Inspiration
Recursive self-improvement is the future of intelligence — and of the agent harnesses we build on top of it. But capability now comes at a ballooning cost that can collapse ROI, so cost has to be part of the objective function, not an afterthought.
Prediction markets are the ideal test-bed: verifiable outcomes, a clean ROI definition, and forecasts that depend on reasoning over messy unstructured data — exactly where agents can find alpha. And the grader is the market itself.
What it does
Harnessed Capital optimizes a forecasting genome — an explicit config that, per market category, declares all three axes:
- Which bets to engage — bet-selection params per category: an abstain threshold (θ), Kelly fraction (λ), and an EV/cost multiple (κ) that refuses bets whose payout can't plausibly clear the cost of researching them. A hard participation floor (≥5%) stops the degenerate "bet on nothing" optimum.
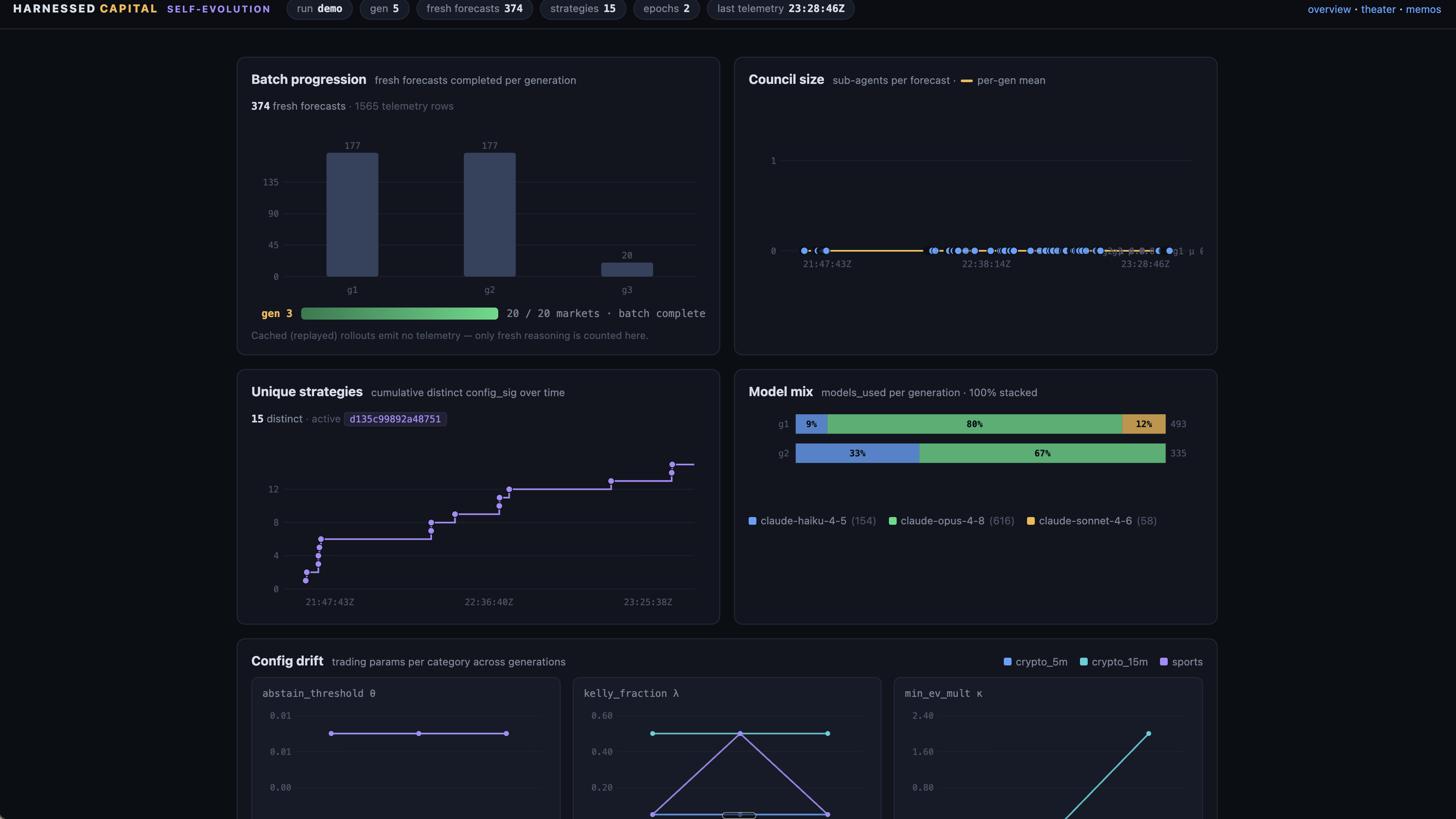
- How forecasts are made — a research policy escalating price-only → stat → news → deep → council, model tier and reasoning effort per stage, research rounds, and bounded prompt rewrites. The council policy runs quant / specialist / skeptic / base-rate persona sub-agents in parallel; a critical-assessment agent weighs them into a final probability and a cited investment memo (cited.md).
- What it costs — model tier (Haiku/Sonnet/Opus), effort, and token budget, scored on net P&L = Kelly P&L − real token cost, with a guard that calibration (Brier) may not degrade — so a config can only ever get cheaper, not dumber.
An Assessor & Improvement agent (Claude Fable 5) reads the incumbent's scorecard, its worst traces, a persistent findings ledger (theories marked validated/falsified by measured deltas, not opinion), and the tombstones of every dead config — then proposes candidate genomes. An arena-style keep-best loop accepts a candidate only if it beats the incumbent on a held-out split. Market resolution is the oracle — never an LLM judge. A live daemon locks timestamped forecasts before markets resolve, and any agent can buy the latest signal over x402.
How we built it
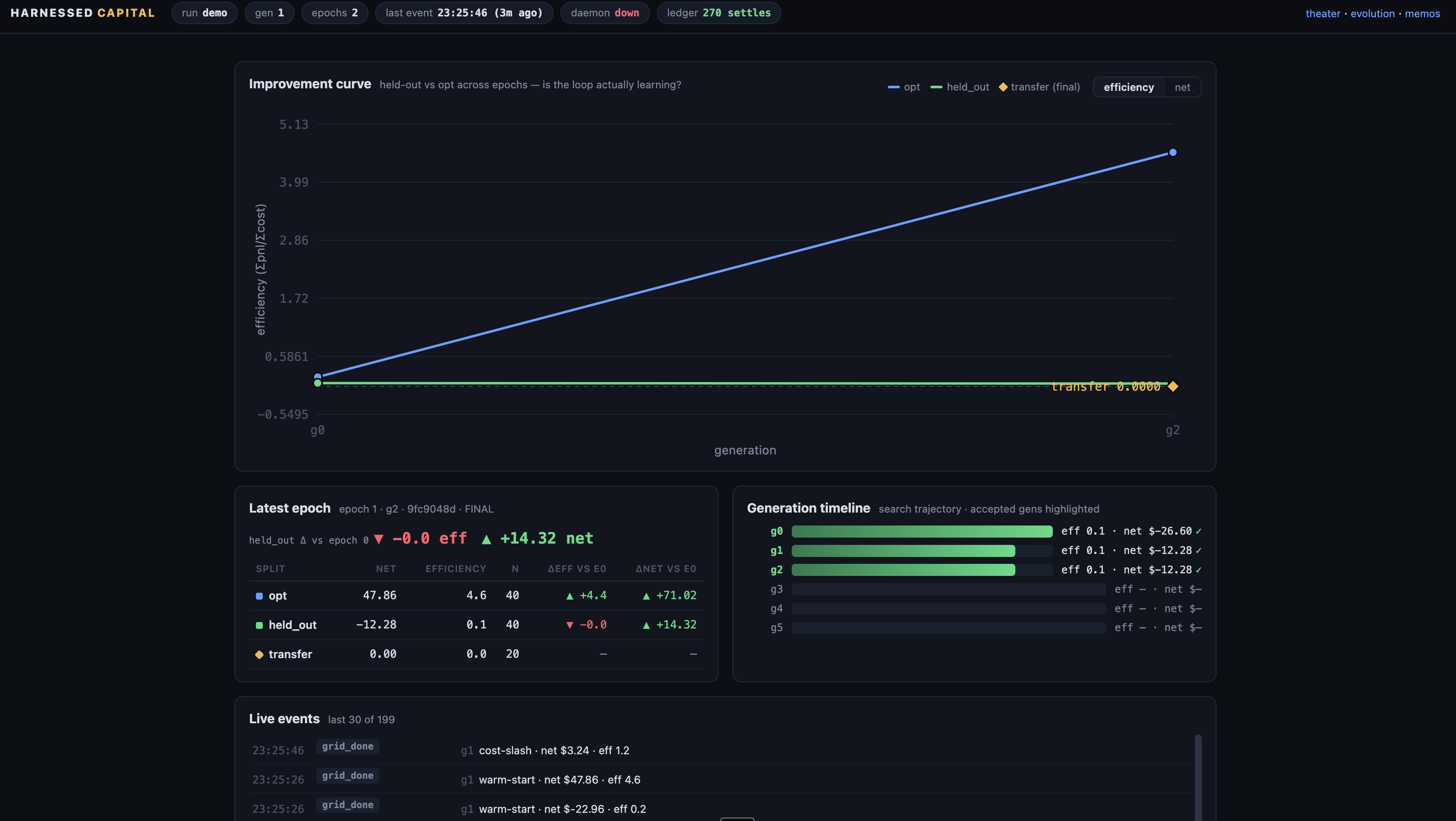
- Offline training loop (anneal.py) — keep-best hill-climb over a frozen pack of already-resolved markets, split opt / held-out / transfer. Candidates are tuned on opt; the θ/λ/κ grid is re-scored for free over cached forecasts; the winner faces held-out with no re-grid, and a transfer split stays unseen until the final epoch. Periodic epoch evals answer "are we generally improving?"
- Subscription-as-backend — every LLM call is a context-isolated headless claude -p subprocess with the API key physically stripped from its environment, hidden behind an AsyncAnthropic-shaped seam, so LLM_BACKEND=api flips the whole stack to the real API untouched.
- Cache-first determinism — rollouts key on a research signature; prompts are deterministic functions of (config, frozen pack); cache hits cost $0 and emit no telemetry, so the cost curve can't be gamed and re-runs are network-free.
- Live reasoning theater — a fail-safe telemetry tap streams every research round and council debate to a zero-dependency dashboard (vanilla JS + hand-rolled SVG).
Challenges we ran into
- Degenerate optima arrive instantly. The first thing any cost-optimizer discovers is "stop betting." The participation and calibration floors aren't polish — they're the core design.
- Public data APIs are adversarial. GDELT's 429 penalty windows extend on contact and it returns errors as HTTP-200 plain text that poison JSON parsers; CLOB rejects startTs/endTs spans over ~14 days. We shipped circuit breakers, throttles, and read-through caches; failures are never cached, so later runs backfill exactly what's missing.
- Headless Claude was never meant to be messages.create — we stripped the harness preamble to a minimal prompt, emulated structured output client-side with corrective retries, and proved via an offline self-test that keys can't leak into a sub-agent's environment.
- Keeping the eval leak-free — time-capped tools (news filtered to seendate ≤ T, price paths cut at decision time), the outcome stored in a field only the scorer reads, held-out never re-gridded, and a prospective ledger that timestamps every forecast before the outcome exists.
Accomplishments that we're proud of
- A self-improvement loop whose acceptance criterion is reality, with the anti-degeneracy guards (participation floor, calibration floor) on screen, not in a footnote.
- An honest claim, kept honest: we never claim market alpha — we claim improving unit economics at held calibration, and the epoch curve + prospective ledger prove exactly that and nothing more.
- An entire multi-model system — research councils, PM, diagnoser, memo writer — whose self-improvement loop runs on a consumer Claude subscription with no API key.
- Forecasts as products: every position ships a cited memo, and any agent can buy the live signal for 0.1 USDC over x402.
- Append-only everything — locks, settles, generations, findings, tombstones, epochs — the full run replays from JSONL.
What we learned
- Determinism is the real enabler of self-improvement — freeze the data and cache the rollouts, and config search becomes cheap enough to run dozens of candidate evals in an afternoon; the LLM bill lands only on genuinely new research behavior.
What's next for Harnessed Capital
- Let the loop run for days, not hours, with a rolling eval-pack refresh from the daemon's own settle stream.
- A world-event judgment tier (elections, Fed decisions, geopolitics) — already harvested as a leak-sealed eval set — to push optimization past fast crypto coin-flips into markets where research is the edge.
- Real capital plumbing: mainnet x402 settlement and per-category signal pricing discovered by the same annealing loop that prices research.
- Meta-annealing: promote the optimizer's own knobs (mutation breadth, lateral escape after dry generations) into the genome and let the loop tune how it tunes.
Built With
- claude
- langfuse
- python
- thesys

Log in or sign up for Devpost to join the conversation.