-
-
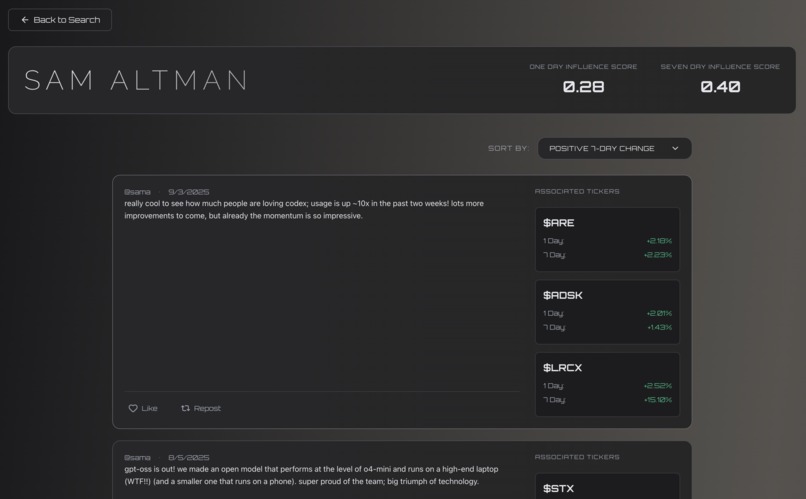
Sam Altman X Dashboard 1
-

Home Search
-
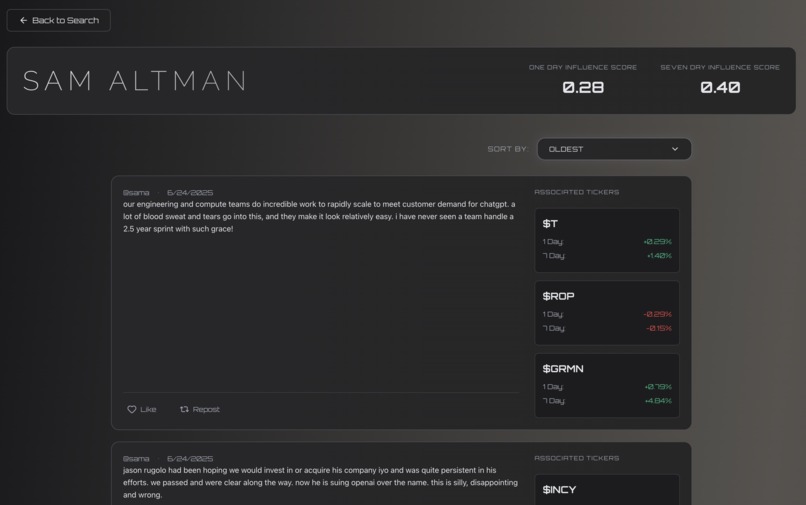
Sam Altman X Dashboard 2
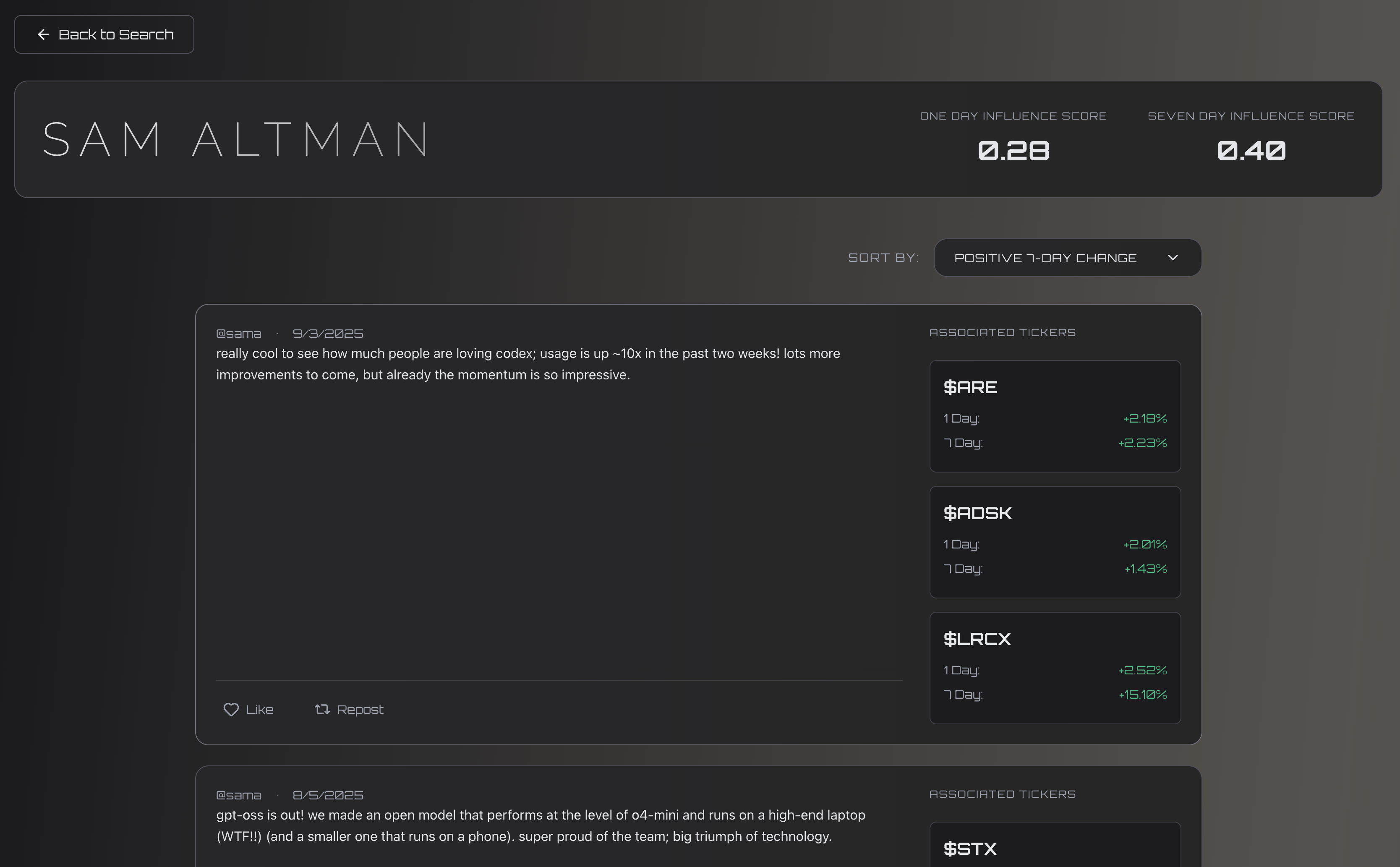

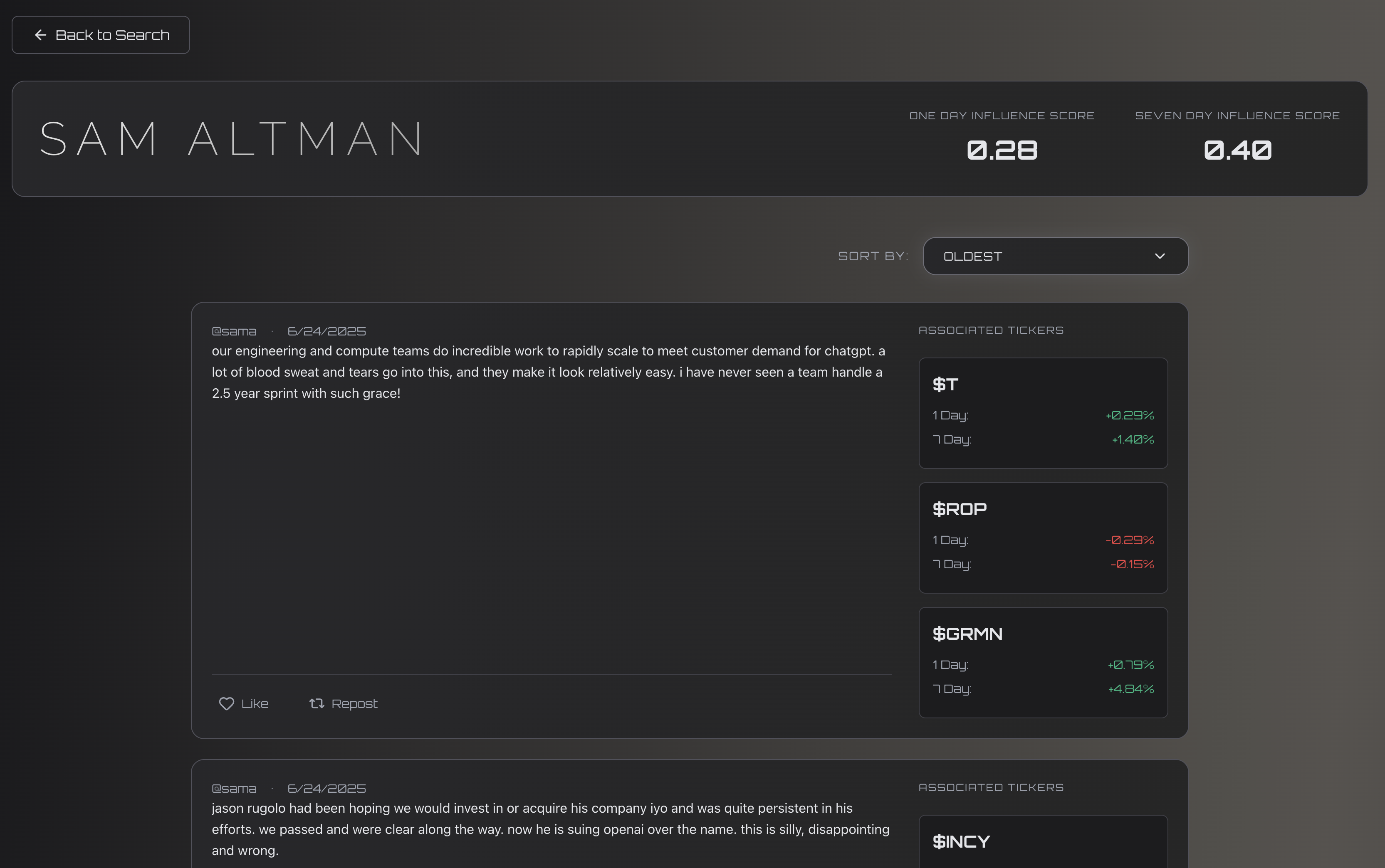
Harkonnen
Harkonnen: Finnish for “bull-ish” / “bull-like” | colloquial for optimistic sentiment on stock price.
Project Description:
The problem:
Markets are increasingly influenced by social media, but there's no transparent, systematic way to measure or simulate that impact.
- Influential figures — politicians, CEOs, financial influencers—can move billions with a single post.
- Journalists and regulators — lack the tooling and quantitative support in exposing media market manipulation. Journalists can only call out the correlation between posts and market changes, but never draw conclusions.
- Established trading platforms — shy away from calling out narrative and influence.
- Level the Playing Field — Democratize the awareness of social-media driven price changes.
The Application of Harkonnen
Process social media posts from prominent social figures (politicians, CEOs, celebrities, etc) → evaluate sentiment and market relevancy → simulate trades.
Primary Features
Price Change Analysis
- Given select tickers, ETFS, and a time-frame(1 day, 7 days), how did stocks prices change?
- Fetch financial data from yahoo financial API (hackathon friendly).
yfinance← python library
- Influence Score:
$$ \frac{\text{true positives + true negatives}}{\text{total predicitions}} $$
- Not indicative of model accuracy, rather the influence of the influencer
- Front End Dashboard
- Select/Search for politicians on social media platforms (X, Truth Social) and trigger backend data processing.
- Create a social media like dashboard where posts are printed along with the price change analysis. (Allow options to change time frames)
- Bonus:
- Create a leaderboards page
- Create a page describing our trading methods and simulations including our NLP pipeline for transparency.
- Documentation for our open source API.
NLP Pipeline For Sentiment Recognition and Semantic Market Influence
Pipeline workflow:
- Scraping: Fetch and scope raw text social media posts for a given timeframe.
- Preprocessing: Text normalization + simple Regex clean.
- Sentiment Evaluation: Detect positive/negative influence given natural language.
- Entity Extraction:
- Comb the post for any ticker’s/companies/products using an Named Entity Recognition (NER) dictionary.
- Apply Fuzzy Search (String Approximation) on a simple data set of tickers (.csv)
- Optional: Implement retrieval augmented generation(RAG) to perform semantic based search. (”Tariffs are being applied to exports to metal and minerals” → “Texas Instruments”)
- Would require creating an embedding space manually into SQLite.
REST API
- Create needed endpoints for the frontend dashboard.
- Keep good visualizations/data for demo.
- Harkonnen doubles as an open-source financial nlp API for social media posts. So creating simple endpoints for API clients and documenting them is a bonus.
🏗️ Tech Stack:
Web App
| Frontend | React, Plotly, Vanilla JavaScript |
|---|---|
| Backend | Python, FastAPI |
| Database (if needed) | SQLite |
Natural Language Processing (Python)
Natural Language Processing (Python) Project Components
NLP (Python) Project Components
Scraping
snscrapeor API calls- Worst case fallback: Kaggle Twitter dataset (hardcoded)
Preprocessing
- Regex
- Python standard library (
re, string ops)
- Regex
Sentiment Evaluation
- FinBERT (
ProsusAI/finbert)
- FinBERT (
Entity Extraction
- spaCy NER
Fuzzy Search
pandas+difflib
Optional: Semantic RAG Search
- SQLite
all-MiniLM-L6-v2embeddings- FAISS vector index
- SQLite
Visualization
- Plotly (frontend)
Rough Architecture
└── harkonnen/
├── backend/
│ ├── app/
│ │ ├── api/
│ │ ├── models/
│ │ ├── nlp/
│ │ └── pca/
│ └──tests/
├── frontend/
│ ├── public/
│ ├── src/
│ │ ├── components/
│ │ ├── pages/
│ │ ├── config/
│ │ ├── utils/
│ │ ├── App.jsx
│ │ └── main.jsx
│ └── package.json
└── venv/
VENV Setup
cd backend
python -m venv ../venv
source ../venv/bin/activate # On Windows: ..\venv\Scripts\activate
pip install -r requirements.txt
touch .env
- virtual environment working directory should be
/harkonnen

Log in or sign up for Devpost to join the conversation.