-
-
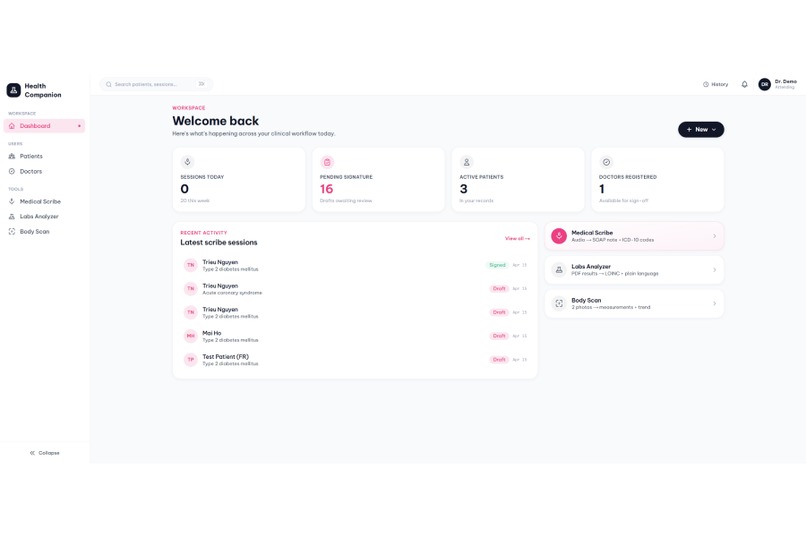
Homepage-Dashboard
-
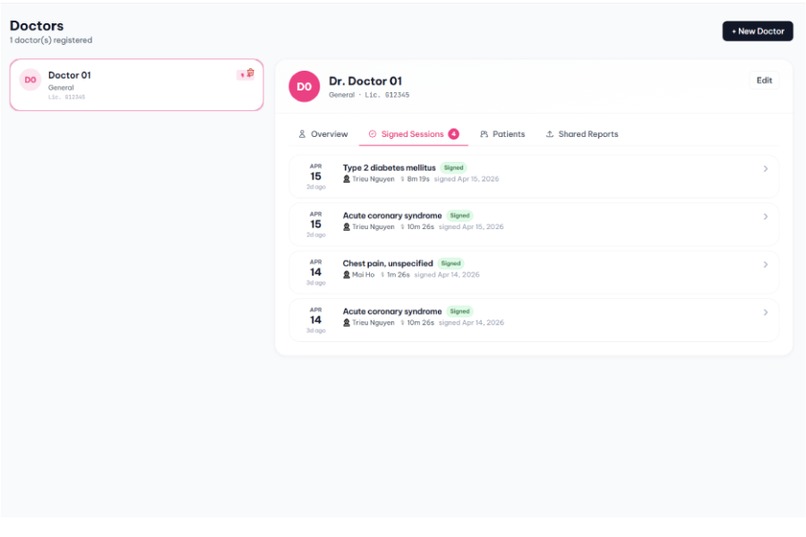
Doctors profile
-
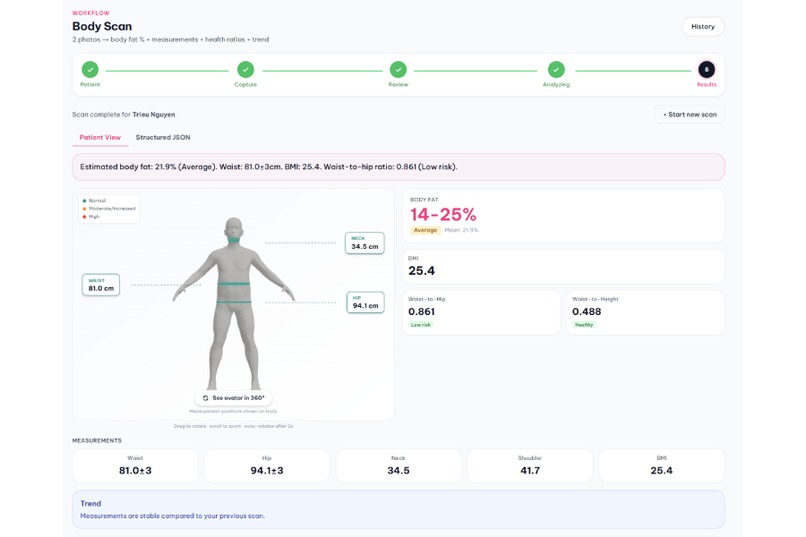
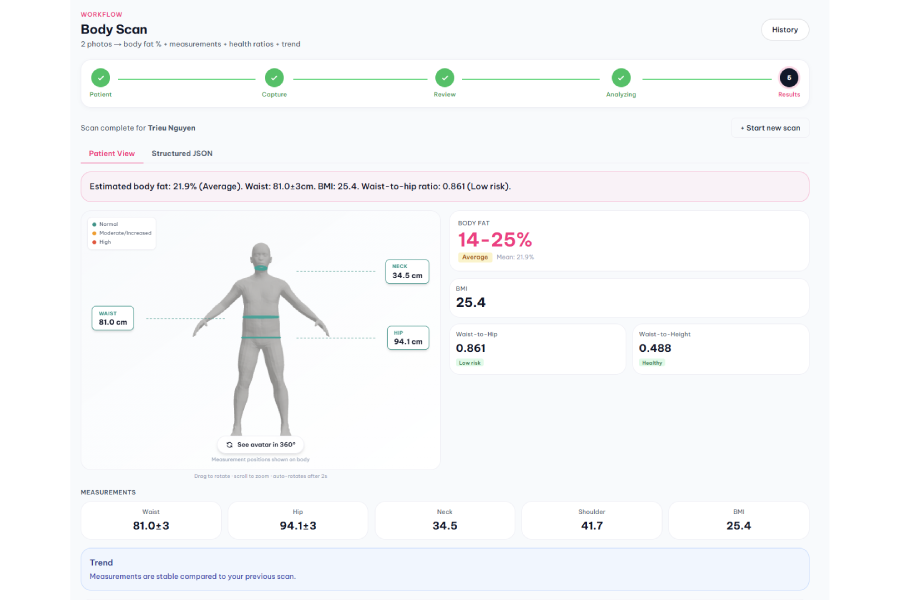
Final screen in Body scan
-
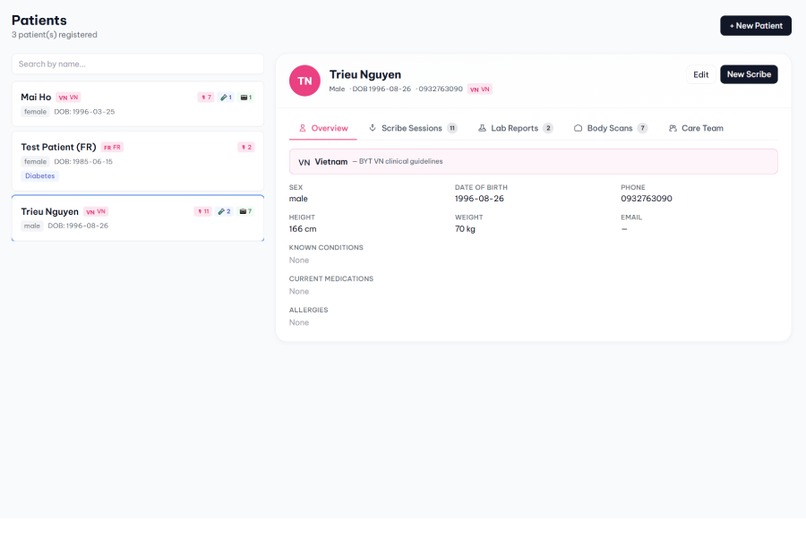
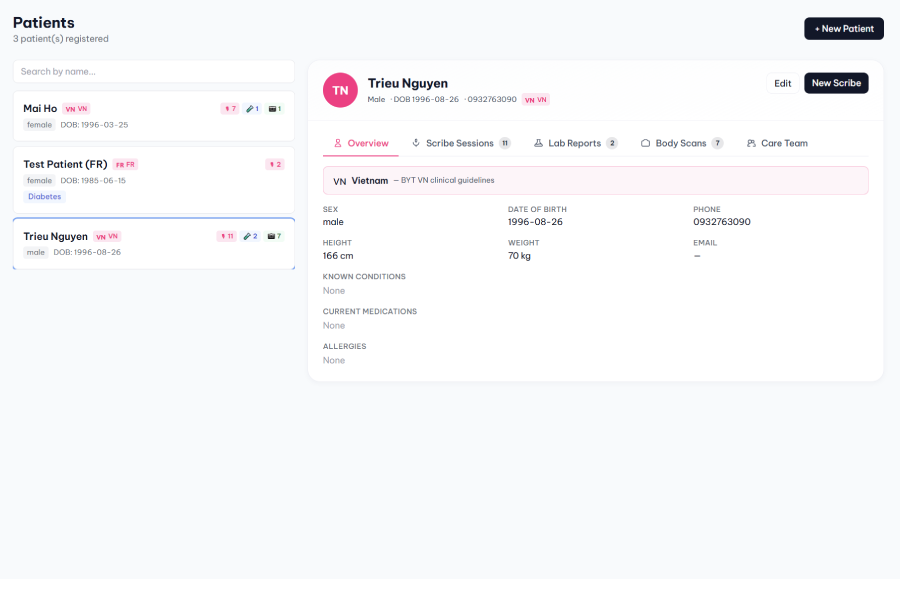
Patients profile
-
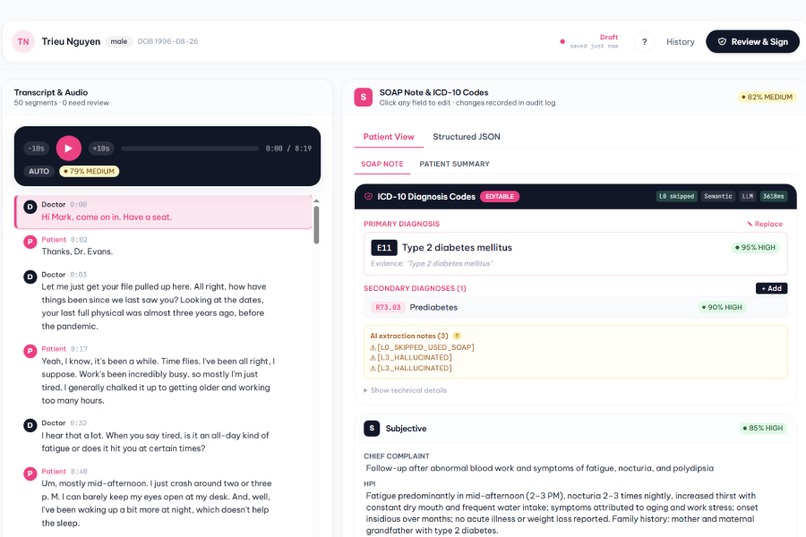
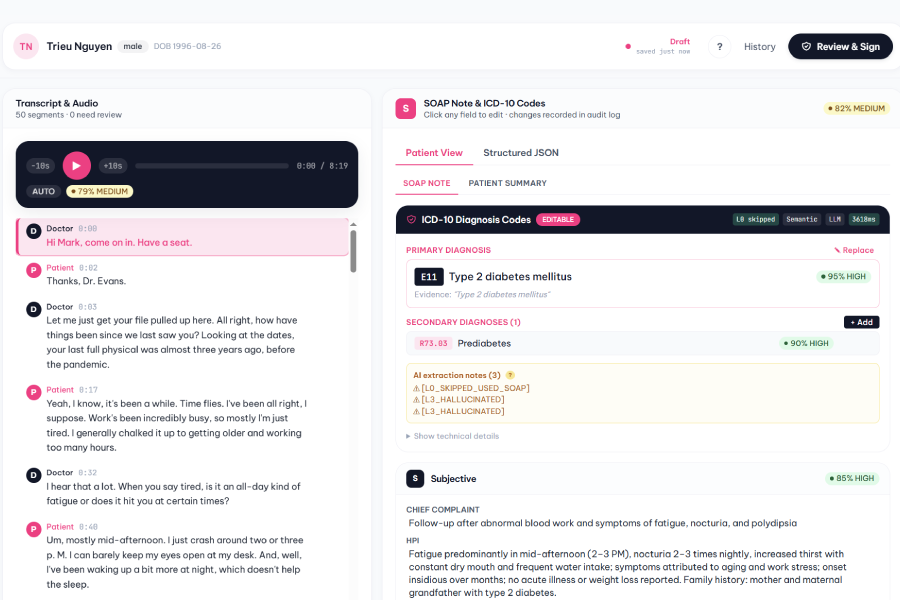
Final screen in Medical Scribe
About the project
Thesis. Not three AI tools — one clinical data-quality pipeline. Every encounter, on every surface, writes the same structured patient record that downstream systems can consume.
Inspiration
Healthcare data lives or dies on quality at the point of creation. A voice consultation, a lab printout, a body photo — each one should produce a trusted, structured clinical data point that downstream systems (reimbursement, research, underwriting) can actually consume. Today that data is born unstructured and gets retro-fitted into structure by hand, which is slow and lossy.
We wanted to ask a different question: what if the moment audio leaves the doctor's mouth, a lab PDF touches an upload box, or a patient points a camera at themselves, the system produced exactly the structured JSON downstream needs — not a pretty narrative, the actual data point?
That framing is what Health Companion is built around. Not three AI tools. ==One Clinical Data Engine with three capture surfaces==, all writing into one patient profile with one schema.
What it does
All three modules funnel into ==one unified ElfieData schema== — a dual
payload of patient_view (friendly narrative) plus elfie_data
(structured JSON with LOINC, ICD-10, confidence scores, evidence spans,
audit trail). Every encounter produces one row in the patient timeline.
| Module | Input | Output | Headline mechanism |
|---|---|---|---|
| 🎙️ Medical Scribe | Audio (EN / VI / FR / AR) | SOAP note + ICD-10 primary/secondary | 5-layer pipeline with constrained-LLM selector |
| 🧪 Labs Analyzer | Lab PDF | 26+ biomarkers mapped to LOINC + severity | Country-routed reference ranges, Python critical-value detection |
| 📸 Body Scan | 2 photos + H/W/age/sex | Measurements + body fat % + health ratios | 2-tier preflight + nationality-aware aggregation |
🎙️ Medical Scribe — multilingual audio consultation (Vietnamese,
English, French, Arabic via qwen3-asr-flash) → signable SOAP note with
validated ICD-10 primary + secondary codes. Our 5-layer pipeline
(entity extraction → rules → FAISS retrieval → constrained LLM
[Large Language Model] → BHYT validator) aims for null-over-hallucination
behaviour — on our current ground-truth tests it produced no ICD
hallucinations and handled negation (family history, suspected, denied)
correctly. BHYT ("Bảo Hiểm Y Tế" — Vietnam's national health insurance)
combination codes are auto-enforced — THA ("Tăng huyết áp" —
hypertension) + CKD resolves to I12.0, never I10 + N18 split, with
the BHYT regulation cited in-line (Phụ lục 2 Mục 4.2).
🧪 Labs Analyzer — lab PDF → 26+ biomarkers mapped to LOINC with ==country-specific reference ranges== (BYT VN / ADA / ESC / HAS / Saudi MoH / WHO fallback — routed automatically from patient nationality). Context-aware severity: the same glucose of 6.5 mmol/L is interpreted differently for a healthy vs. a T2DM patient. Critical-value detection for K^+^ > 6.0, glucose < 2.5, platelet < 50 etc. runs in hardcoded Python, never delegated to the LLM, because patient safety can't depend on a probabilistic classifier not missing a comma.
📸 Body Scan — 2 photos (front + side) + height / weight / age / sex → measurements (neck, waist, hip, shoulder, BMI) + body fat % + health ratios (waist-to-hip, waist-to-height with WHO / ACSM risk classification). We built a ==2-tier preflight==: Tier 1 rule-based (20+ checks — file integrity, pose detection, multi-person, front/side swap, duplicate detection, arms-apart tiering), plus Tier 2 Qwen-VL semantic review (identity match across photos, AI-generated detection, clothing fit, posing tricks, NSFW). Body-fat aggregation is nationality-aware — Asian users get Mean(Deurenberg + CUN-BAE), Western users get Lasso, based on Deurenberg 2002 and Ho-Pham 2014 literature. A BodyM-dataset-calibrated sanity gate catches outlier measurements and blends toward the BMI-expected range.
All three surfaces share one patient timeline, one schema, one disclaimer policy, one confidence convention. Scribe SOAP notes, Lab biomarkers, and Body Scan trends attach to the same patient profile. The history page shows everything chronologically. Share-with-doctor links carry the full ElfieData JSON:
{
"patient_view": { "summary": "…", "next_steps": ["…"] },
"elfie_data": {
"primary_diagnosis": {
"code": "I12.0",
"description_en": "Hypertensive chronic kidney disease with renal failure",
"confidence": 95,
"layer": "L1",
"rule_applied": "HTN_CKD_WITH_FAILURE",
"evidence": ["Bệnh thận do tăng huyết áp, có suy thận"],
"bhyt_note": "Phụ lục 2 Mục 4.2"
},
"disclaimer": "…"
}
}
How we built it
The architecture is a ==hybrid of rules and LLMs==, running the same four-stage pattern in every module: Extraction → Normalization → Medical Reasoning → Structured Output.
The ICD-10 pipeline is the clearest worked example — 5 layers:
- L0 Entity extraction (
qwen-maxJSON mode) with source-span validation: if the entity's fuzzy match against the transcript is below \(\geq 70\), it's dropped as a hallucination. - L1 Rule engine (pure Python, zero LLM calls) — 13 BHYT
combination rules. THA + suy thận + suy thận mạn → fires the
HTN_CKD_WITH_FAILURErule (ICD-10I12.0: Hypertensive chronic kidney disease with renal failure). Deterministic, sub-millisecond. - L2 FAISS retriever — 11,383 ICD-10 codes embedded with
text-embedding-v3(1024-dim). Cross-lingual: "tăng huyết áp" returnsI10; "heart attack" returnsI21.x. - L3 Constrained LLM selector (
qwen-turbo) — can only pick from the L2 candidate set. Any code outside the set is rejected and flagged[L3_HALLUCINATED], the output staysnull. - L4 BHYT validator — billable check, combination-rule compliance, primary / secondary ranking.
Labs and Body Scan follow the same discipline: Python handles the safety-critical paths (critical values, preflight rule gates), LLMs handle the reasoning paths (severity narrative, pose quality review), structured JSON is the canonical output, and a disclaimer is stamped on every response.
Tech stack — Python 3.12 FastAPI backend, Next.js 14 + TypeScript
frontend, SQLite with SQLAlchemy async, FAISS-CPU, MediaPipe Tasks, Anny
3D parametric body model (NAVER Labs), Three.js. DashScope is the
primary AI provider — Qwen (text + JSON), Qwen-VL (vision),
qwen3-asr-flash (ASR), text-embedding-v3 (embeddings). OpenAI Whisper
and Claude Haiku sit on the fallback chain.
Datasets — BYU Bodyfat Extended (434 subjects with hydrostatic ground truth) for the Lasso body-fat model; BodyM by Amazon Science (2,018 training subjects, CC BY-NC 4.0) to refit the regression envelope for the Body Scan sanity gate; BYT Vietnam ICD-10 base (11,383 codes); VN reference ranges for 26 biomarkers.
Challenges we ran into
1. Latency — from ~11.7s down to ~3.1s on the ICD pipeline. The
initial implementation ran qwen-max Layer 0 with a 5 KB system prompt
on every call. We added rule-first routing so Layer 0 is skipped when
Layer 1 can fire directly on the raw text, plus aggressive Layer 3
parallelisation. Across 10 consecutive runs we saw ~3.1s p50, with no
flakes on the ground-truth suite.
2. Multilingual audio that's actually code-mixed. Vietnamese doctors often mix VN medical terms with English drug names and international units — "bệnh nhân THA + CKD stage 3, đang dùng losartan 50 mg OD". ASR handles the audio well, but the SOAP extractor has to understand the code-mixing. We built the entity extraction prompt against VN–English mixed text specifically, with source-span validation requiring the entity to appear (fuzzy \(\geq 70\)) in the raw transcript.
3. Asian body-fat bias — we had to refuse our own Lasso for a subset of users. The Lasso model, trained on a mostly US / Caucasian cohort, predicted a Vietnamese BMI 25.4 male at 14% body fat ("Athletes") — but Asian body composition at that BMI is ~21% ("Average") per Deurenberg 2002 and Ho-Pham 2014. We couldn't retrain the model, so we route the aggregator by patient nationality: Asian → Mean(Deurenberg + CUN-BAE), Western → Lasso (unbiased on its training cohort), unknown → balanced mean of three. Literature-justified, and honest about the tradeoff.
4. Null over hallucination as a discipline, not a flag. Every layer
has an explicit escape hatch. Layer 3 can't return codes outside the L2
candidate set. Layer 4 drops codes that fail the billable check. Layer 0
drops entities whose source span fails fuzzy match against the original
transcript. The sanity gate blends out-of-range body measurements toward
the regression mean and logs a SANITY_FLAG. The system sometimes says
"we don't know" — and that's a feature.
Accomplishments that we're proud of
Honest milestones from the hackathon cycle — we treat these as early indicators, not finished claims. Our ground-truth sets are small on purpose, and we've tried to document confidence boundaries in the technical write-ups rather than sell single numbers.
The ICD-10 pipeline behaves well on the tests we have. On 3 ground-truth cases, run 30 times consecutively, we did not observe any ICD code fabricated outside the retrieval candidate set, and negation handling (family history, suspected, denied) was correct. Cross-lingual typeahead settled around ~55 ms p50. Latency came down from ~11.7 s to ~3.1 s end-to-end. Three cases is a small suite — we read these as directional, not definitive.
Labs Analyzer pulled all the biomarkers we tested on 2 real lab PDFs (66 / 66 mapped to LOINC with a severity that looked correct on review). Country-routed reference ranges cover VN, US, EU, FR, AR, with a WHO fallback. Critical-value detection stays in Python, not the LLM.
Body Scan measurements landed within a few percent of tape ground-truth on our anchor subject — Shoulder +0.5%, Neck −3.8%, Waist −3.5%, Hip −4.6%. Body fat of 21.9% sits inside the Ho-Pham 2014 Vietnamese BMI-25 male cohort band (22–26%). We keep the anchor set small on purpose and document confidence per scenario in the technical doc.
==One unified schema across three modules.== The ElfieData dual-output (
patient_view+elfie_data) is applied consistently — same confidence enum, same disclaimer field, same evidence-span convention, same audit trail. This is the piece we're most pleased with architecturally.A regression suite we actually trust. 150 test assertions across 4 suites, all green. One of them caught a systematic body-fat prediction offset that turned out to be ensemble-aggregation bias rather than model bias — so the fix was swapping aggregators rather than retraining a model.
F5-resilient flows for Labs and Scribe — users can refresh, close tabs, or switch apps mid-extraction and pick up where they left off. Body Scan still needs this treatment.
What we learned
- "One patient profile → structured data → downstream usable" is the thesis that turns three demo modules into a platform. If your three outputs don't share a schema, you haven't built a platform.
- Dataset mismatch matters as much as model quality. A 2,018-subject public dataset taught us that calibration factors often compensate for pipeline noise, not body geometry — and pipeline noise doesn't transfer across datasets. Shipping only the refit that transferred was more valuable than claiming three wins.
- Population matters more than model. Asian BMI ≠ Caucasian BMI at the same body fat, regardless of what a model's MAE says on its training set. Literature-based population routing beats fine-tuning when you can't retrain.
- Silent fallbacks are worse than loud errors. A library import path issue once hid behind a graceful statistical fallback for months. Loud errors get fixed within a day; silent degradations get shipped.
- Null over hallucination is a culture, not a flag. Every layer has to be designed to fail safely at the join. The hard part isn't detecting uncertainty — it's wiring the escape hatch everywhere.
What's next for Health Companion
Immediate
- [ ] Doctor sign-off on the 10 pending BHYT combination-rule annotations
- [ ] Collect a small Vietnamese subject panel (10–20 subjects with tape + photo) to refine Body Scan
CALIBRATIONbeyond the current n=2 (1 male + 1 female) anchor - [ ] Strip EXIF GPS from stored photos before DB persistence
Medium-term
- [ ] Async job queue for Body Scan, matching the F5-resilient pattern already used by Labs and Scribe
- [ ] Expand ICD ground-truth from 3 cases to 50+ real SOAP notes for statistical confidence
- [ ] DEXA validation on 50+ Body Scan subjects toward a clinical-grade claim
Long-term
- [ ] Per-region calibration beyond the current Asian / Western binary (Middle East, Africa, LATAM as subject data accumulates)
References
Anthropometry & body composition
- Deurenberg P., Deurenberg-Yap M., Guricci S. (2002). Asians are different from Caucasians and from each other in their body mass index / body fat per cent relationship. Obesity Reviews. doi:10.1046/j.1467-789X.2002.00065.x · PubMed
- Deurenberg P., Weststrate J. A., Seidell J. C. (1991). Body mass index as a measure of body fatness: age- and sex-specific prediction formulas. Br J Nutr 65(2):105–114. doi:10.1079/BJN19910073 · PubMed 2043597
- Gómez-Ambrosi J. et al. (2012). Clinical usefulness of a new equation for estimating body fat (CUN-BAE). Obesity (Silver Spring). doi:10.1038/oby.2011.36 · PubMed
- Hodgdon J. A., Beckett M. B. (1984). Prediction of percent body fat for U.S. Navy men from body circumferences and height. Naval Health Research Center Report 84-11.
- Ho-Pham L. T. et al. (2014). Reference-range work on Vietnamese body composition via DXA — used as the external band check for the BMI-25 Vietnamese male cohort.
Datasets
- Ruiz N., Bellver M., Bolkart T., Arora A., Lin M. C., Romero J., Bala R. (2022). Human Body Measurement Estimation with Adversarial Augmentation. Amazon Science. Paper · Dataset (CC BY-NC 4.0)
- Penrose K. W., Nelson A. G., Fisher A. G. (1985). Generalized body composition prediction equation for men using simple measurement techniques. Med Sci Sports Exerc 17(2):189. (BYU Bodyfat dataset origin.) The extended 434-subject CSV is shipped with the repo under
docs/research/challenge-2/dataset/.
Clinical standards
- WHO ICD-10, 2019 edition — icd.who.int
- Bộ Y tế Việt Nam. Thông tư / Quyết định về mã ICD-10 BHYT —
docs/research/snapshot of BYT 11,383-code base. - LOINC — loinc.org
- ADA Standards of Care in Diabetes 2024 — diabetesjournals.org/care
- ESC/ESH Hypertension Guidelines 2024 — escardio.org/Guidelines
- KDIGO 2022 Clinical Practice Guideline for Diabetes in CKD — kdigo.org
Models, frameworks & code
- Qwen (Alibaba) — github.com/QwenLM
- Whisper (OpenAI) — github.com/openai/whisper
- MediaPipe Tasks (Google) — ai.google.dev/edge/mediapipe
- Anny — parametric body model by NAVER Labs — github.com/naver/anny
- FAISS (Meta Research) — github.com/facebookresearch/faiss ```
Built With
- ai
- claude
- qwen

Log in or sign up for Devpost to join the conversation.