-
-
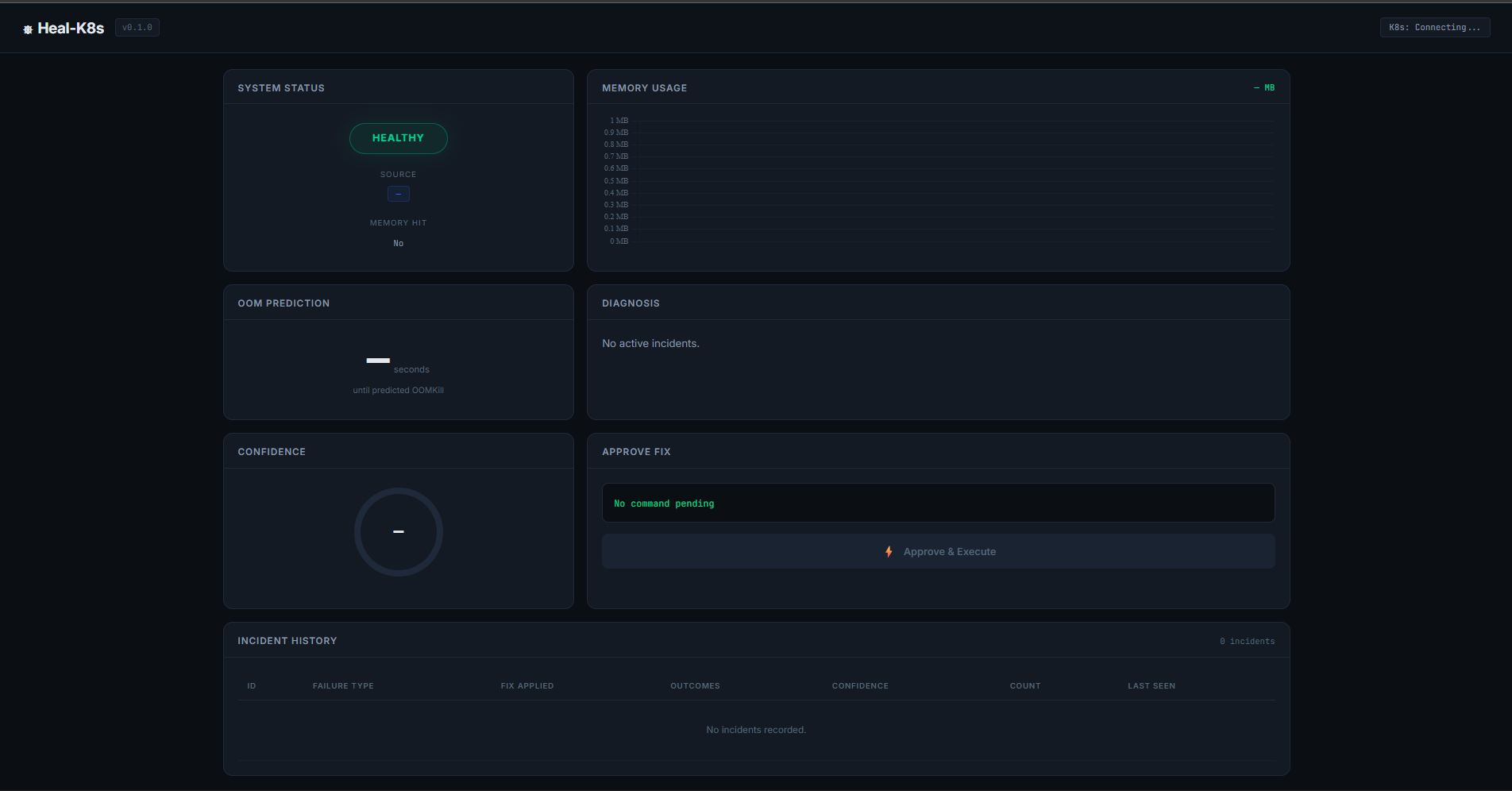
Dashboard
Heal-K8s — Submission Story
Inspiration
At 3 AM, most Kubernetes incidents are not new failures but familiar failures that are recurring under pressure: OOMKilled pods, crash loops, image pull failures, and critical manual interventions.
This is why we posed a question to address the problem:
Why are we paged on incidents that a system should be able to predict, classify, and safely recover from?
Heal-K8s was designed to ease the pain by providing a simple cycle of prediction, deterministic debugging, approval-driven fixing, and memory.
What it does
Heal-K8s is a Human-in-the-loop Kubernetes Incident Response System that:
- Predicts OOM failures before they happen
- Detects known failure signatures immediately without using LLMs
- Utilizes an LLM Fallback only when encountering unknown failures
- Provides a suggested remediation command in the dashboard
- Executes only after receiving Human Approval
- Learns from outcomes using Incident Memory
Core loop:
Predict → Diagnose → Approve → Execute → Learn
How we built it
We built Heal-K8s as a modular stack:
- Backend (FastAPI): API orchestration, state management, and incident routing
- Predictive Engine: time series memory growth analysis for time to OOM calculation
- Signature Engine: regex/rule-based matching for common Kubernetes error types
- LLM Fallback: structured JSON diagnosis path for unknown error types
- Memory Layer (SQLite): storing results and confidence levels for repeated incidents
- Execution Layer: Kubernetes Python client integration and safe execution controls
- Frontend (Vanilla JS + Chart.js): real-time dashboard display with countdown, confidence levels, and approval flow
- Telemetry Input: Prometheus polling and deterministic fake triggers for reproducible demos
A core memory confidence idea:
confidence = success_count / (success_count + failure_count)
Challenges we ran into
- Live infra vs demo reliability: real Kubernetes + Prometheus can be powerful but brittle in a time-constrained demo scenario
- False positives in prediction: what if we have no safeguards for sustained growth in the detection of a leak
- Frontend consistency: the countdown timing, stale messages, transitions of execution state all need to be carefully fine-tuned
- Mode switching: balancing deterministic test flows with live telemetry proof without muddling the narrative
- Safety controls: maintaining explicit approval gating and command constraints while keeping it fast
Accomplishments that we're proud of
- Built a complete incident loop, not just an assistant wrapper
- Showed a prediction before failure with a visible countdown
- Used LLM as a fallback, not primary decision logic
- Included a form of incident memory to resolve repeated failures more quickly
- Provided a polished judge-ready flow with deterministic demo paths
- Maintained a clear human-in-the-loop safety model throughout execution
What we learned
- In operational tooling, reliability and clarity are more important than the number of features
- Deterministic systems (prediction + signatures + memory) create trust faster than AI-only behavior
- Approval-gated automation is vital for safe remediation, especially in a production-like environment
- Observability UX is about reducing cognitive load under pressure, not adding more panels
- Demo-ready and production-ready are distinct, and both require intentional design
What's next for Heal-K8s
- Expanded signature coverage (CPU Throttling, Disk Pressure, Network Path Failures)
- Multi-Cluster support, stronger RBAC-Aware Execution Policies
- Integration of Alert & Approvals Workflows with Slack & PagerDuty
- Improved Memory Intelligence with more context & confidence calibration
- Additional deployment paths beyond local Minikube for more pilots of staging & production clusters
Closing note
Heal-K8s demonstrates that incident response can be proactive, explainable, and safer — without removing humans from the loop.
Built With
- chart.js
- docker-desktop
- fastapi
- google-gemini-api
- helm
- html/css
- javascript
- kubernetes-(minikube)
- kubernetes-python-client
- prometheus
- pytest
- python
- sqlite
- uvicorn




Log in or sign up for Devpost to join the conversation.