-
-
Data visualization
-
Training and validation loss during training
-
CNN model prediction
-
Binary classification
-
BERT model prediction

My name is Quan and I’m currently studying software engineer at the University of Technology Sydney (UTS). I’m working solo on the project that developed multiples NLP models to detect hate speech and built a web app where people can interact with those models.
Highlight links:
- demo link: https://hatedetect.online/
- Github (AI models): https://github.com/QuanNguyenDong/hateful-speech-classification
- Github (webapp): https://github.com/QuanNguyenDong/deploy-ml-model
Tech stack
AI
- Google Colab
- Python
- Tensorflow
Web
- ReactJS
- Docker
- Tensorflow_serving
Asset
Inspiration
Hate speech (a form of cyber bullying) can lead to severe mental health issues, contributing to discrimination, violence, and social unrest. As platforms like TikTok grow in popularity and influence, preventing hateful behaviour is crucial to ensure user safety and maintain community standard.
Detecting hate speech is more difficult than most people think. We might recognize it when we see hateful words, but there are cases when a text is hateful even without these offensive words. It also depends on the context, and different person have different opinions, making it hard to agree upon.
What it does
My project involves the machine learning models development that helps identifying the violated comments on TikTok. The model’s output will be the probability of the comment being either normal or hateful. For instance, a prediction is 75% for hateful and 10% for normal; means that the text has 75% chance of being toxic and only 10% being harmless. This is a multi-label classification, so the probabilities for each category are independent, and the total sum doesn’t necessarily equal 100%.
The project outlines the process from cleaning the dataset to building and training 3 different models, and finally evaluating/ exporting the models. For a demo, check out the link: https://hatedetect.online/
How we built it
Data source selection
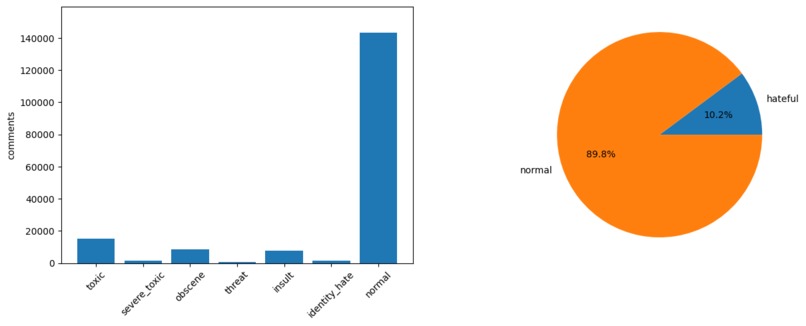
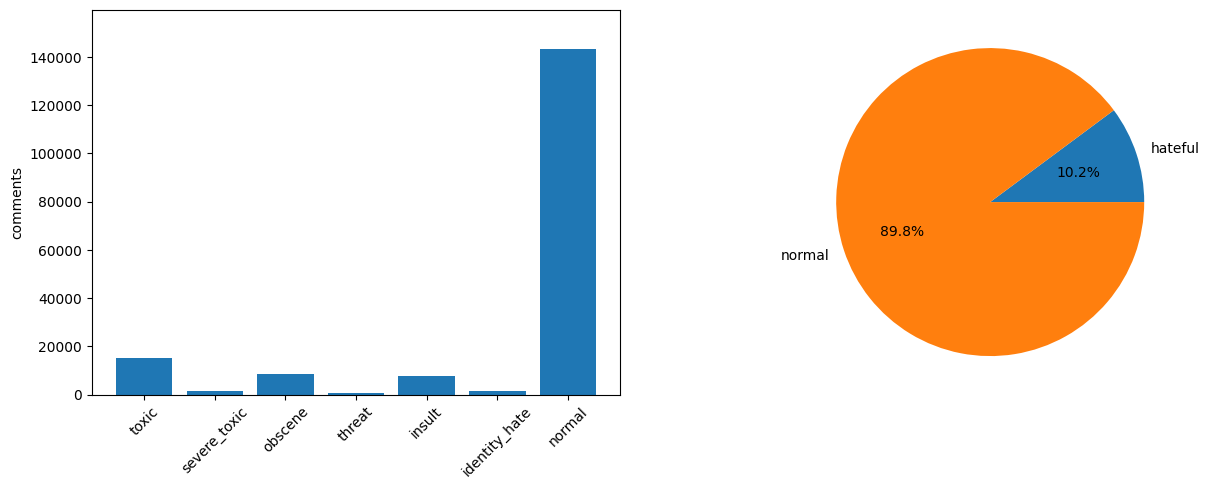
Initially, I needed a data source to develop an AI model. While there are many NLP datasets involving Twitter API, Twitter no longer allows free-tier access to tweets. I also needed to ensure the dataset is sufficiently large, as small datasets cannot predict diverse cases effectively. Ultimately, I chose a dataset of 150,000 comments with 6 labels from Kaggle.
Data analyse and clean
As the next step, I processed the comment text by removing redundant characters: URLs, non-alphabetic characters, newlines, and duplicates. I also converted the text to lowercase, stripped white space, expanded contractions (e.g., “don’t” to “do not”) and performed other cleaning operations. To ensure a balanced dataset, I resampled to include more hateful comments, equalizing the number of hateful and normal texts.
Simple neural networks
This is a basic text classification neural networks that transform text to vector in multidimensional embedding space. Then, it uses dense connected layers to learn the pattern of hateful comments. The output of model is binary (hate or normal) and the model still has limitation in capturing the full semantic meaning of words.
Convolutional Neural Network (CNN)
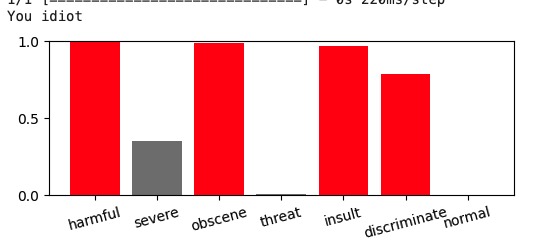
I then add some convolutional layers to the simple NN and transition to multi-label classification. By adding more CNN layers, the model extracts the local features from the text, which are use as the input for dense connected layers. This is crucial and more effective, as certain of words or phrases can be strong indicators of the hate speech.
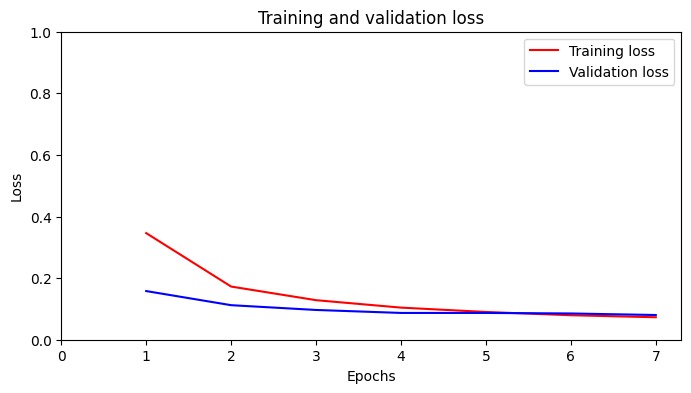
BERT model
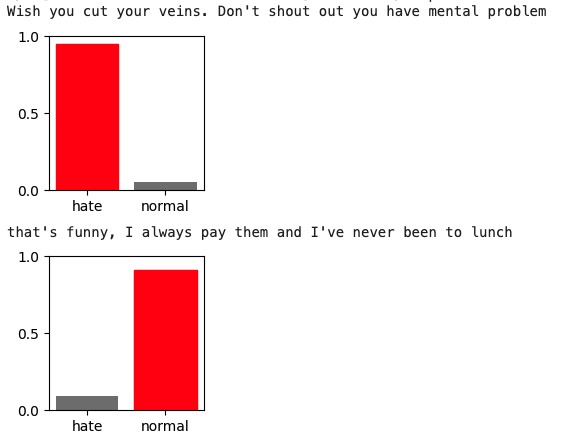
BERT is a transformer-based model pre-trained on massive vocabulary. It understands the context of words incredibly well, making it a powerful tool for hate language classification. BERT will output a dynamic embedding vector in which word representation changes depending on its context. Lastly, these vectors are fed into dense connected layers to learn the pattern and make prediction.
Challenges we ran into
Data Imbalance
One challenge I was facing was an imbalanced dataset in which normal text is significantly outnumbered hateful text. When I trained the model without re-balancing, the model predictions were imprecise and biased towards predicting text as non-hateful. I realized that this imbalance was a key factor, though not immediately obvious.
Hardware/ Resource
Limited computing resources posed a significant challenge. In the Google Colab free tier, running CNN and BERT models took a huge amount of time (up to 2 hours). This required me to spend many hours in training, testing, and iterating to find the optimal hyperparameters.
Accomplishments that we're proud of
Models
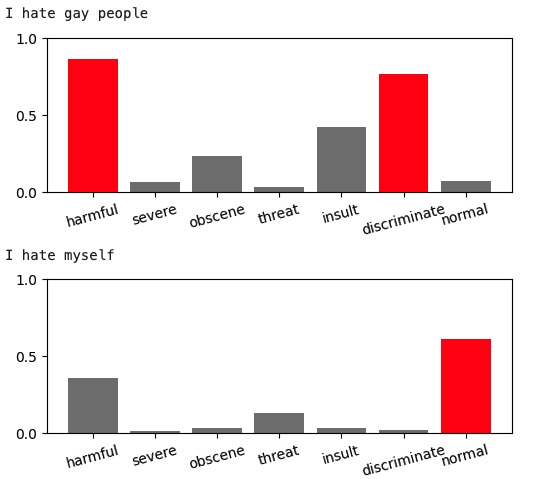
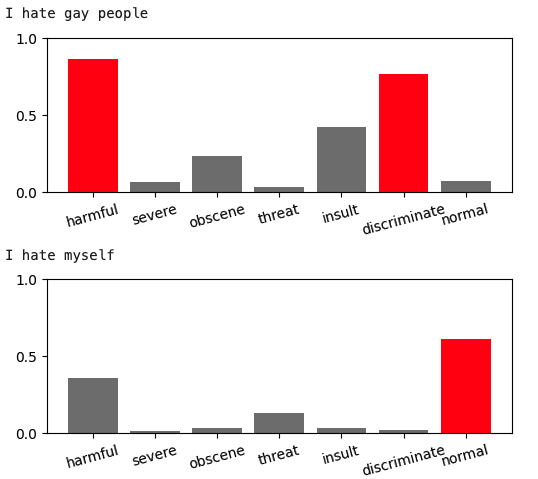
The simple and CNN models achieve 97% accuracy on the dataset. While they precisely recognize text with vulgar words, they struggle with hateful text containing only regular words. The BERT model, with 89% accuracy, requires a lot of training time but can “learn” the semantic meaning of the text. Additionally, BERT can predict more complex text. For example, the phrase “I hate myself” is:
- 98% hateful for simple NN,
- 87% hateful for CNN, and
- only 35% hateful/ 60% normal for BERT model.
Web app delivery
Having developed 3 different models, I deployed them and built a web app where users can observe the models’ evaluations without the need of coding/ AI knowledge. Users can prompt a comment and see how each model assesses whether the text is harmful or not.
What we learned
This is my first actual AI project, and I learned a great deal throughout the process, from cleaning the data source to building multiples NLP models for hate speech detection. I use Tensorflow extensively, which provided a great interface for creating layers and models. Through trial and error, I was able to apply theoretical knowledge to solve a text classification problem and optimize the training process.
What's next for Hate/Normal text classification
These models are trained on a dataset of comments for the purpose of detecting hateful comments on the TikTok platform. However, these models can also be applied to video transcripts to identify potentially harmful videos. Since audio can be transcribed into text, this transcribed text can be fed into the models, assisting TikTok to assess the videos.





Log in or sign up for Devpost to join the conversation.