-
-
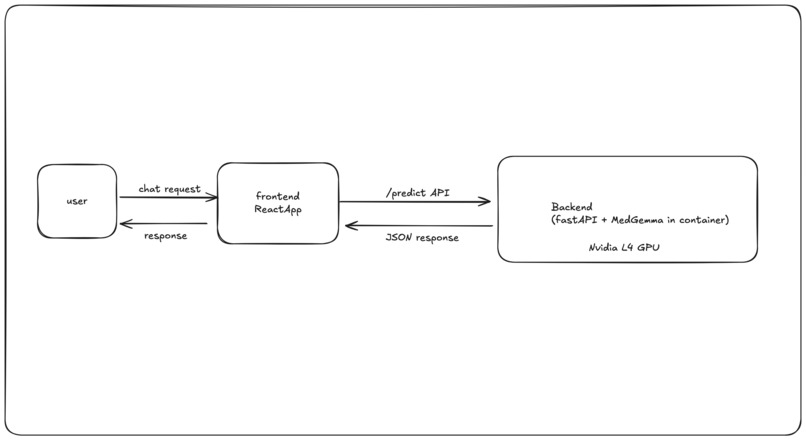
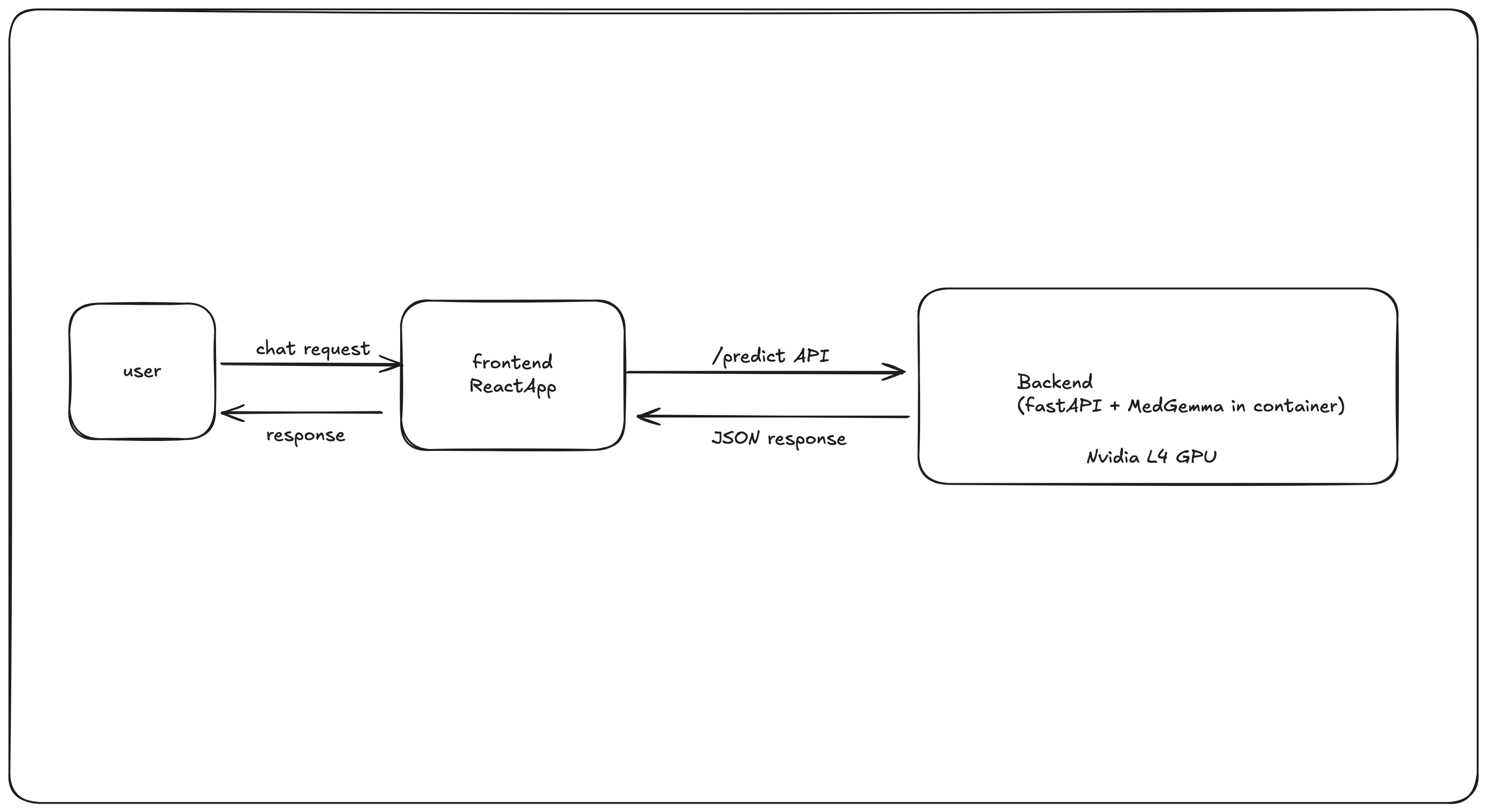
Flow_diagram
-
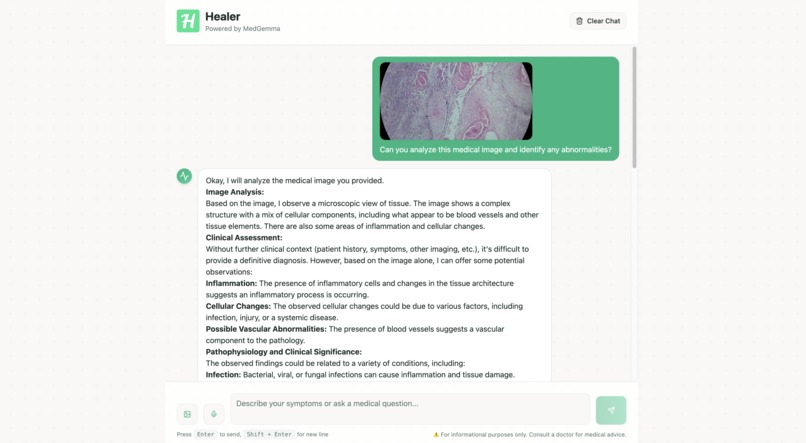
Working_project
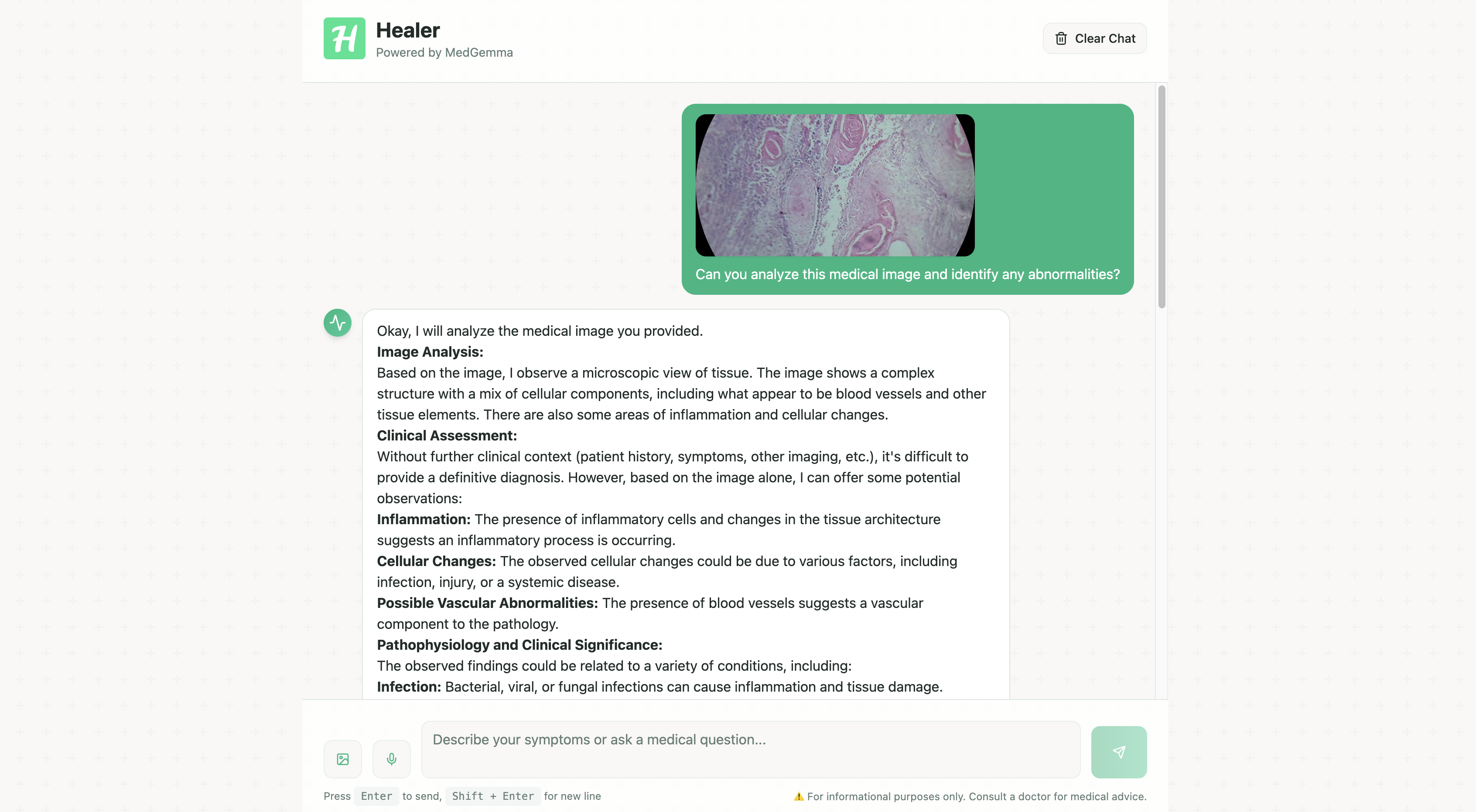
Inspiration
Colorectal cancer outcomes improve dramatically with early detection, but expert review of histopathology imagery is time‑consuming and scarce. We built Healer to make preliminary, accessible medical guidance available anywhere: a simple chat interface that can reason over text and medical images to support clinicians and patients with fast, explainable answers.
What it does
- Chat-based medical assistant that handles both text questions and image‑based queries (e.g., histopathology slides).
- Optional speech‑to‑text input for hands‑free use in clinical settings.
- Returns concise, clinically framed responses with reasoning and next‑step recommendations.
- Persists chat history locally for quick context recall (no data leaves the browser beyond a single inference request).
How we built it
- Frontend: React + TypeScript + Vite, shadcn/ui components, Web Speech API, and localStorage for chat history.
- Backend: FastAPI + Uvicorn hosting a MedGemma 4B (instruction‑tuned) pipeline using Hugging Face Transformers and PyTorch.
- Model handling: We download MedGemma during the Docker build (
download.py) and ship weights inside the image for zero external dependencies at runtime. - Inference:
AutoProcessor+AutoModelForImageTextToText; device‑aware execution (CUDA if available, otherwise CPU) with bfloat16/float32 automatically chosen. - Cloud: Built with Google Cloud Build and deployed to Cloud Run as a single container (API + model in the same service).
Challenges we ran into
- Memory and latency: Large VLMs are heavy. We optimized dtype and device usage and tuned token generation to keep response times reasonable. For production, we keep one warm instance to mitigate cold starts.
- Build time with big weights: Model download initially made builds painfully slow. Moving it to a dedicated Docker layer with caching fixed iteration speed.
- Secret handling: Passing Hugging Face tokens securely through Cloud Build while keeping them out of image layers required careful environment/arg plumbing.
- Prompt reliability: Getting definitive, clinically useful answers consistently required several prompt iterations and clear structure for text‑only vs. image+text.
Accomplishments that we're proud of
- A fully containerized, production‑deployable medical VLM service with a clean UI.
- Multimodal pipeline (text + image) running behind a simple REST endpoint.
- Hands‑free speech capture and a smooth chat experience with local persistence.
- Straightforward cloud deployment (Cloud Build → Cloud Run) that anyone can reproduce.
What we learned
- Practical MLOps for multimodal models: layer caching, image size vs. boot time trade‑offs, and device/dtype tuning.
- Prompt engineering matters—clinically framed instructions dramatically improve answer quality and consistency.
- Cloud Run is viable for VLMs when you bake weights into the image and manage cold starts thoughtfully; GPUs can be added when needed.
What's next for Healer
- Streaming responses and partial rendering for faster perceived latency.
- Formal evaluation on public medical benchmarks; add guardrails and error detection.
- Optional GPU deployment path and autoscaling policies; explore Vertex AI Model Garden variants.
- Privacy & compliance hardening (audit logging, PHI handling guidance, and enterprise controls).
- Richer multimodal inputs (DICOM, dermatoscopic images) and structured outputs (clinical note templates, billing codes suggestions).
- User features: session sharing, export to PDF, and curated “second‑opinion” mode that lists differentials and test plans.
Built With
- google-cloud
- healthcare
- huggingface
- medgemma
- python
- react

Log in or sign up for Devpost to join the conversation.