The Making of the HealthLit Engine
Source code can be found here: https://github.com/lindazy/vandyhacks2015
The Authors
Linda and Alex are first year biomedical informatics PhD students! We are extremely interested in applying data mining and analytic techniques to healthcare data. We have a couple physician friends, which are the inspiration of this study.
Problem
Medical knowledge is constantly changing. In this domain, one of the most difficult tasks for physicians and healthcare professionals is keeping up with the most current literature. In fact, with the growing amount of research, hardly anyone has enough time to scroll through the hundreds of articles published every month. In addition, even for a given topic, many articles are not relevant to what a healthcare provider is interested in. Even so, the provider needs to skim through all the articles to find out.
Method
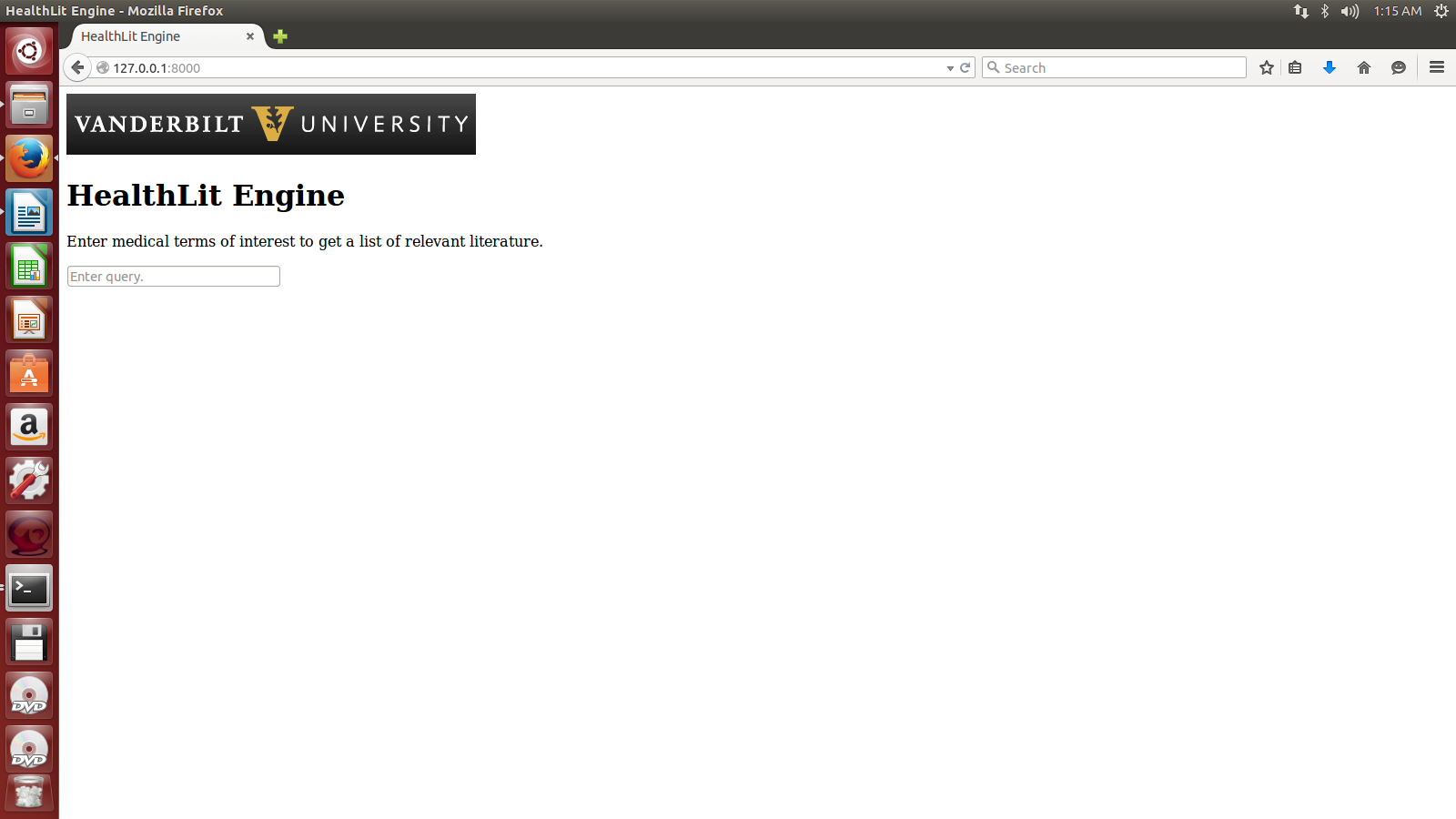
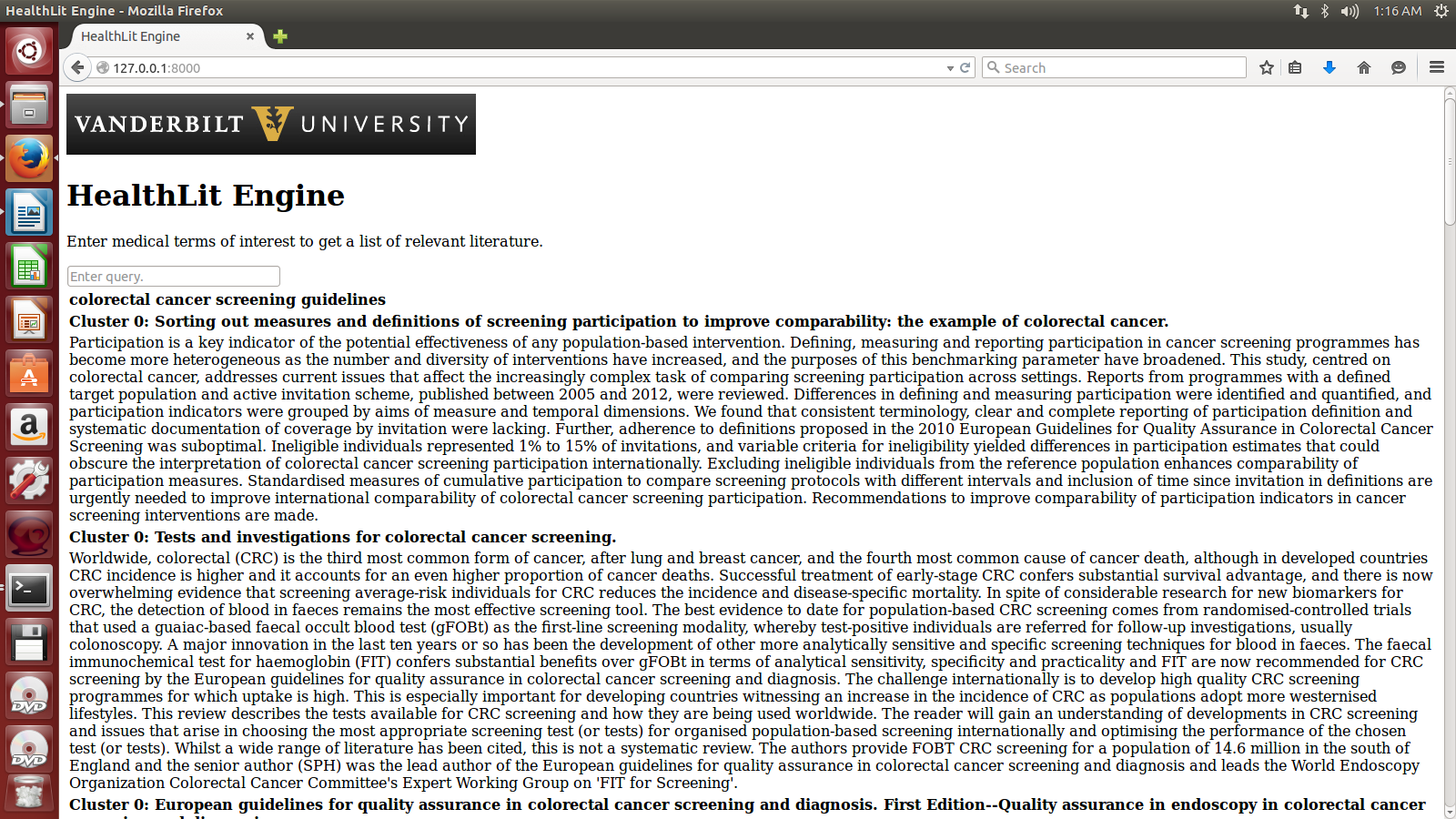
In order to help physicians and healthcare professionals keep up with the latest literature in their field in a comprehensive and efficient manner, we have designed the HealthLit Engine. Instead of performing a manual search on for their topic of interest, healthcare professionals can issue a query in their area of interest on the HealthLit Engine and receive articles with abstracts clustered into groups of similar topic.
To cluster the papers, we used the k-means clustering algorithm from python's sci-kit learn package for machine learning. The papers are clustered by their Medical Subject Headings (MeSH), which is the NLM controlled vocabulary thesaurus used for indexing articles for PubMed. MeSH terms are categorized into 16 groups, which we turned into features of the input matrix. We uploaded all the MeSH terms and their categories to our server's database. Then, when papers are pulled from PubMed, their feature vectors are calculated as binary vectors for existence of a term in that category. These feature vectors are used to make the input matrix for the k-means clustering algorithm, which then predicts how to cluster the papers. We set the number of clusters to 3 for simplification.
Results
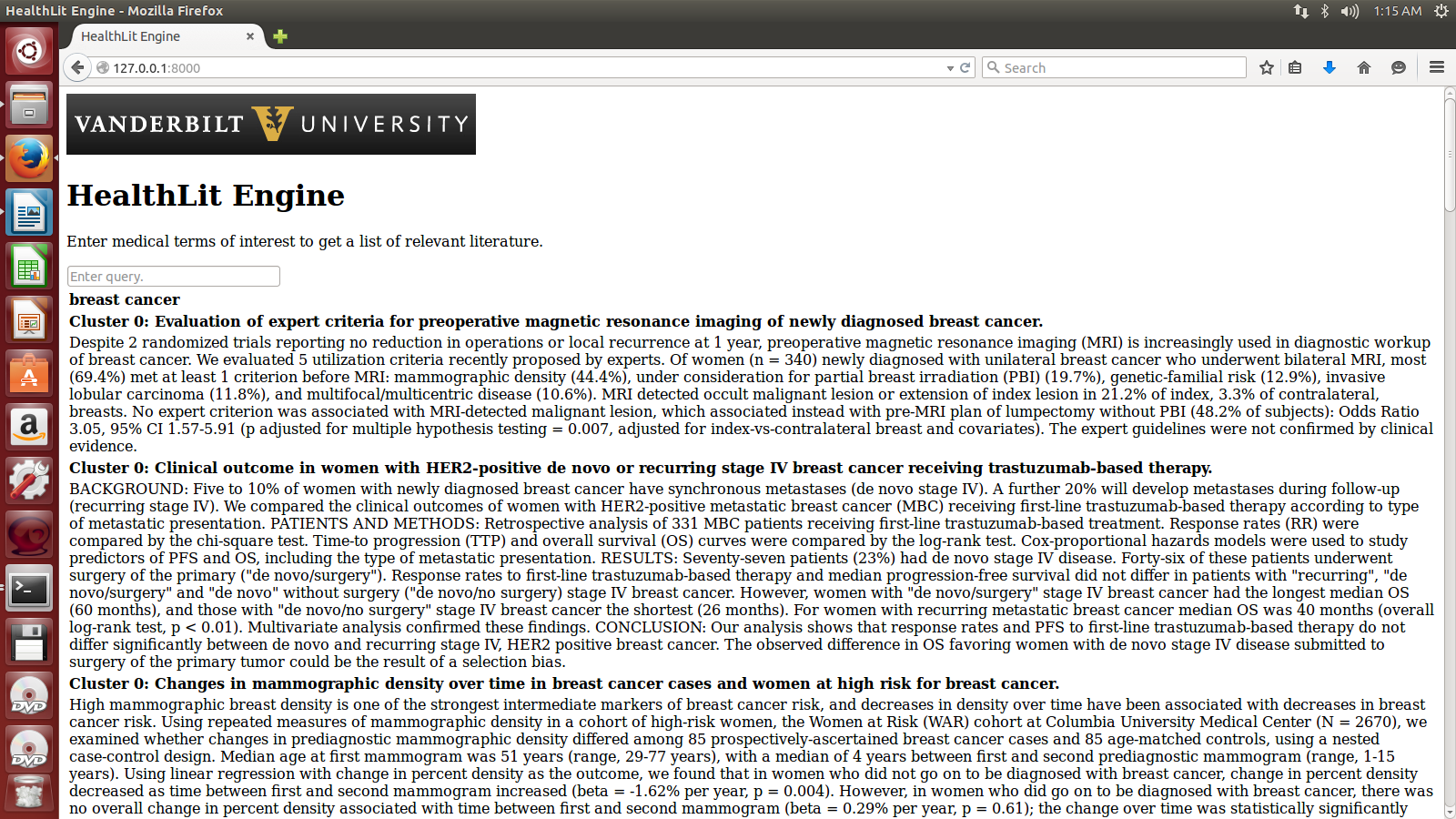
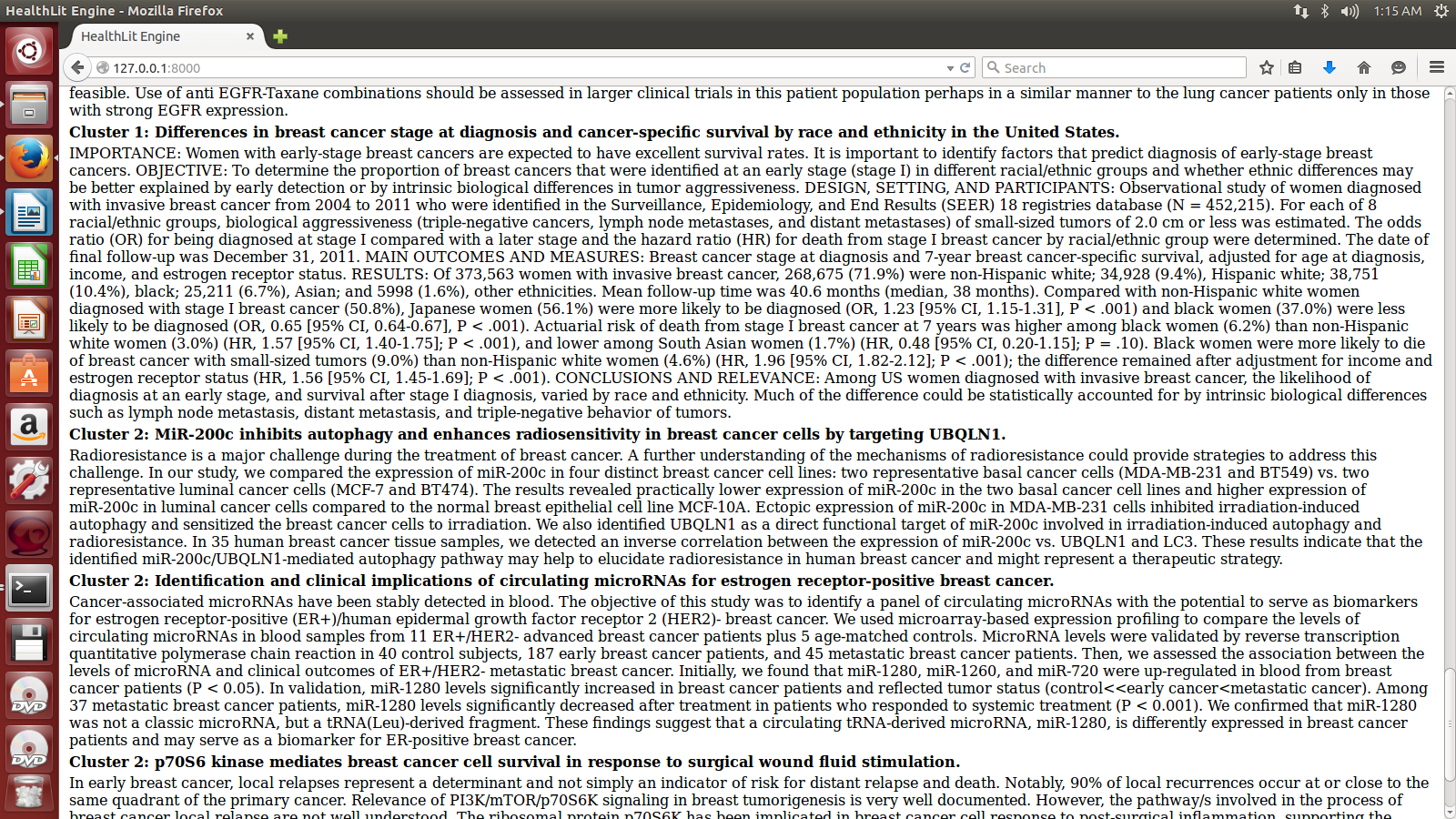
We found that, on a test disease of breast cancer, the clusters seemed to be fairly meaningful and accurate. The papers were grouped into 3 categories, that seemed to be:
- Treatment, drug, factor studies.
- Quality insurance, screening, cohort studies.
- mRNA and protein studies.
We really can't say anything definite about the results without a statistical test/expert opinion though.
Conclusion
If a user takes about 1 minute to skim an article, using HealthLit Cluster can save them about 15 minutes every time they look through 15 pieces of literature. That may not seem like a lot, but an extra 15 minutes allows that physician to see one more patient in a day. Across all the medical professionals and researchers across all medical centers, the sum of these time savings can make a significant financial and public health impact.
Built With
- digital-reasoning
- django
- epic
- html
- javascript
- machine-learning
- nashville-spirit
- python
- rustici
- scipy
- sqlite

Log in or sign up for Devpost to join the conversation.