-
-
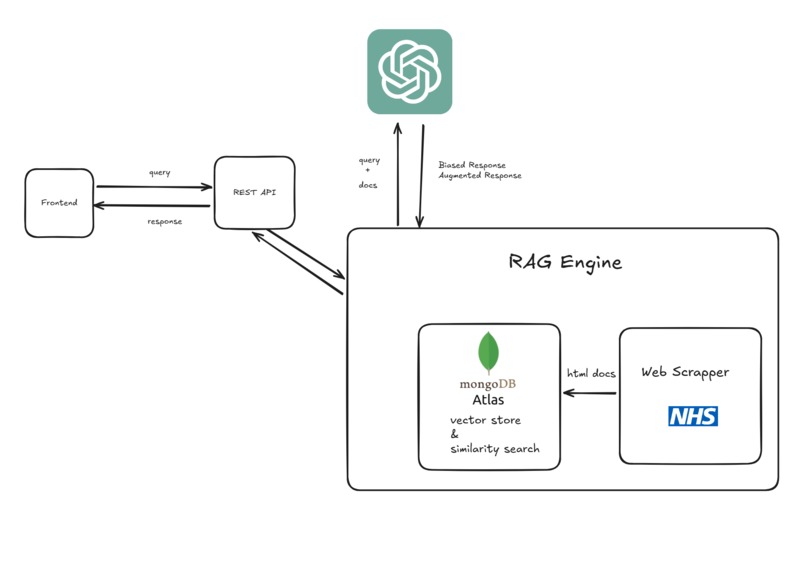
Healthcare Assistant RAG model
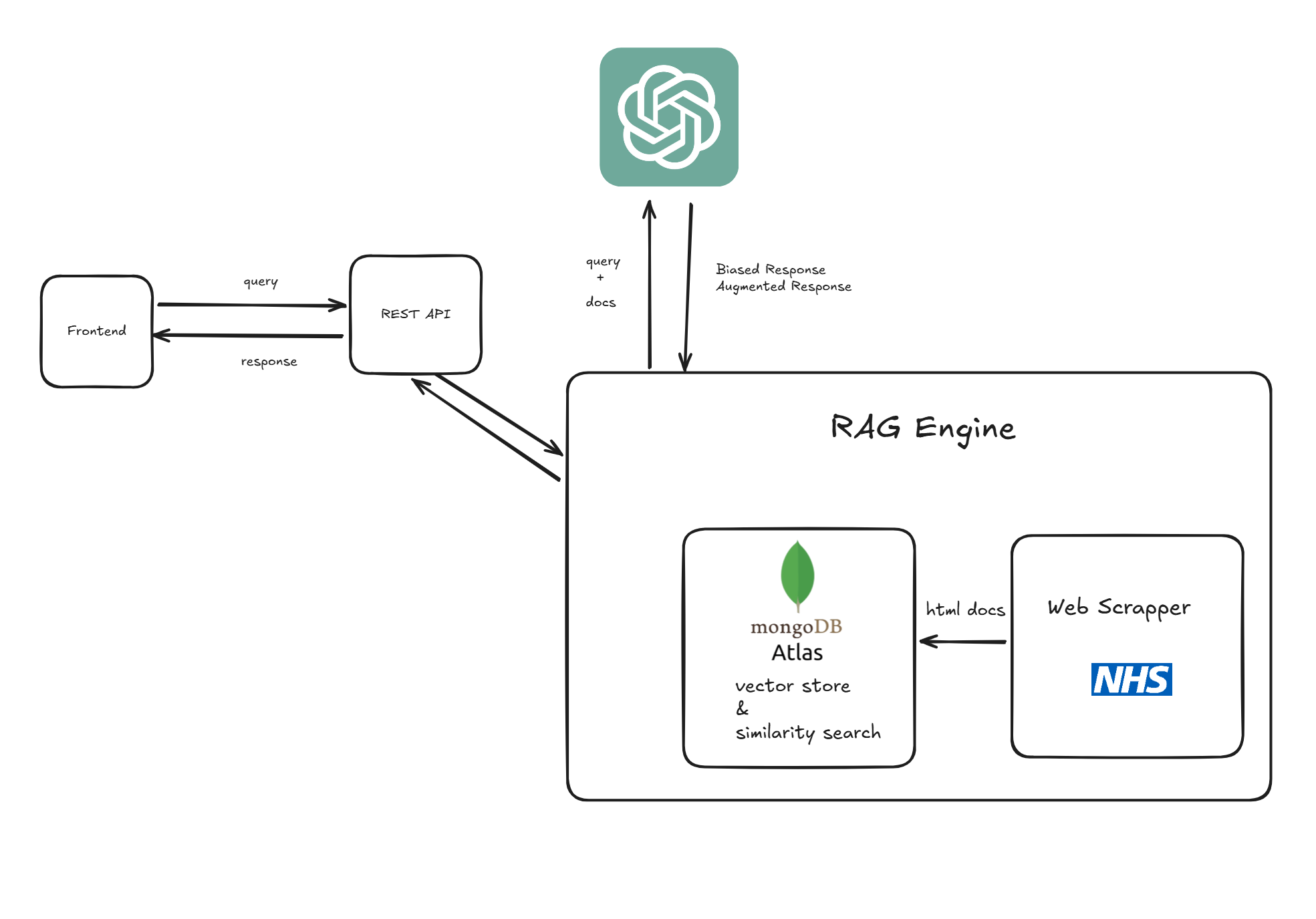
Healthcare Assistant RAG Model
Inspiration
I would often find myself on this website, going through symptoms or medical conditions I was experiencing, such as prolonged cold or cough, reading through medical advice and recommended medicines. The website contains more than 1,000 medical conditions, providing advice, self-care tips, treatment options, and more. This inspired me to build a RAG model around this knowledge base.
What It Does
The Healthcare Assistant RAG Model allows users to input healthcare-related queries and receive personalized, AI-enhanced responses. It retrieves relevant documents from the NHS A-Z knowledge base, processes the query alongside these documents, and generates an informed, contextually accurate reply.
How We Built It
We built the system in stages:
- Data Scraping: Scraped unstructured, textual data from the NHS A-Z website, which includes advice on medical conditions, possible treatments, and self-care routines.
- Database Setup: Stored the data in MongoDB Atlas with vector embeddings and created a vector search index.
- RAG Engine: Used LangChain to integrate relevant documents retrieved from MongoDB with an LLM to generate personalized responses, complete with actual sources of information.
Challenges We Ran Into
- Scraping data from HTML pages with no defined structure for the text content.
- Tying the RAG engine with a REST API.
Accomplishments That We're Proud Of
- Building a full-stack, LLM-powered application.
- Successfully working and collaborating as a team.
- Leading a team to deliver the project.
What We Learned
- Developing a complete RAG pipeline from data ingestion to response generation.
- Overcoming challenges in web scraping and unstructured data handling.
- Efficient use of embeddings and vector similarity search using MongoDB Atlas Vector Search.
- Effective teamwork and leadership in a hackathon setting.
What's Next for Healthcare Assistant RAG Model
- Enhance the web scraper to update data periodically from the NHS website.
- Add multi-language support for a wider audience.
- Incorporate additional healthcare datasets to improve the breadth of information.
- Optimize the embedding generation and similarity search processes for faster responses.
- Expand the functionality to include voice-based interactions and mobile app support.
Built With
- beautiful-soup
- fastapi
- langchain
- mongodb
- python
- react


Log in or sign up for Devpost to join the conversation.