-
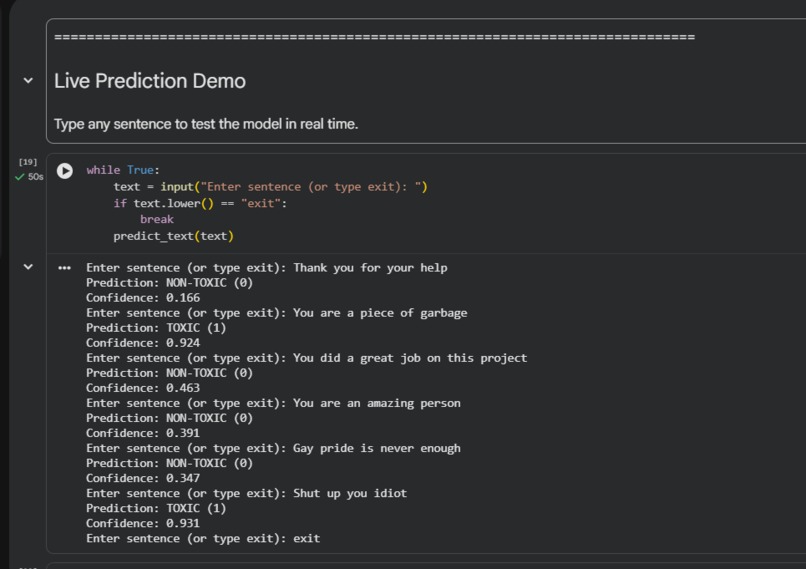
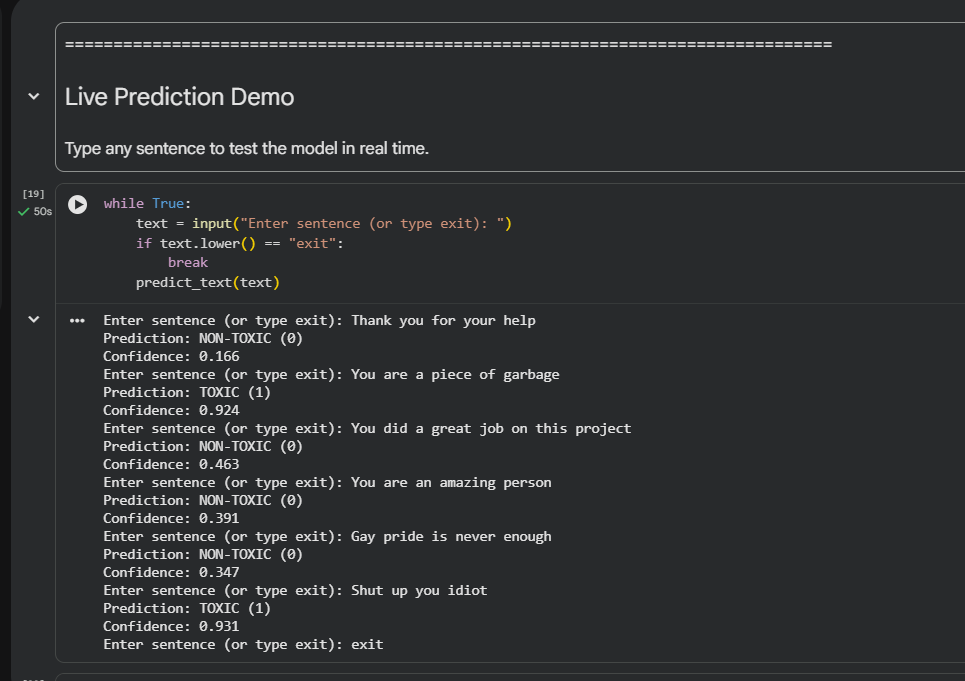
Predictions for english comments
-
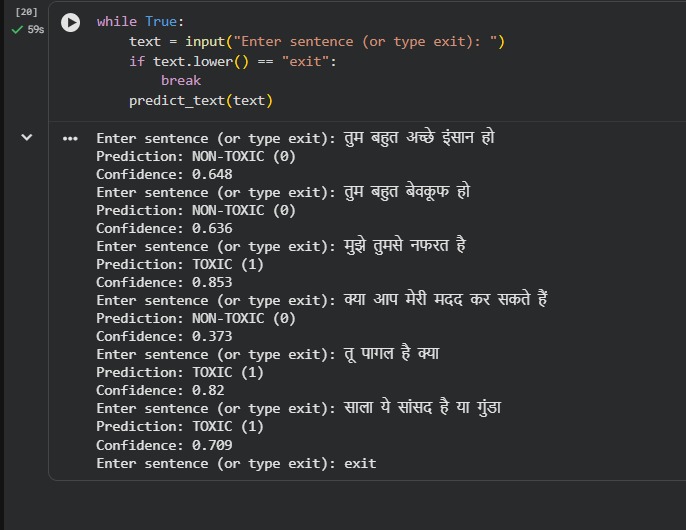
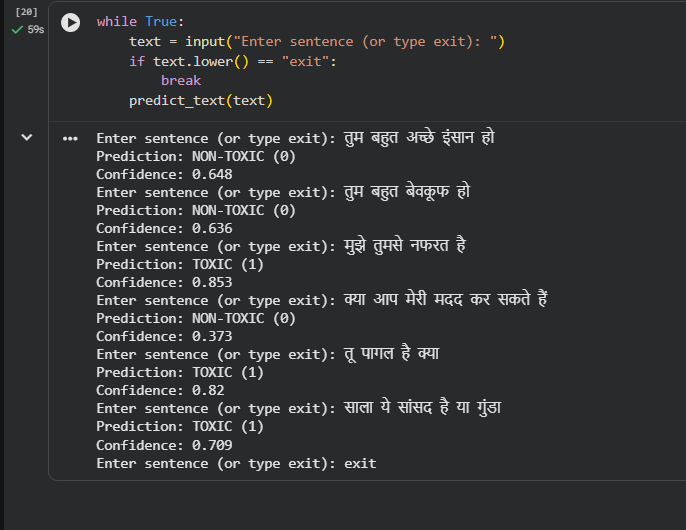
Predictions for Hindi comments
-
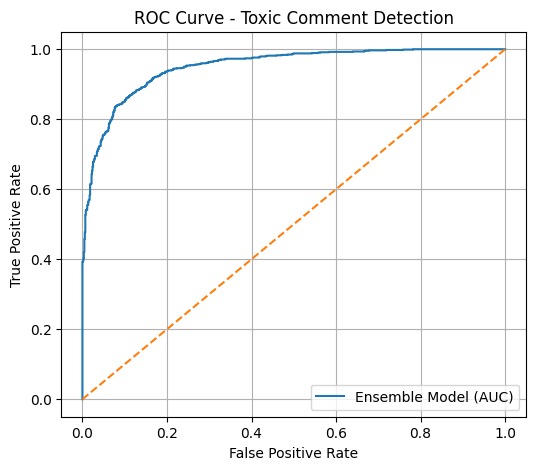
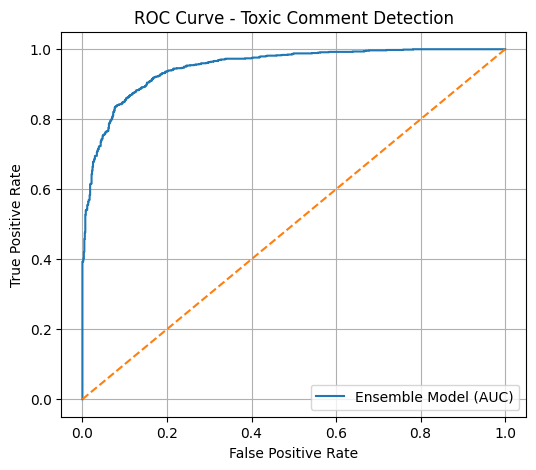
ROC Curve - Toxic Comment Detection
-
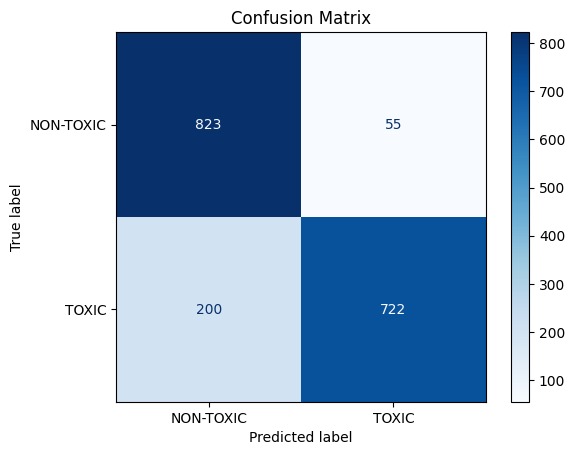
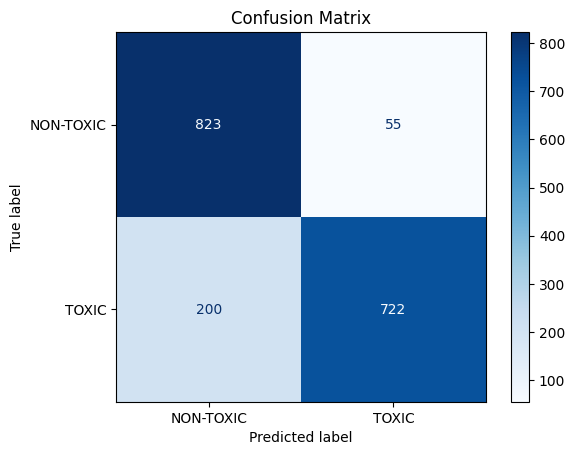
Confusion Matrix
Inspiration
I wanted to address the growing problem of toxic and abusive content on social media, especially in multilingual spaces like English and Hindi. Manual moderation doesn’t scale, and harmful content often goes unchecked. This motivated me to build an automated system that can detect toxicity efficiently and reliably.
What it does
HateSense AI is a multilingual toxicity detection system that classifies social media comments as toxic (1) or non-toxic (0). It supports both English and Hindi text, including mixed-language inputs commonly found online. The system also provides confidence scores for predictions.
How I built it
I built the system using a classical NLP pipeline:
- Cleaned and preprocessed multilingual text (English + Hindi)
- Extracted features using TF-IDF with unigram and bigram representations
Trained two models:
- Logistic Regression
- Linear SVM (calibrated for probabilities)
Combined both models using an ensemble (averaging probabilities)
Tuned classification threshold for better real-world performance
Evaluated using Accuracy, F1-score, and ROC-AUC
Challenges I ran into
One of the biggest challenges was handling multilingual and informal text, especially Hinglish (mixed Hindi-English). Another issue was reducing false positives on polite or positive sentences, where the model sometimes misclassified neutral phrases as toxic. Balancing precision and recall was also critical.
Accomplishments that we're proud of
I achieved strong performance with a ROC-AUC of ~0.95, built a fully working multilingual NLP pipeline, and successfully implemented an ensemble model without relying on deep learning. I also created a real-time prediction system that can classify user input instantly.
What we learned
I learned how effective classical NLP techniques like TF-IDF can be for real-world text classification tasks. I also gained experience in model ensembling, threshold tuning, and evaluating models using multiple metrics like ROC-AUC and F1-score instead of just accuracy.
What's next for HateSense AI
Next, I plan to improve the system using transformer-based models like BERT for better contextual understanding. I also want to enhance sarcasm detection, expand support for more languages, and deploy the model as a real-time API or web application for practical use in content moderation systems.
Built With
- colab
- matplotlib
- numpy
- openpyxl
- pandas
- python
- scikit-learn
- tf-idf


Log in or sign up for Devpost to join the conversation.