Inspiration
Every product that crosses the US border must carry a ten-digit Harmonized Tariff Schedule code. Pick the wrong one and you pay the wrong duty — and with 2026's tariff churn, the gap between two plausible codes has never been more expensive. Big importers have licensed brokers. A small e-commerce seller shipping headphones, candles, and phone cases has a guess and a prayer.
And here is the sharper pain: every AI tool that offers to classify for you asks to be trusted blind. None of them will tell you how often they're wrong.
Never trust an agent that won't show you its error rate.
The name is the pitch twice over: every export rides on the Harmonized Tariff Schedule, and the agent spends every night bringing itself into harmony with the federal rulings that define "correct."
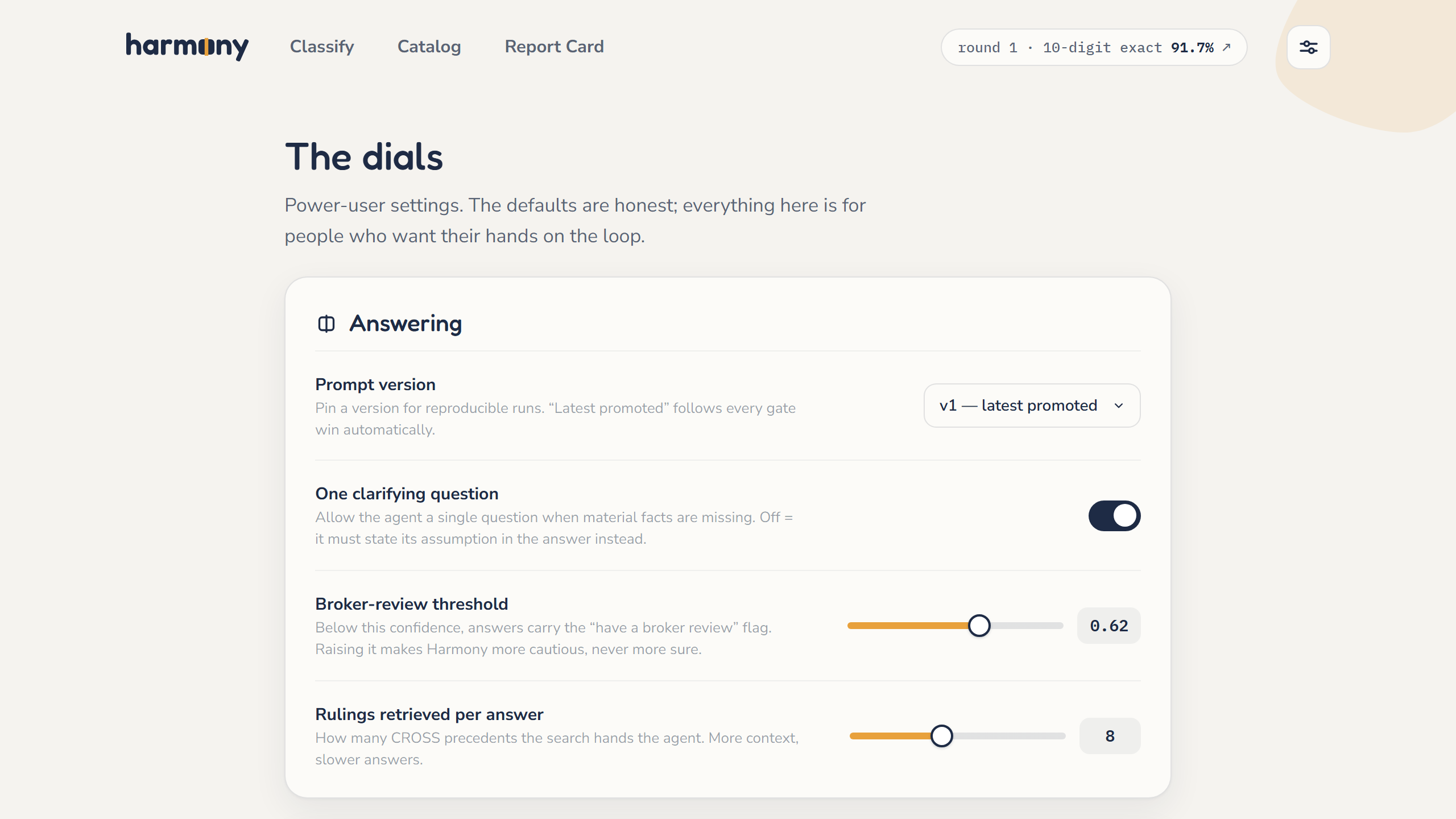
What it does
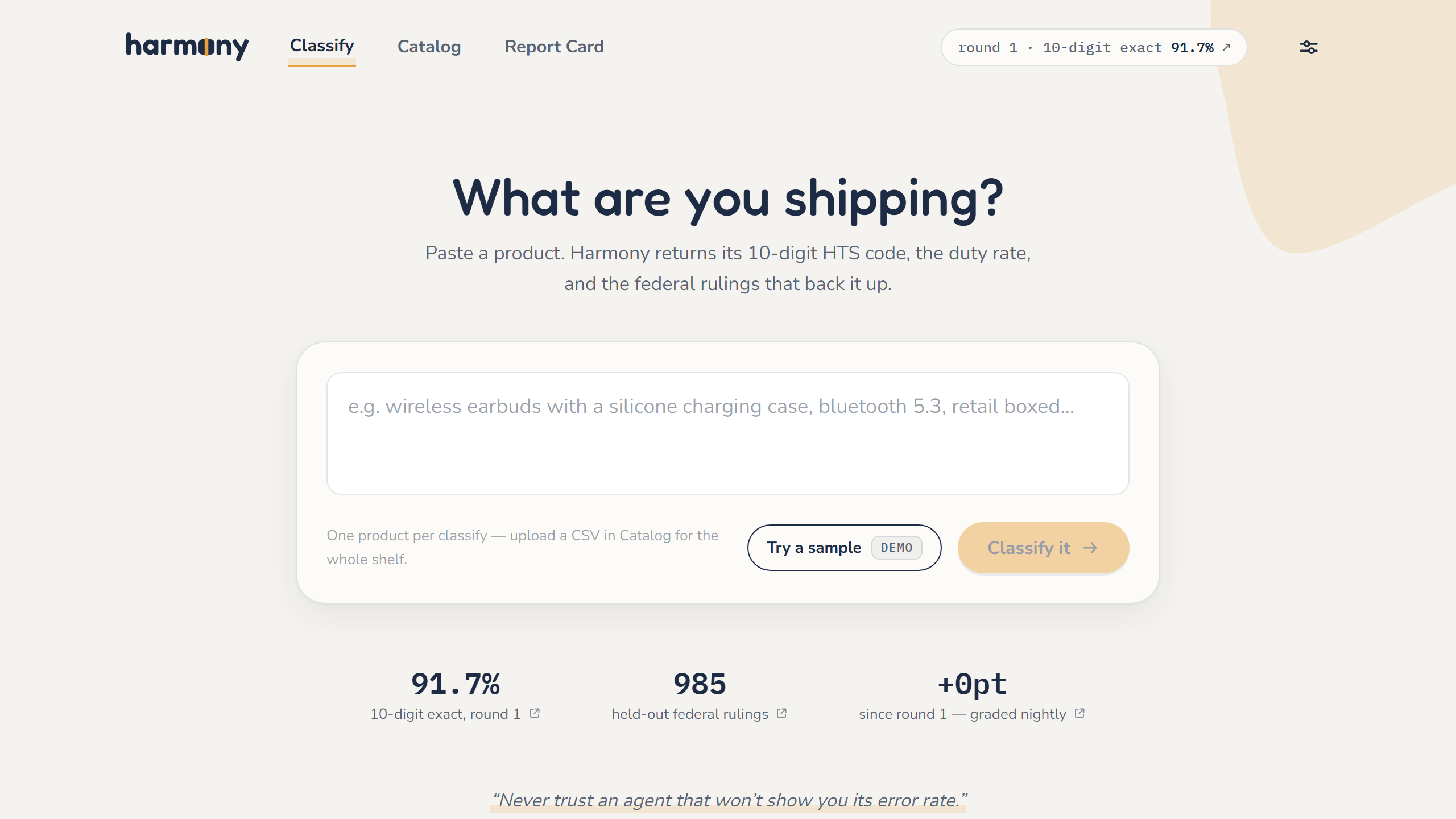
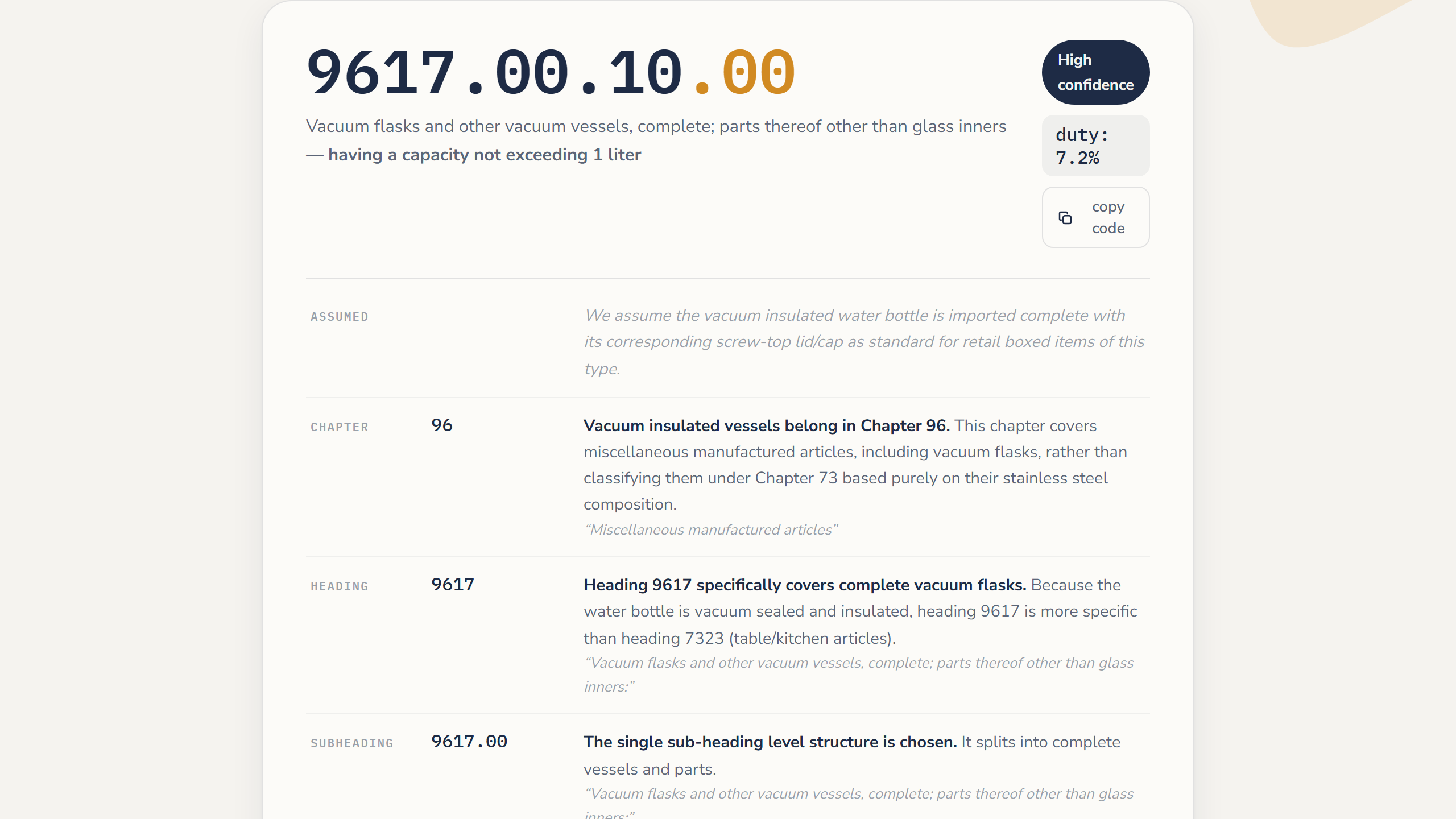
Paste a product (or upload a catalog CSV) and a Gemini agent walks the real 2026 HTS tree level by level, retrieves the most similar real US Customs (CROSS) rulings, and answers with a 10-digit code, the duty rate, an honest confidence with "have a broker review" flags, the reasoning unfolded, and the cited rulings linking to the live federal pages. Every answer carries a link to its own live Phoenix trace.
Then the headline mechanic — every night, and on demand, with no human in the loop:
- Grade. The agent classifies a held-out exam of recent CROSS rulings (all post-dating the model's training, and strictly newer than anything it can retrieve — the curve can't be memorization). Recorded as a Phoenix experiment: exact-match evals at 4/6/10 digits plus Gemini-as-judge on reasoning quality.
- Introspect. The agent reads its own misses and experiment history through the Phoenix MCP server and clusters them into named failure families. Each family becomes a Phoenix dataset, so the weakness stays measurable forever.
- Fix. Per family, two levers: a new classification rule saved as a versioned Phoenix prompt, and/or a retrieval-glossary entry ("fairy lights" → "electric garlands") so the rulings search stops missing the right precedent.
- Gate. The candidate prompt re-takes the same exam and is promoted only if it measurably beats the incumbent. Refusals stay public in the lineage. Self-improvement with a tripwire, not vibes.
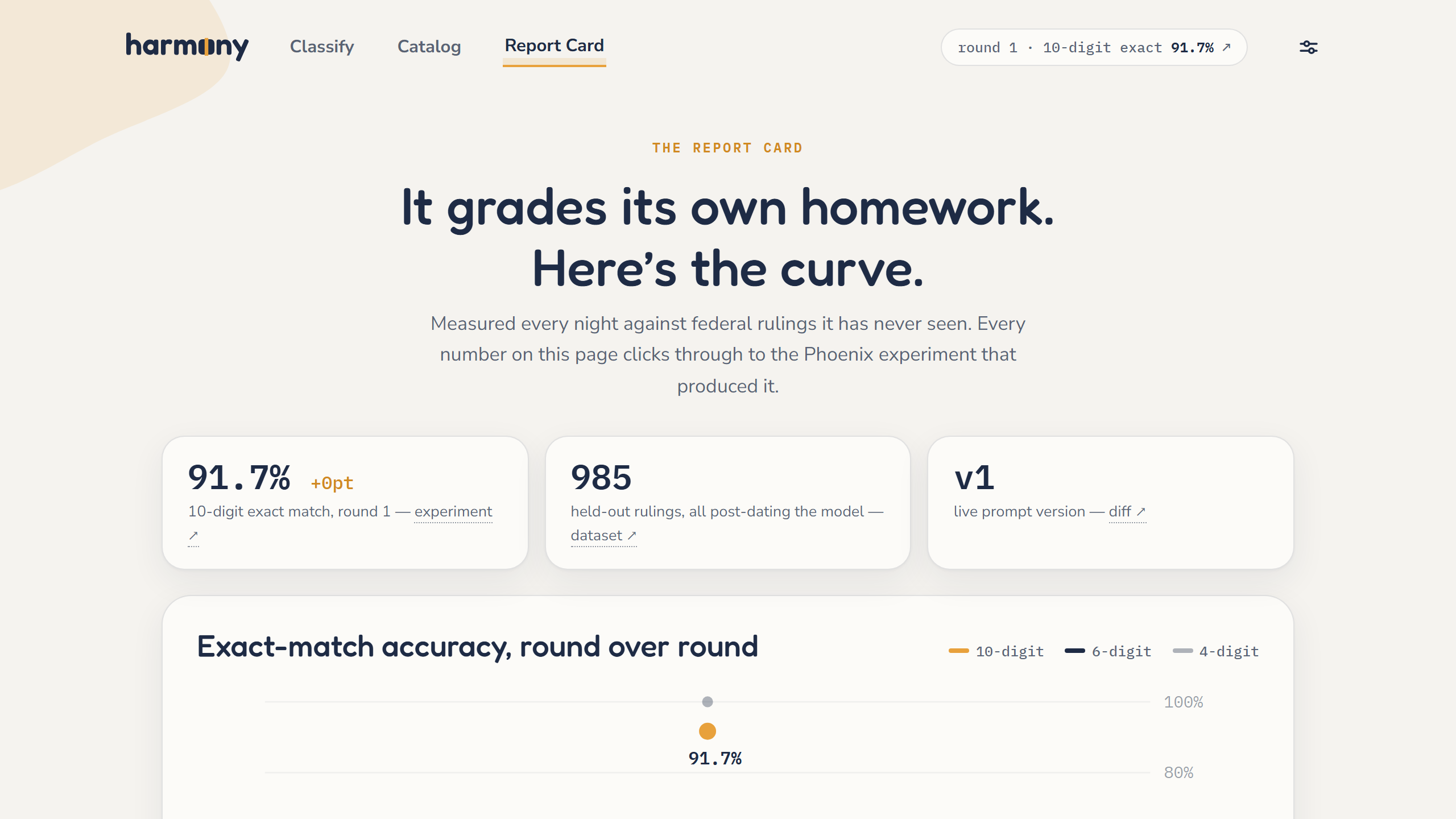
The Report Card page shows the measured curve round over round — every number on it clicks through to the Phoenix experiment, trace, or prompt version that produced it. An Improve now button runs a scoped grade → introspect → fix → gate round live, watchable in about a minute. And when a new question resembles a past graded miss, the agent quotes its own mistake before answering — retrieved over Phoenix MCP from its actual record, never faked.
How we built it
- Agent: Python, Google ADK (
LlmAgent), Gemini 3.5 Flash on Vertex AI. Tools:hts_*(walks the real 2026 HTS tree from hts.usitc.gov),rulings_search(Vertex AItext-embedding-005semantic retrieval over a scraped corpus of real CROSS rulings, glossary-expanded), andcheck_my_record(Phoenix MCP → the graded-misses dataset, mid-answer). - Observability: OpenInference instruments every agent step into Phoenix Cloud; the trace link on each result card opens that very answer's spans.
- The loop: Phoenix experiments + code evals + Gemini-as-judge;
introspection runs over the official @arizeai/phoenix-mcp server;
prompts are versioned Phoenix prompts; where the MCP server lacks a
write surface the loop uses the official
arize-phoenix-clientfor that one call — disclosed plainly in the README, never papered over. - Platform: FastAPI on Cloud Run (one service serves API + frontend), Firestore for rounds/families/glossary/lineage, static no-framework frontend. Answers are validated against the real schedule: a cited code must exist as a 10-digit statistical line, a cited ruling must actually have been retrieved, or the answer is downgraded and says so.
Challenges
- An honest exam is harder than a good score. The held-out set had to strictly post-date both the model's training cutoff and everything in the retrieval corpus — otherwise the falling curve is theater.
- MCP coverage. The Phoenix MCP server reads beautifully but lacks some write surfaces the loop needs (creating datasets, experiments, prompt versions). We drew a hard line: everything the agent reads about itself goes over MCP; the few writes fall back to the official client, and the README says exactly where.
- Trusting the agent's own citations. LLMs invent plausible codes. The fix was structural: the final answer is checked against the real HTS tree and the real retrieval results, and downgraded honestly when it fails.
Accomplishments
Round 1 is public on the live site: 91.7% ten-digit exact-match against held-out federal rulings, with the failure families named by the agent itself. And the gate has already done its job — it refused a candidate prompt that didn't beat the incumbent; the refusal sits visibly in the prompt lineage. The error rate isn't a footnote. It's the homepage.
What we learned
Self-improvement without a measured gate is just prompt drift. Putting Phoenix's experiments in the promotion path — not beside it — turned "the agent got better" from a claim into a diff. And users read honesty as competence: the broker-review flag and the agent quoting its own past miss build more trust than a fake 100% ever could.
What's next
More graded rounds and live-traffic folding (visitor classifications become next round's eval candidates), per-family drill-downs, and a second schedule (EU TARIC) to test whether the loop generalizes.
Built With
- arize-phoenix
- cloud-firestore
- fastapi
- gemini
- google-adk
- google-cloud-run
- javascript
- model-context-protocol
- numpy
- openinference
- opentelemetry
- phoenix-mcp
- python
- vertex-ai

Log in or sign up for Devpost to join the conversation.