical Data Gatherer - Pulls patient records across FHIR R4 indices using ES|QL, aggregating conditions, medications, procedures, and lab results into a single clinical picture. Policy Analyzer - Uses hybrid search to match the patient's case against payer coverage policies, then scores the probability of approval. Documentation Assembler - Generates a structured PA packet with a medical necessity narrative, written in the format insurers actually want. Compliance Validator - Checks CMS timeline rules (72-hour expedited / 7-day standard), flags borderline cases for human review, and decides whether the case can auto-proceed or needs a clinician in the loop Coordinator Agent - Orchestrates the whole pipeline, manages state transitions, and writes a full audit trail for every action and every piece of PHI accessed. When a clinician submits a request, the agents run end-to-end in minutes. High-confidence cases get a decision immediately. Anything uncertain gets escalated with the full reasoning chain visible to the reviewer - they can see exactly why the agents were uncertain.
A few features I'm particularly proud of:
ES|QL Query Inspector - every agent step and analytics chart shows the actual ES|QL query it ran. Full transparency, no black box. HIPAA Audit Log - every PHI access is logged with timestamps, agent ID, the query that ran, and expandable detail rows. There's a "PHI Only" filter to isolate just those events. Demo Mode - the entire pipeline runs with zero external services. Realistic synthetic clinical data, policy matching, and compliance decisions, all generated locally. Makes it easy to try without needing an Elasticsearch cluster.
🔨 How We Built It
The core of the system is Elasticsearch doing three distinct jobs at once:
ES|QL for cross-index clinical data aggregation - FROM healthsync-conditions | WHERE patient_id == "..." | STATS total_conditions = COUNT(*) kind of queries across 8 indices Hybrid search (BM25 + vector) for matching patient profiles against payer policies Audit logging - every agent action written back to a dedicated index for HIPAA traceability The agent layer is built in TypeScript with a BaseAgent class that each specialized agent extends. The CoordinatorAgent owns the state machine and runs the pipeline sequentially, passing context between agents. Each agent emits structured events that feed into the audit log.
The frontend is Next.js 16 with the App Router. The dashboard uses SWR polling every 5 seconds for live updates, and there's a Server-Sent Events stream for real-time PA status changes while a request is processing. Server Components handle SSR data fetching, Server Actions handle mutations.
Gemini 2.0 Flash handles the language-heavy work - generating medical necessity narratives, extracting coverage criteria from payer policy documents, and evaluating clinical evidence quality.
Patient data is stored in FHIR R4 format via a HAPI FHIR server (Docker), and gets indexed into Elasticsearch via a pipeline script that maps FHIR resources to Elasticsearch documents.
🚧 Challenges We Ran Into
FHIR + Elasticsearch mapping was messier than expected. FHIR resources are deeply nested JSON with extensions, codings, and references - flattening them into flat Elasticsearch documents without losing clinical meaning took a few iterations. Things like code.coding[0].display feel obvious until you're writing ES|QL queries against them.
ES|QL's current limitations - I wanted to do joins across indices (e.g., pull all conditions for patients who also have a specific medication), but ES|QL doesn't support cross-index joins yet. I had to restructure some agent queries to do multi-step lookups: fetch patient IDs first, then query each index separately and merge results in application code. Not elegant, but it works.
Making HITL (human-in-the-loop) feel real - It's easy to build a system that auto-approves everything. The harder part was making the confidence scoring and escalation logic actually meaningful. Low-confidence escalations had to carry enough context that a human reviewer could understand why it was escalated without re-reading the entire chart.
Demo mode parity - I wanted demo mode to feel identical to the live mode, not obviously fake. That meant generating realistic synthetic clinical data that had internal consistency - patients whose conditions matched their medications, lab values in plausible ranges, denial reasons that made clinical sense.
🏆 Accomplishments That We're Proud Of
The ES|QL Query Inspector was one of those features that started as a debugging tool and ended up being one of the most compelling parts of the demo. Watching a judge see the actual query that the agent ran - FROM healthsync-policies | WHERE payer_id == "Aetna" | STATS avg_coverage_rate = AVG(coverage_probability) - and understanding exactly how the policy match worked, that transparency matters. Healthcare is a trust-sensitive domain.
The HIPAA audit trail is genuinely production-grade in its design. Every PHI access is logged with agent identity, timestamp, the ES|QL query that retrieved the data, and the purpose. The PHI-only filter makes compliance review fast.
And honestly - getting 5 agents to coordinate across 8 indices and produce a coherent, explainable PA decision in under 30 seconds in demo mode felt like the thing finally working the way I imagined it at the start.
📚 What We Learned
ES|QL is genuinely powerful for analytical queries but has a different mental model than SQL - you work in pipelines (| chaining), not JOINs, and aggregate functions compose differently. Once it clicked, writing clinical aggregation queries felt natural.
Building for a regulated domain (healthcare, HIPAA) changes how you think about logging. It's not optional telemetry - it's a first-class requirement. Designing the audit log as part of the core agent architecture, not as an afterthought, made everything cleaner.
Multi-agent orchestration is mostly a state machine problem. The hard parts aren't the individual agents - it's error handling, partial failure recovery, and making sure the coordinator doesn't leave a PA request in a half-processed state if one agent throws.
🔮 What's Next for HealthSync App
Real EHR integration - connecting to Epic and Cerner via SMART on FHIR OAuth so clinicians can submit directly from their existing workflow Payer API integration - direct X12 278 submission to major payers instead of generating packets for manual upload Denial prediction - a pre-submission agent that estimates denial risk and suggests documentation improvements before the PA is even sent Multi-language narratives - medical necessity letters in Spanish, Mandarin, and other languages for non-English-speaking patients and payers
Built With
- docker
- elasticsearch
- esql
- fhir-r4
- framer-motion
- gemini-2.0-flash
- gemini-ai
- hapi-fhir
- next.js
- react-hook-form
- recharts
- server-sent-events
- swr
- tailwind-css
- typescript
- vercel
- zod



Log in or sign up for Devpost to join the conversation.