-
-

Project Logo
-
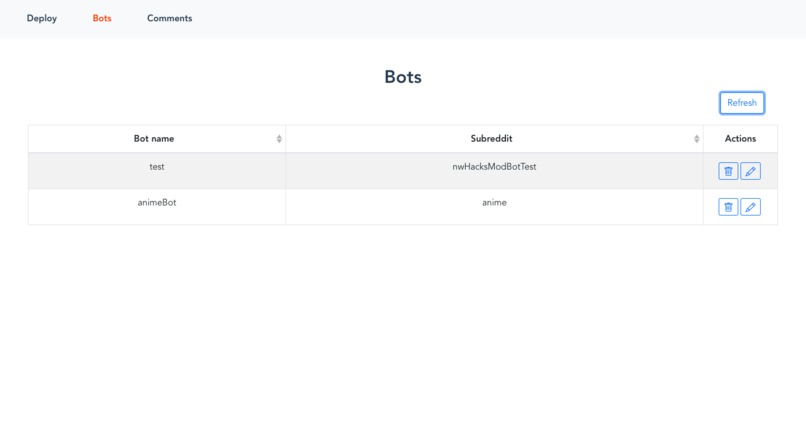
Bot List
-
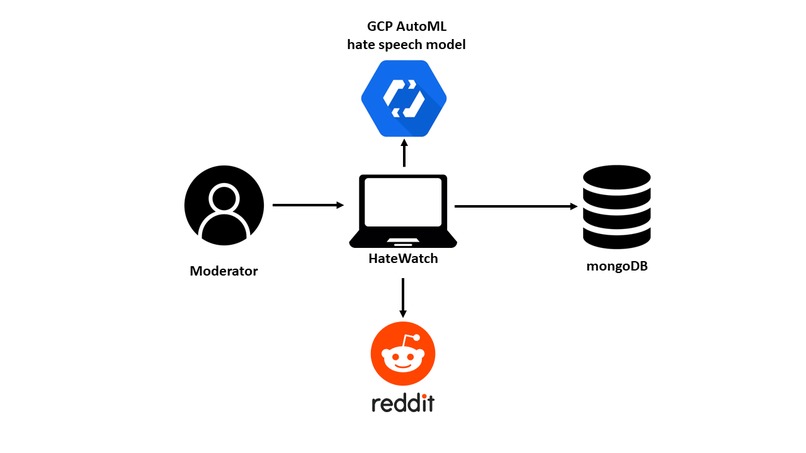
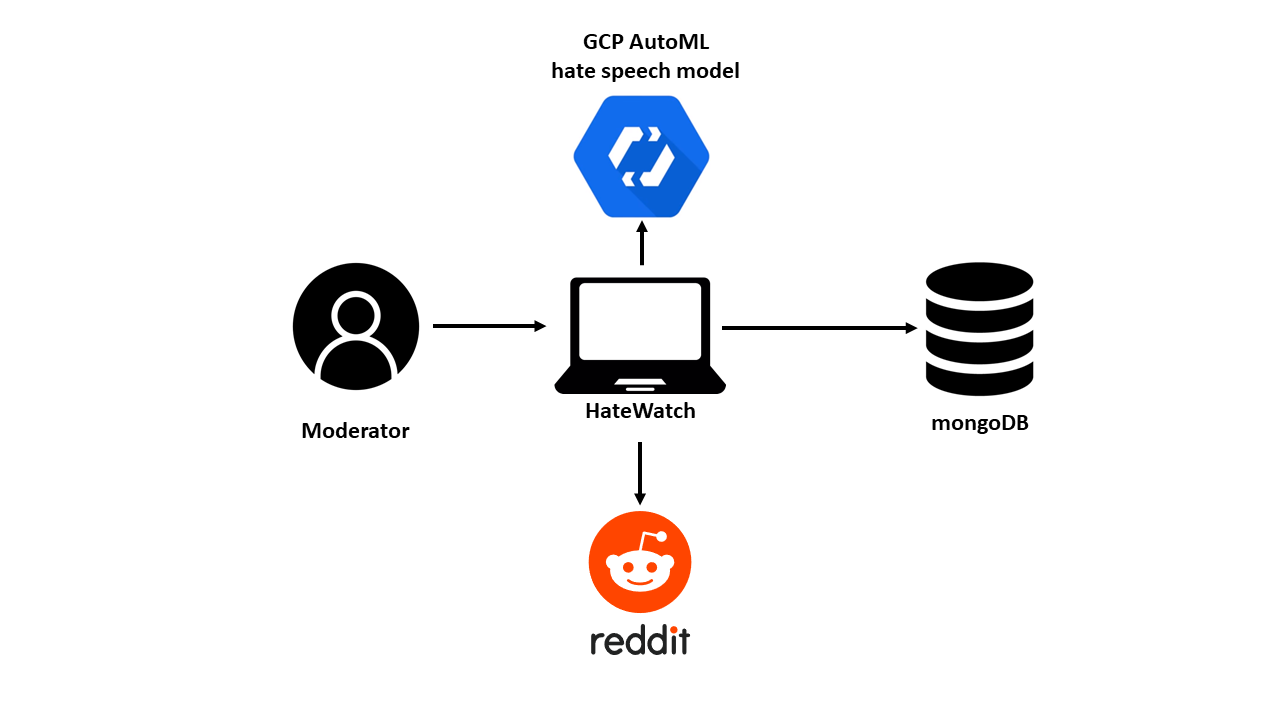
Architecture
-
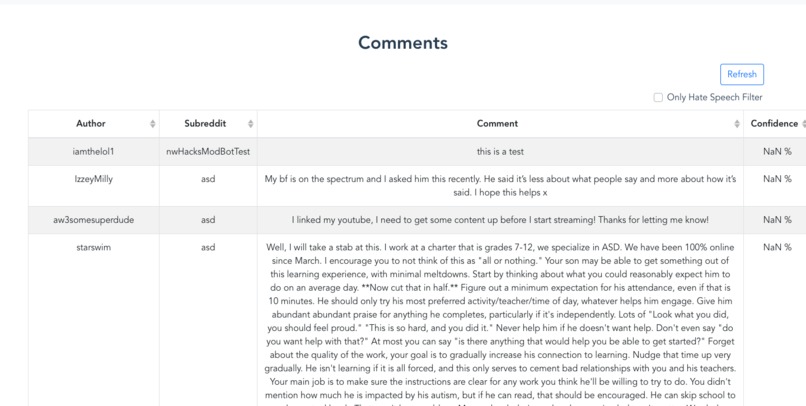
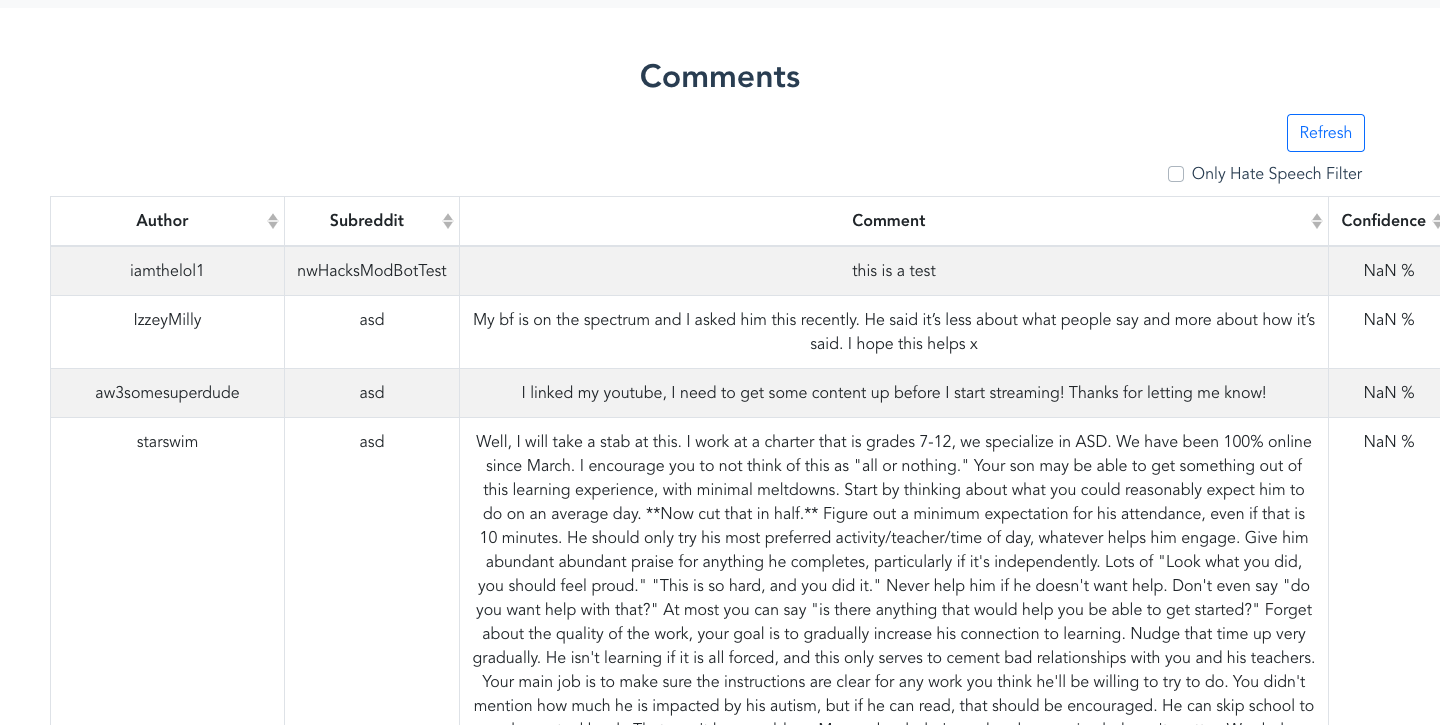
Comment Section

Inspiration
Due to the pandemic and current political events, activity on social media has skyrocketed. As expected, conflicts on platforms that allow user discussion and content-creation have led to greater volumes of hate speech that moderators need to identify and control. To keep moderators from being overwhelmed and to give them adequate tools, we have decided to create a web-app for them to deploy bots powered by machine learning to detect hateful comments without having to know any bot scripting skills. Though we chose Reddit as our platform, this idea could easily be extended to other social media and user-generated text content through other APIs or web crawlers.
What it does
From a simple web UI, moderators are able to create 'bots' and assign them to their subreddits to begin monitoring for hate speech. Comments and submissions feed into a binary classification model (hate speech, not hate speech)
Once the bots are deployed, moderators are able to monitor these bots by seeing the comments they have flagged and view the trends of hate speech across different subreddits. Moderators can also edit and delete their bots at will. Through the Reddit API, moderators could potentially configure their bots to directly modify Reddit data by removing, hiding, or replying to posts.
How we built it
The core structure of our app was built primarily with Node.js and the Vue.js framework. The backend communicated with GCP's AutoML and NLP APIs, which we trained with the hate speech data that we gathered and pruned with a Python script. The dataset consisted of over 20,000 lines of Reddit conversations containing hate speech comments from at link resulting in 91% accuracy. This particular dataset takes into account the context in which hate speech occurs, which is more accurate to online discourse. Our database was hosted on MongoDB Atlas, which we filled with data generated from gathered comments for creating in-depth data analyses to display on the UI.
Challenges we ran into
We had some trouble at the beginning conceptualizing what it meant to deploy bots. Ideally, the Node.js server would spawn separate processes for the bots so it would be free to respond to endpoint events. However, for the sake of time we decided to have just one process.
We had some trouble with our architecture since it consisted of many parts. Getting credentials and setup for each service we used was quite time-consuming overall. In particular, some of our team could not connect to MongoDB.
Finally, it was challenging to figure out how to apply NLP to detect hate speech. The GCP language API was not suited for our needs, so we decided to train a model ourselves. Finding good data for our desired model (a binary classification) was difficult and we had to clean it using a Python script.
Accomplishments that we're proud of
We are proud of getting a working demo which can actually pull and analyze data from Reddit while assigning model confidence numbers to each message posted. This shows that our core concept was brought to life.
Also, this was our first time using a machine learning model that we trained ourselves and we feel we now have a much stronger idea of how to seek relevant datasets and tailor machine learning tools to our specific projects rather than using preset APIs of preset models.
What we learned
We learned about many separate topics in development throughout this project: how to train an NLP model, what the different kinds of models are, how to create a project with a complicated architecture, etc. Some of our team members learned about .gitignore and better git practices as well as .env and other practices which facilitate the development process. We read research papers about hate speech detection and learned about how to combat the problem, as well as how serious it has become.
What's next for HateWatch
The Hatewatch project is now just a proof of concept. If it were a real service, it would need user accounts and authentication as well as a more sophisticated backend with separate bot processes. We would include more data analytics and visualization for moderators. The hate speech detection strategy would need to be composed of different options, including an option to simply filter out certain words if the moderator requires. The NLP model would need to be better-trained for a higher accuracy to reduce both false-positives and false-negatives. We also plan to deploy our monitoring bots to a multitude of different platforms in order to cover against a wider range of hate speech all over the internet. We also plan to integrate a feature to prevent misinformation and warn those targeted by our bots that the information they're spreading may not be entirely accurate.



Log in or sign up for Devpost to join the conversation.