-
-
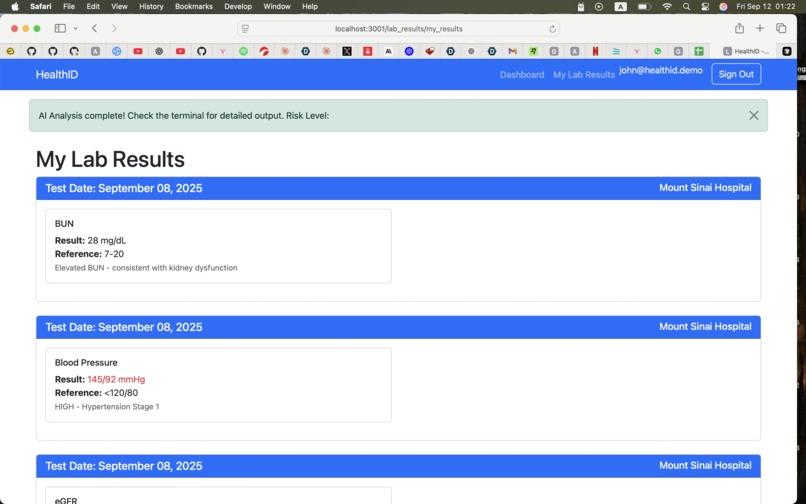
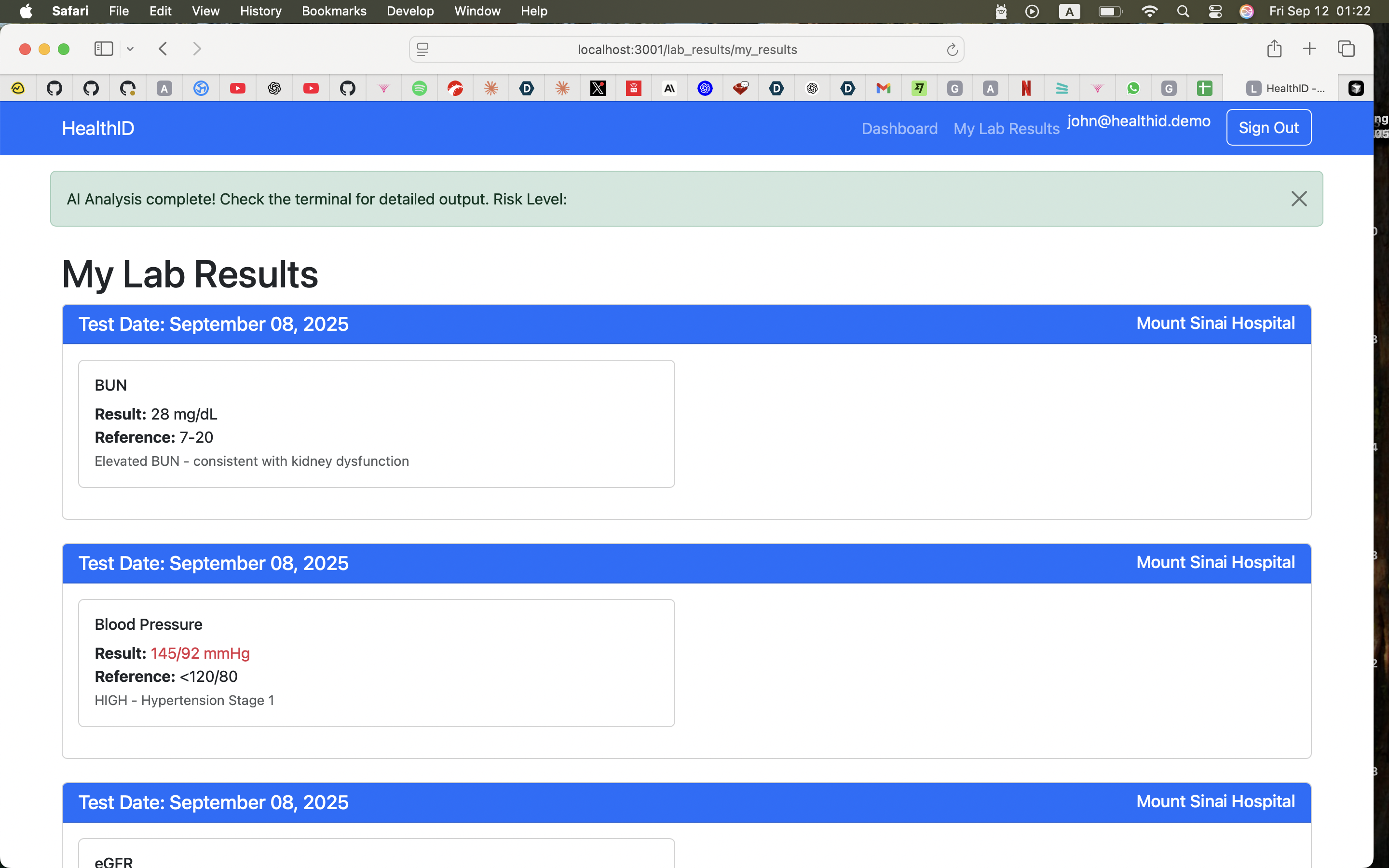
Lab results page
-
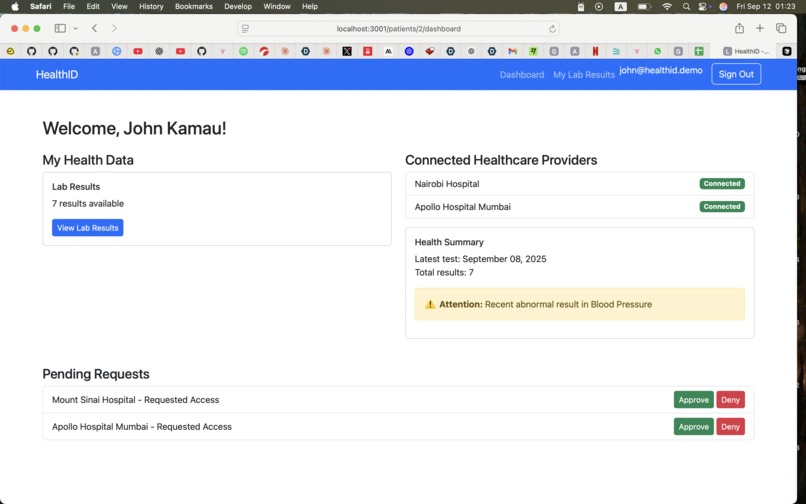
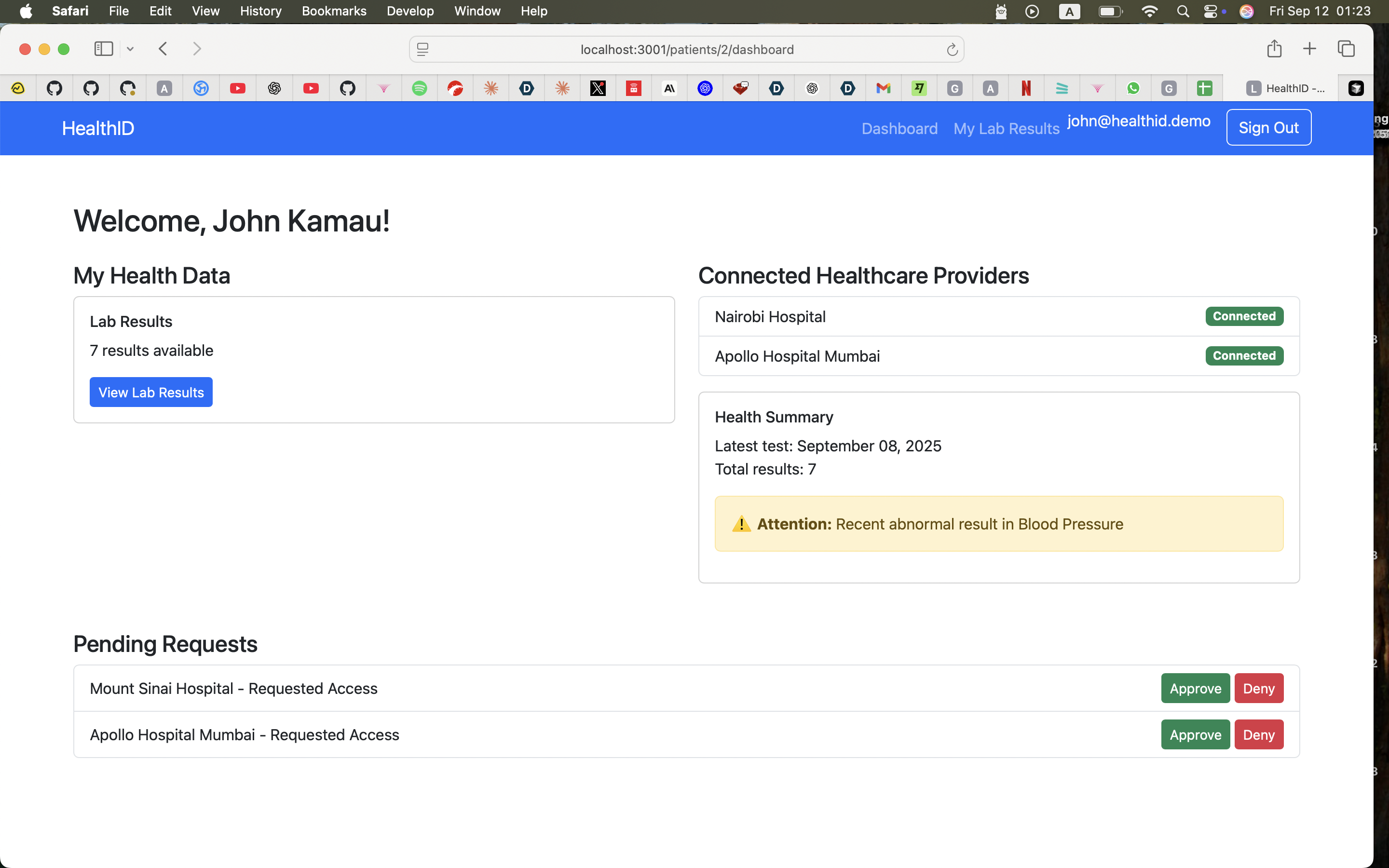
Main patient dashboard
Inspiration
A friend traveling from Nairobi to Mumbai for work fell ill and needed emergency care. The Mumbai hospital had no access to his recent lab work showing a liver condition, so they ordered the same expensive tests again. This made us realize: people carry smartphones everywhere, but their medical data is just static files. What if we could use gpt-oss-20b to turn that phone into an intelligent health assistant that works offline?
What it does
HealthID transforms your device into a private medical AI assistant using gpt-oss-20b running locally. It:
- Stores medical records as verifiable credentials with cryptographic signatures
- Analyzes lab results using gpt-oss-20b to identify patterns across multiple tests
- Generates instant summaries for emergency situations
- Works completely offline - all AI processing happens on your device
How we built it
We combined Ruby on Rails for the credential system with gpt-oss-20b for local intelligence:
- Backend: Rails 7 API with PostgreSQL for verifiable credential management
- Local AI: Python wrapper calling gpt-oss-20b through Ollama's API
- Integration: HTTP calls from Rails to local Ollama instance (localhost:11434)
- Model serving: Ollama running gpt-oss-20b with 4-bit quantization The architecture keeps medical data local while still providing intelligent analysis through the on-device model.
Challenges we ran into
MacBook Air M1 with 8GB RAM couldn't handle gpt-oss-20b: The model needed 13GB+ RAM. We had to use aggressive quantization (Q4_0) and still faced constant memory pressure. Eventually switched to testing on a borrowed 16GB machine.
- Ollama kept crashing: When processing longer medical documents, Ollama would terminate unexpectedly. Fixed by limiting context window to 2048 tokens and chunking documents.
- Response times were terrible: Initial inference took 30-45 seconds on the MacBook Air. Even with optimization, couldn't get below 15 seconds for complex medical queries.
- Model hallucinated medical values: gpt-oss would sometimes invent lab values that weren't in the input. Had to implement strict output parsing to catch and filter these.
- Rails-to-Python integration issues: Subprocess calls from Rails to Python script were unreliable. Switched to running Ollama as a service and using HTTP API calls instead.
Accomplishments that we're proud of
- Got gpt-oss-20b running locally: Successfully integrated Ollama with Rails, despite the memory constraints
- Implemented verifiable credentials: Built a working cryptographic signature system for medical records. Paused for the purpose of this hackerthon.
- Created structured medical prompts: Developed a prompt format that reduces hallucinations in medical contexts
- Built a working prototype: The system can actually analyze a lab report and generate insights (even if slowly)
- Achieved offline operation: Entire stack runs without internet connection
What we learned
- gpt-oss-20b is HEAVY: Need at least 16GB RAM for decent performance, 32GB ideal
- Quantization has limits: Q4_0 quantization degrades medical reasoning quality significantly
- Ollama simplifies deployment: Much easier than trying to run raw model files
- Medical prompts need strict formatting: Free-form prompts lead to dangerous hallucinations
- MacBook Air isn't for LLM development: 8GB RAM is simply not enough for 20B parameter models
What's next for HealthID
- Try gpt-oss-7b: Smaller model that could actually run on normal laptops
- Implement proper chunking: Handle large medical documents without crashes
- Add response caching: Store common medical queries to avoid re-inference
- Fine-tune on medical data: If we can get access to medical datasets
- Build proper API layer: Replace subprocess calls with proper message queue


Log in or sign up for Devpost to join the conversation.