-
-
Linux-mint
-
Phone
-
Windows
-
arch linux support + dev tools
HBP100-USAII
Inspiration
People often turn to AI to understand discharge summaries, insurance approvals, and other complex documents. However, sharing these documents with external AI systems can expose sensitive information such as names, phone numbers, emails, medical record numbers, and dates.
We wanted to build a system that allows people to benefit from AI explanations without unnecessarily exposing private information.
Our goal was simple:
Move from confusion → understanding → action while keeping sensitive information protected.
What it does
HBP100-USAII is an AI-powered document understanding system built on top of HBP100 v2.
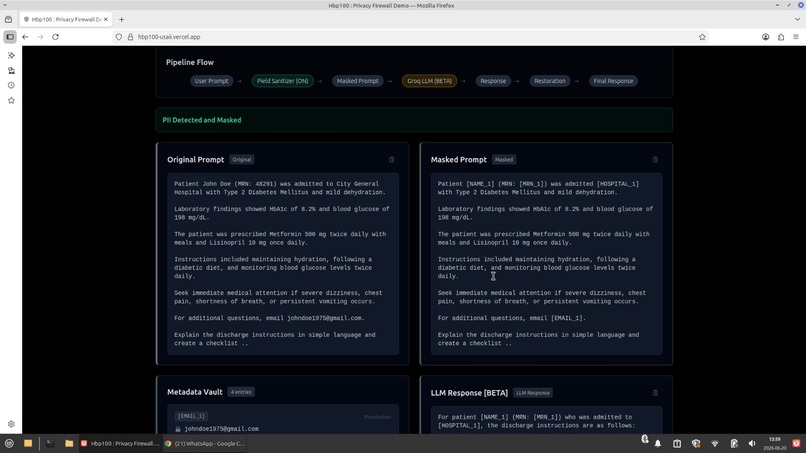
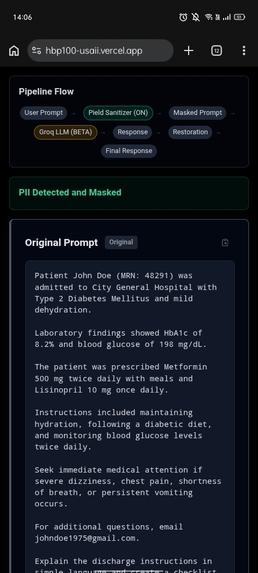
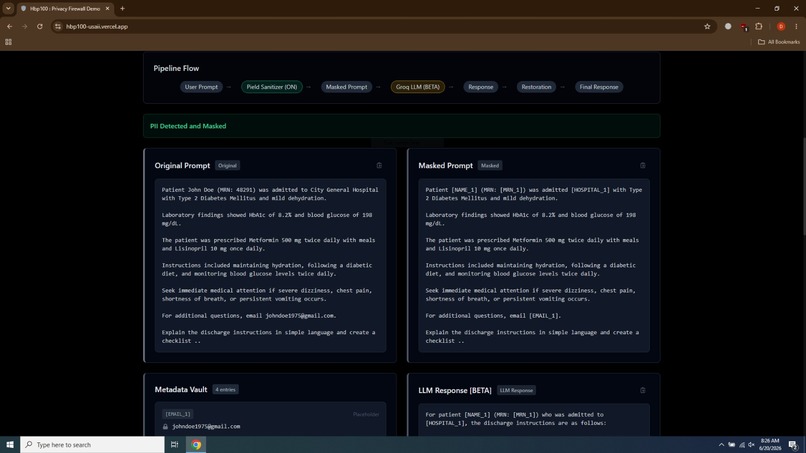
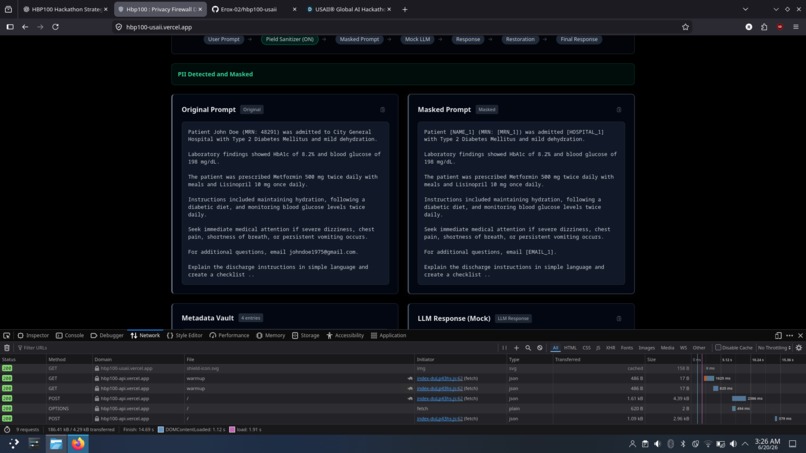
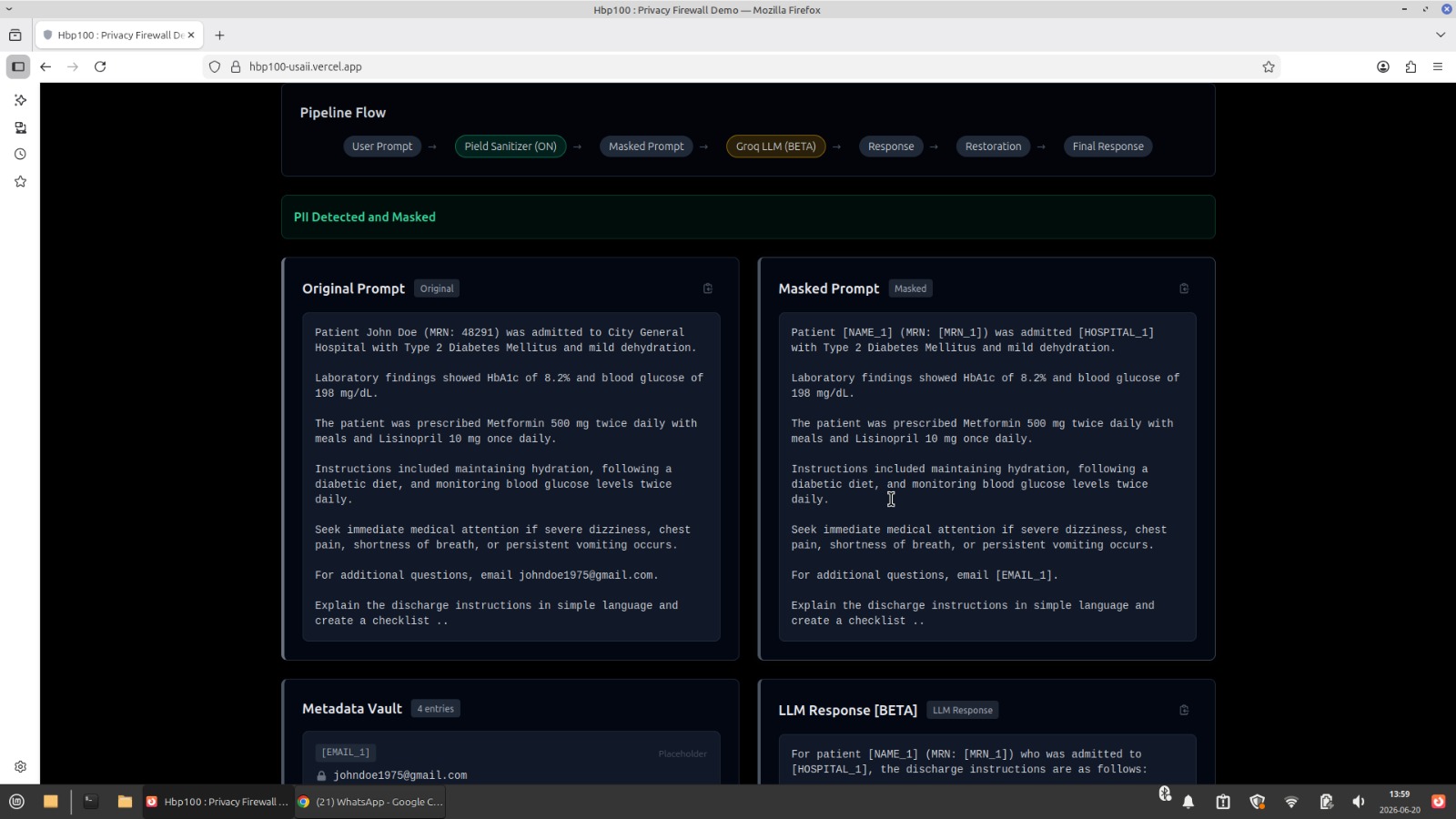
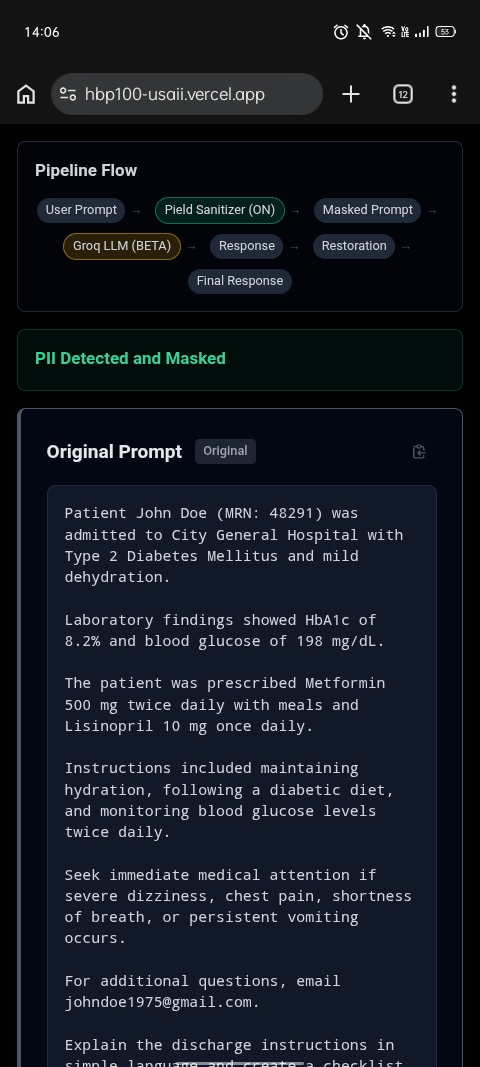
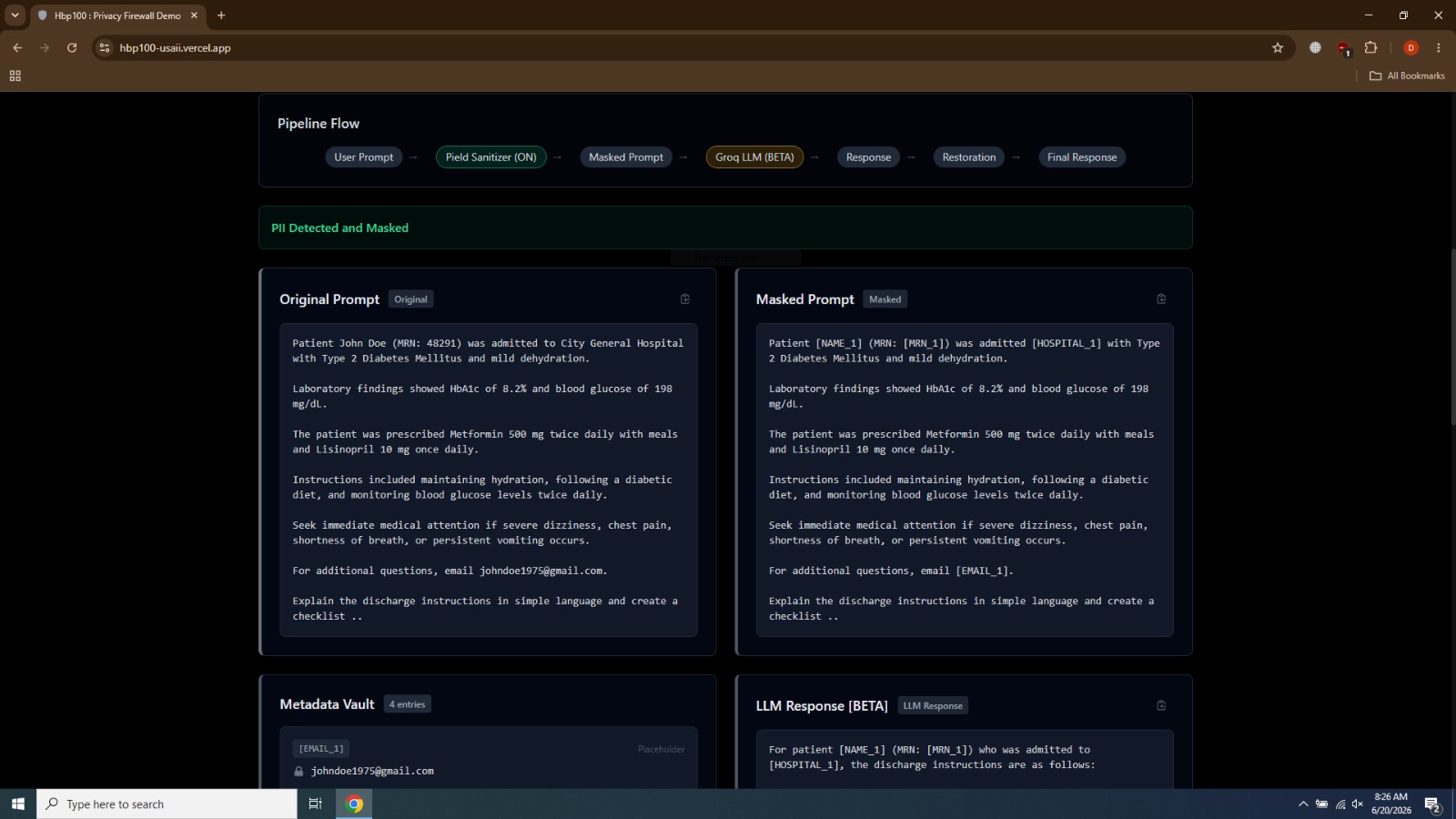
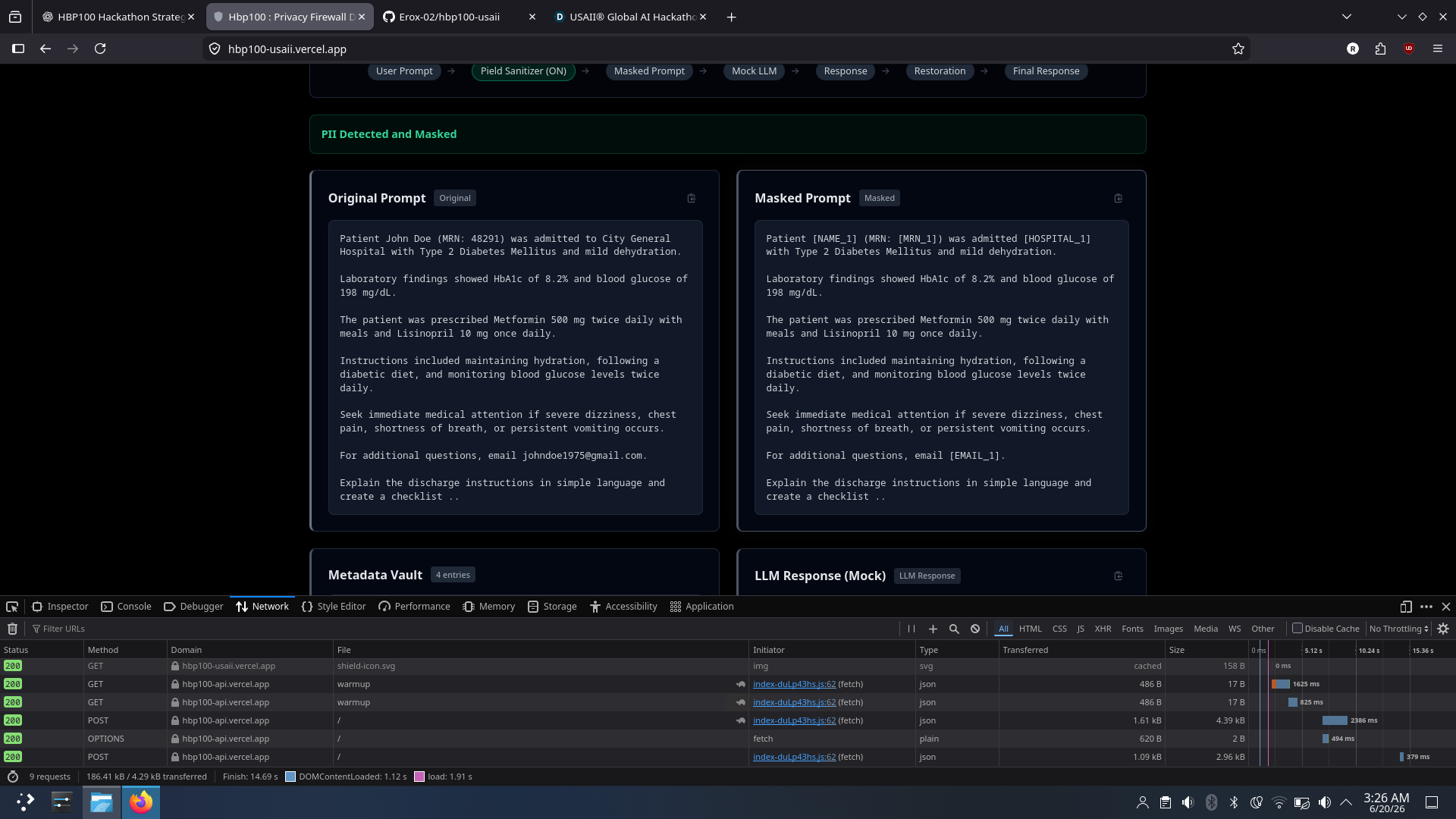
Before reaching an external language model, sensitive information is detected and replaced with placeholders. The language model explains the document using masked text, and the original information is restored afterward.
The system helps patients, caregivers, and individuals reviewing healthcare or insurance documents understand instructions, warning symptoms, and next steps without exposing sensitive information in plain form.
How we built it
The frontend was built using React, Vite, and Tailwind CSS to provide a lightweight and responsive user experience across desktop and mobile devices.
The backend was implemented with FastAPI and deployed using Vercel serverless functions. Language model inference is performed using Groq's Llama-3.3-70B model.
Privacy protection is provided by HBP100 v2, a lightweight contextual privacy firewall developed as a separate open-source package.
The privacy pipeline consists of:
- Modular regex-based entity extractors
- TF-IDF vectorizer
- LightGBM classifier
- Placeholder generation
- Metadata vault
- Placeholder validation
- Placeholder restoration
Sensitive information is first detected and converted into placeholders. The masked prompt is then sent to the language model. After inference, placeholder validation prevents hallucinated entities and the original values are restored.
The complete workflow is:
Document → Entity Extraction → Placeholder Generation → Metadata Vault → Masked Prompt → LLM → Placeholder Validation → Restoration → Final Response
Training Data
The HBP100 v2 policy engine was trained using a custom dataset consisting of synthetic and manually curated examples spanning medical, insurance, and general document scenarios.
The dataset contains labeled examples used to train the TF-IDF + LightGBM decision pipeline. Additional manual test cases were created to evaluate masking, restoration, and overlap handling.
No real patient records, PHI, or external medical databases were used.
The dataset and package are available through the HBP100 v2 repository.
Challenges we ran into
Building HBP100-USAII involved far more engineering challenges than expected.
One of the biggest difficulties was balancing privacy with usability. Early versions suffered from regex overlap issues where entities such as addresses, phone numbers, and hospital names accidentally consumed neighboring text. Several iterations of the extraction pipeline were required before achieving reliable masking behavior.
We also encountered state management problems. Metadata from previous requests occasionally leaked into subsequent requests, causing restoration failures and synchronization bugs. Solving this required redesigning the metadata vault and improving request isolation.
Another challenge involved architecture and packaging. During development we encountered circular imports, version conflicts between local source files and installed packages, and situations where Python imported outdated modules. Debugging these issues often required restructuring the package itself.
As the system evolved, placeholder restoration became another source of complexity. Some entities masked correctly but failed to restore because of ordering problems or metadata mismatches. Multiple redesigns were required to eliminate nested replacements and duplicate entities.
Deployment introduced a completely different class of problems. Integrating FastAPI with Vercel serverless functions involved routing issues, CORS errors, dependency problems, environment variable configuration, and debugging deployments that succeeded but returned runtime failures.
Stress-testing with realistic healthcare and insurance documents revealed many additional edge cases including broken phone number patterns, entity overlap, incorrect placeholder ordering, and restoration failures. Addressing these problems required repeated redesigns of the extraction pipeline and overlap filtering mechanisms.
We also faced challenges in controlling the behavior of external language models. Some models attempted to invent placeholders or modify existing ones. To mitigate this, we designed a strict system prompt and implemented placeholder validation to detect hallucinated placeholders before restoration.
Although many of these issues required long debugging sessions, they ultimately led to a more reliable and modular privacy firewall. The process taught us that building trustworthy AI systems involves much more than model inference—it requires careful attention to architecture, state management, validation, deployment, and responsible system design.
Design Philosophy
Sensitive information should never reach external AI systems unnecessarily.
HBP100-USAII follows a second principle as well:
Do not use heavyweight AI when lightweight methods are sufficient.
Many problems do not require large neural models. Tasks such as entity extraction, masking, placeholder generation, and validation can often be solved faster and more transparently using lightweight machine learning and deterministic components.
Instead of placing a large neural model everywhere in the pipeline, HBP100 uses a modular approach:
- Lightweight extractors for entity detection.
- TF-IDF + LightGBM for decision making.
- Deterministic placeholder generation and restoration.
- Large language models only where natural language understanding provides meaningful value.
This approach prioritizes:
- Low latency
- Explainability
- Modularity
- Efficiency
- Responsible AI usage
The goal is not simply to maximize model accuracy, but to balance accuracy, latency, model size, and explainability .
"Why use a 120b neural model where a small classifier can solve the task in milliseconds"
Accomplishments we're proud of
- Building HBP100 v2 as a reusable open-source package.
- Achieving approximately 380 ms privacy pipeline latency.
- Maintaining approximately 2.3 second end-to-end latency.
- Creating a privacy-preserving AI workflow rather than a traditional chatbot.
- Deploying a working cross-platform web application.
- Designing the system with human-in-the-loop and responsible AI principles.
What we learned
We learned that privacy and usability do not need to be competing goals.
We also learned that lightweight architectures can provide practical solutions while remaining explainable and modular.
Finally, we learned the importance of responsible AI design and clearly defining what decisions should remain under human control.
What's next
Future versions aim to add:
- Better extractor coverage
- Improved overlap handling
- PDF support
- OCR integration
- Image understanding
- Multi-language support
- Context-aware extraction
HBP100-USAII intentionally prioritizes speed, modularity, explainability, and human oversight while continuing to expand its capabilities.
Built With
- css
- elevenlabs
- fastapi
- groq
- hbp100-v2
- javascript
- lightgbm
- llama-3.3-70b
- openai-api
- python
- react
- scikit-learn
- tailwind
- tf-idf
- vercel
- vite


Log in or sign up for Devpost to join the conversation.