-
-
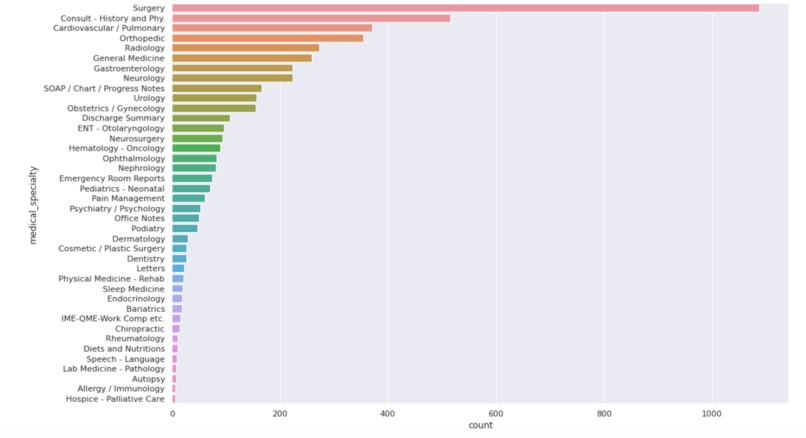
Record counts in the MTSamples dataset
-

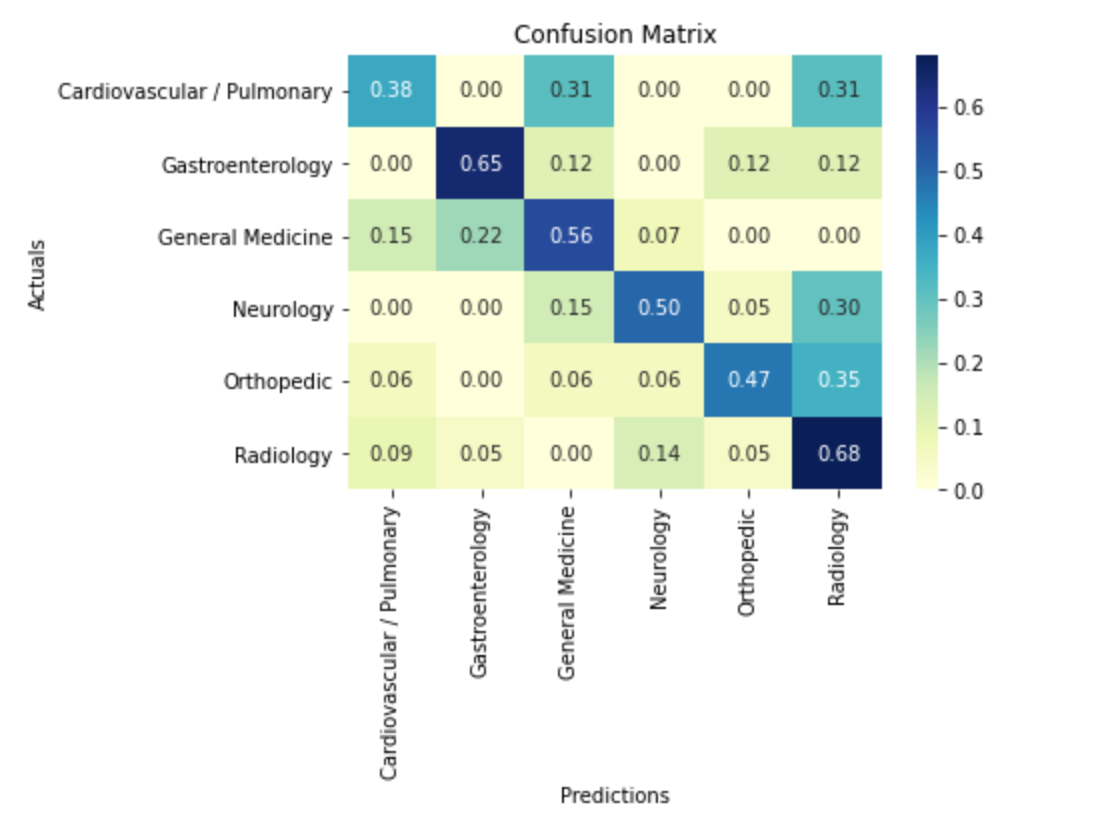
Confusion Matrix - Test data

Inspiration:
Following up daily on how my father's Parkinson evolved over the last decade and how it impacted his day-to-day life was something that lead me to think of what AI could do to support health care industry. There is tremendous amount of digital data about patients conditions, medications and how the conditions evolve. There are many people who would go through similar situations and if that can be found it might be able to help another patient.
During the cause I have searched about illnesses, symptoms, health conditions, nutrition, exercises related information on the internet, and I am sure many of you might have done that to help someone you love or for you. The available health data can be used to create a knowledge base and use machine learning to gather the knowledge from previous cases to help people with similar conditions.
What it does:
The project is aimed to support the following scenario. The user can input information about health conditions, symptoms, prescriptions in a medical report given as web form input (this then need to be saved as a pdf file) or as an uploaded pdf file in order to identify the health condition. This electronic medical record(EMR) will be run against Comprehend Medical to extract medical keywords from the EMR which will be run through the machine learning (ML) model to identify the health classification. This classification and features can be used to provide recommendations on health professionals contacts, possible nutrition, exercises, therapies etc by health service providers.
The demonstrated implementation has trained a model for health record classification so that the medical report given from the user input can be classified to identify the health speciality which can be used to provide health recommendations.
How we built it:
Data: I have used the MTSamples transcription data related to the below six medical domains that has more than 200 samples each to train the model. I have omitted surgery and consultation categories as they are generic health domains though they have the highest number of samples.
1: "Cardiovascular / Pulmonary"
2: "Orthopedic"
3: "Radiology"
4: "General Medicine"
5: "Gastroenterology"
6: "Neurology"
Technical implementation: The ML model implementation has two parts.
Batch processing of medical text using Amazon Comprehend Medical: HHBatchDataProcessing.ipynb This code will read mtsamples data and query Comprehend Medical to extract medical related information in the text of the randomly chosen records from the selected categories. This extracted data is then saved as a csv file to be used in the model training. (note: The comprehend medical usage in this notebook costs around $100 to pass all records! Therefore if you want to test I suggest that you may want to reduce the queries.)
Build, train and deploy a classification machine learning model with medical data extracted from the medical documents.: HHModelDeployment.ipynb I am using the linear learner multi class classification to train the model. I have demonstrated 2 inference use cases at the end of this notebook.
Inference: The following 2 inference use cases were tested.
- Medical report in English language: This can be passed directly to Comprehend medical to extract keywords.
- Medical report in German language. This need to be translated to English before passing to Comprehend medical.
The Comprehend medical extracted keywords are filtered to match the feature set used for training. Finally the prediction is done using the trained model and the saved endpoint.
Challenges we ran into:
Dataset limitations: I have used the MTSamples for training the model. I have picked 6 medical specialities having 200-400 samples, and then randomly picked 200 samples from each category for the dataset. I believe the predictions would be more accurate if the dataset included patient demographic data and health history, however I was not able to find such a public dataset.
Accomplishments that we're proud of:
With the limited dataset and identified few categories I have achieved an overall accuracy of 0.55 while having the highest individual category accuracy at 0.68.
What we learned
- How to use Comprehend Medical, Transcribe and Translate.
- Model training & endpoint setup in Sagemaker.
- Inference using the model.
What's next for ML classification model for Health recommendations
- Improve the model by comparing other algorithms. (e.g. XGBoost, AutoGluon)
- Work in Progress: XGBoost model using default parameters accuracy was 0.51 & best category 0.61.
- Build a UI to implement web input and show real-time prediction.
- Partner with a health professional to extend the idea to a particular domain to build a real life example.
References
AWS Comprehend Medical usage: https://github.com/aws-samples/amazon-textract-and-comprehend-medical-document-processing
AWS Linear Learner: https://github.com/aws/amazon-sagemaker-examples/blob/main/scientific_details_of_algorithms/linear_learner_multiclass_classification/linear_learner_multiclass_classification.ipynb
Inspiration on dataset and text analysis: https://www.kaggle.com/code/ritheshsreenivasan/clinical-text-classification/notebook

Log in or sign up for Devpost to join the conversation.