-

Splash.
-

Our stunning landing page, and where your journey begins
-
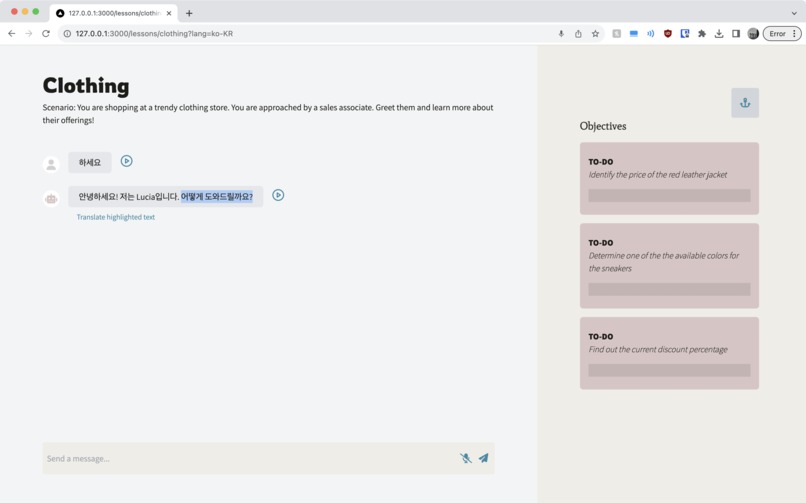
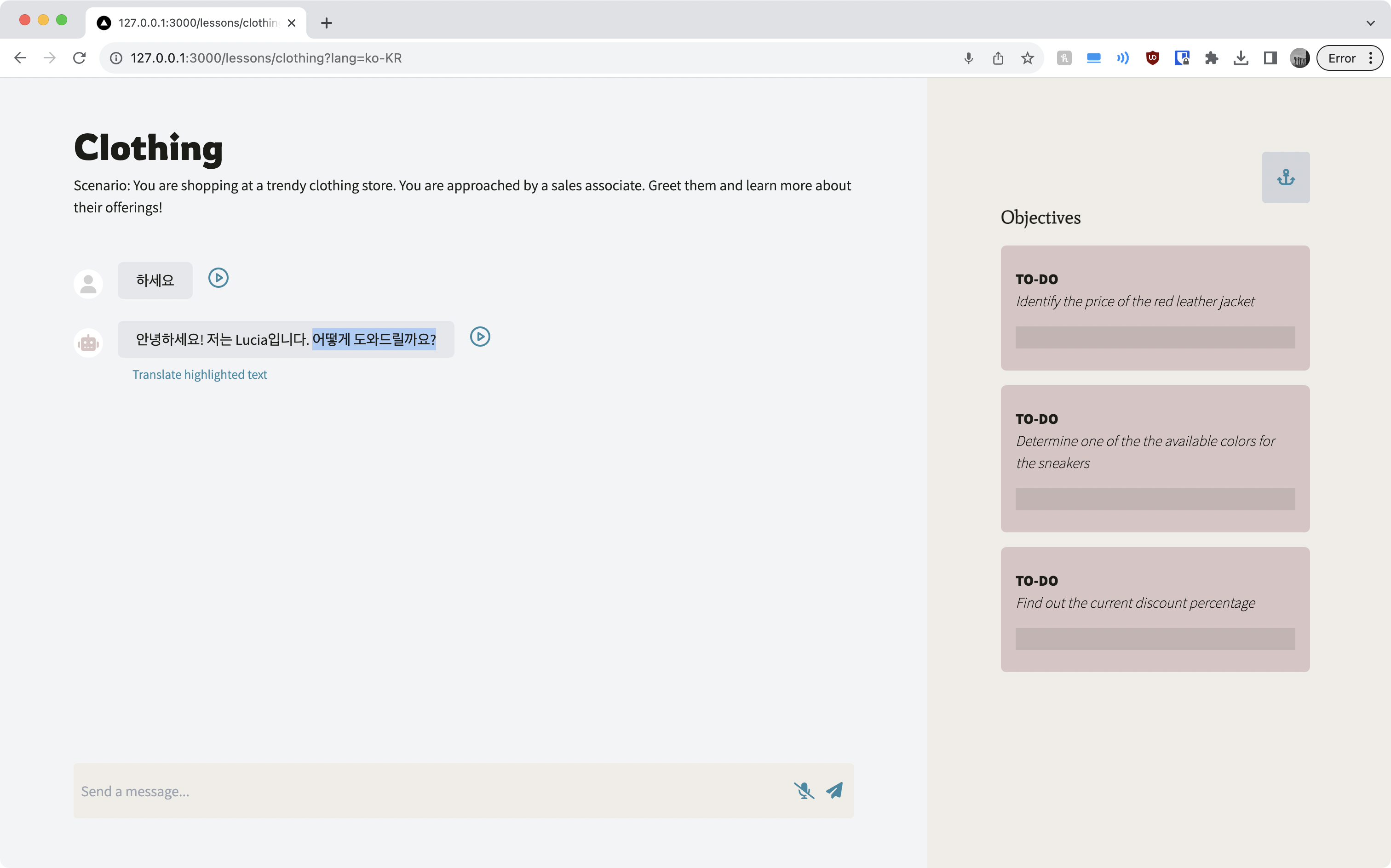
After taking on a scenario, language and vocabulary difficulty, start your conversation!
-
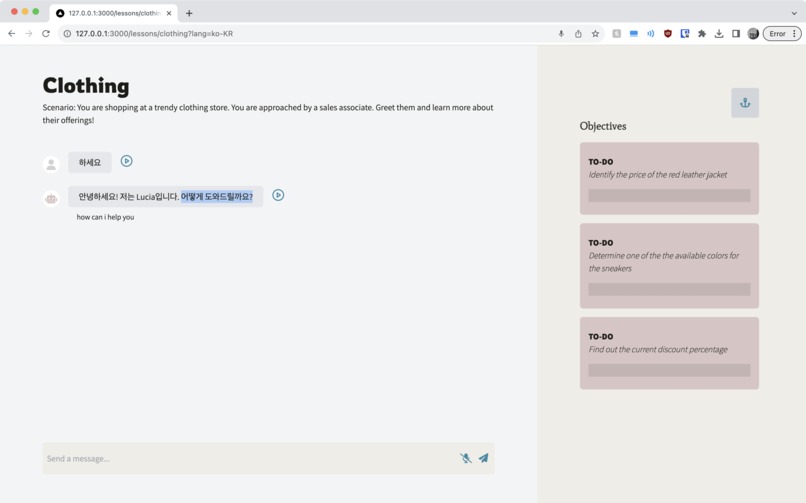
Intuitive built-in translation, speech-to-text, and text-to-speech give you extra support and further accessibility
-
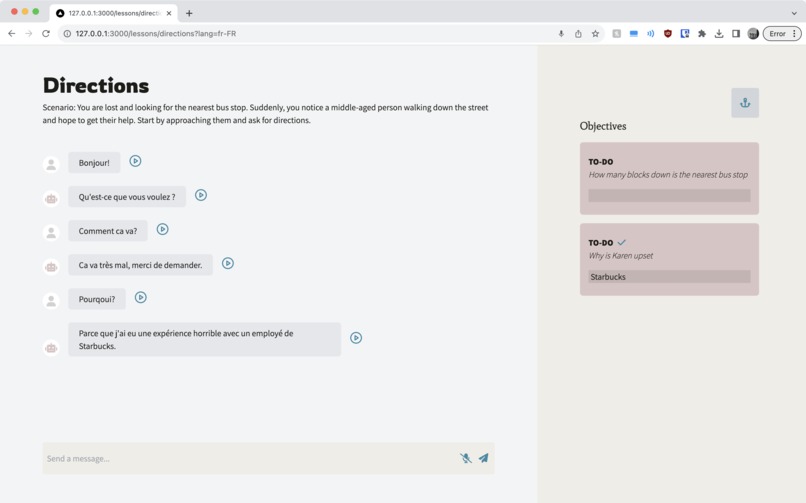
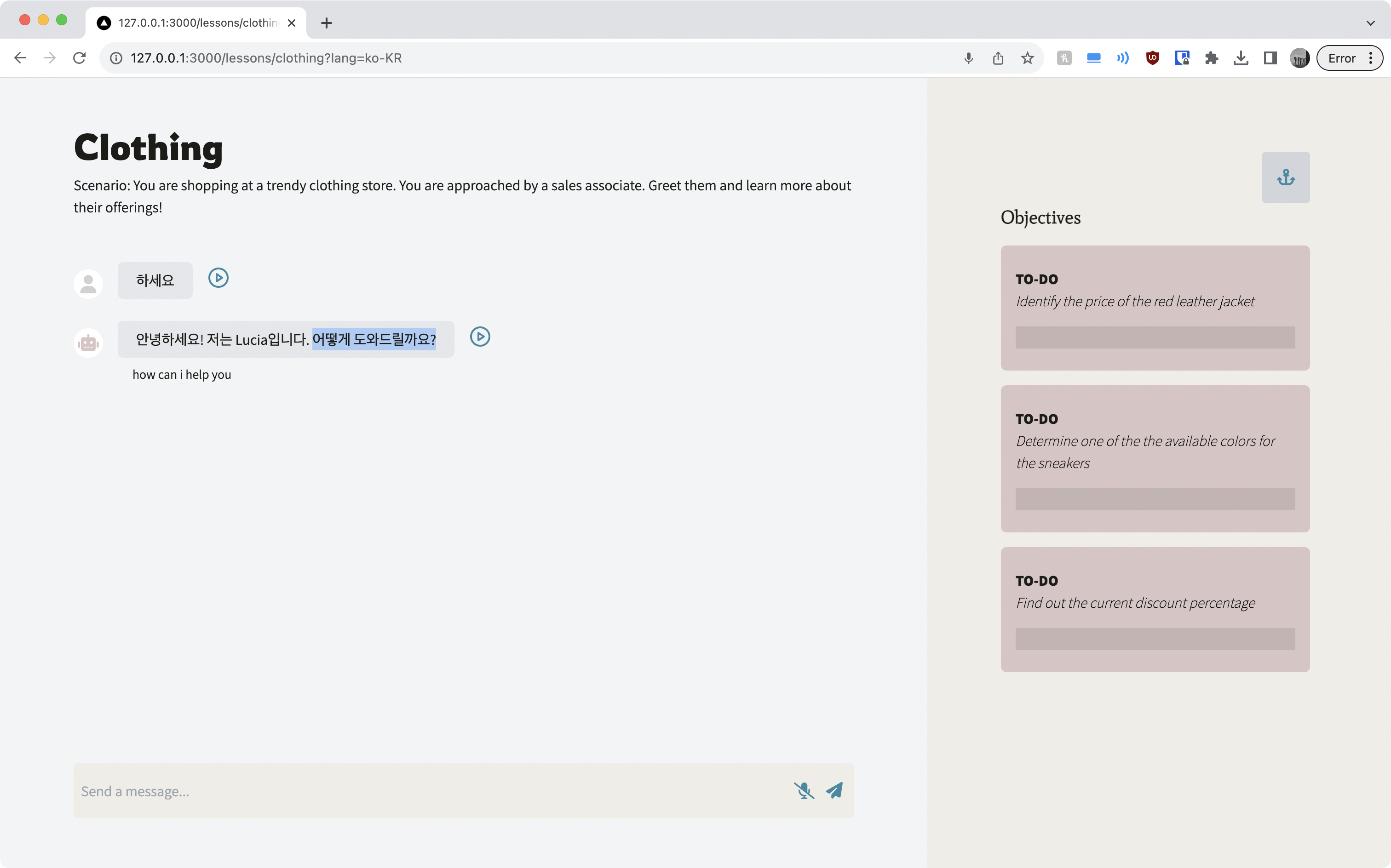
Upon discovering the answer to a scenario's objective, submit it for instant gratification!


Inspiration
When learning new languages, it can be hard to find people and situations to properly practice, let alone finding the motivation to continue. As a group of second-generation immigrants who have taken both English and French classes, language is an embedded part of our identity. With Harbour, we sought to make the practice partner that we would want to use ourselves: speaking, listening, reading and writing under fun objective-based scenarios.
What it does
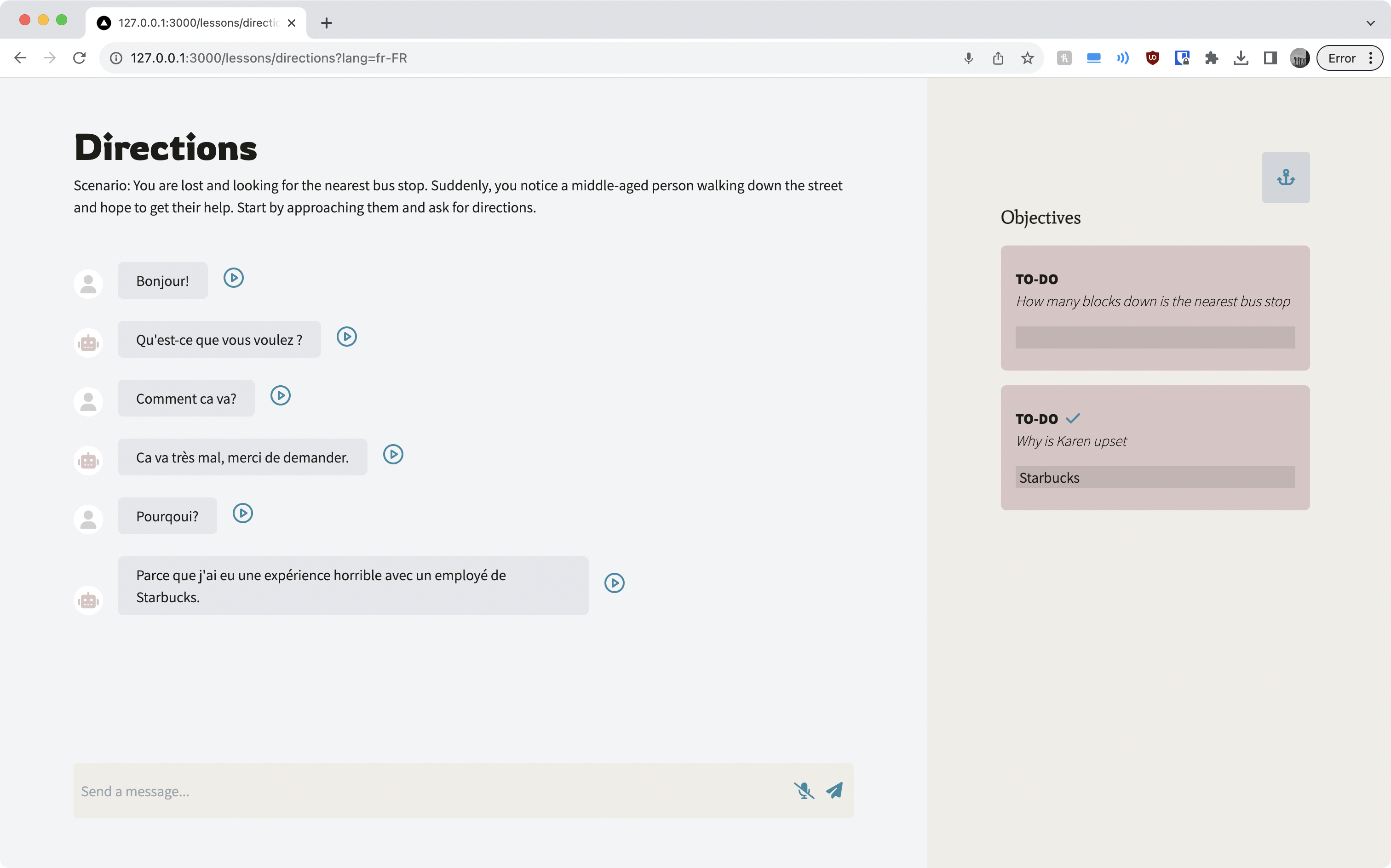
Harbour places you in potential real-life situations where natural conversations could arise, using a large-language model powered chatbot to communicate in real time. It will generate some scenarios where you can decide what language and vocabulary difficulty you’re aiming for. Adding on a fun twist, you’ll receive objectives for what to do: figure out what time it is, where the washroom is, or why your conversation partner is feeling upset.
If you ever are confused about a word or phrase the chatbot uses, simply highlight the offending text and a friendly prompt to get a live translation will appear. Additional features include text-to-speech and speech-to-text, for the dual purposes to practice oral conversations as well as to provide maximum accessibility.
How we built it
The web application for Harbour was created using Next.js as a framework for React. Next.js enabled us to create our backend which returns data the frontend requires through API requests. These were powered by our usage of the LangChain model from OpenAI for the LLM conversation and Google Cloud API for translations. Using the Vercel AI SDK also allowed us to manipulate server side event streaming to get the responses from the LangChain model over to the frontend as we received parts of the response. Text-to-speech and speech-to-text conversions were handled through the Web Speech API and the node module react-speech-recognition. Axios and fetch were used to make HTTP requests to our backend as well as the APIs used. Across our development process, GitHub was used for version control so that our four team members could each work on separate portions of the project on various branches and merge them as the pieces fell together.
Challenges we ran into
Initially, our major blocker was that the OpenAI API LLM response would be slow to respond to our prompts. This was due to us attempting to receive the API response as one JSON file, which includes the full response of the API. Due to the nature of LLMs, they typically respond in portions of content, appearing similarly to a person typing a response. The process for the whole response to be generated takes a longer amount of time, but since they are generated portion by portion, readers can follow along as it is generated. However, we were attempting to wait until the full response was processed, causing the LLM to be slow and the user experience of the product to be poorer. In order to handle this slow response, we decided to receive the data from the API in the form of a stream instead, which would send the information portion by portion in order to be displayed for the users whilst it was being generated.
However, our choice of processing the data in the form of a stream meant that it was no longer compatible with the API structure we were originally doing. This required us to restructure our API in order to process the data. We were successfully able to restructure our API in order to effectively handle the stream data and send it to the frontend that further displays the data in a similar progressively generating format to other LLM powered applications, as well as processes the data and displays it in audio format.
Accomplishments that we're proud of
We’re proud of our text-to-speech and speech-to-text features that operate alongside the messaging function of our application. These features enable learners to develop their reading, writing, listening, and speaking skills simultaneously. Additionally, they help those who may not be easily able to communicate with one skill still develop their language abilities.
We’re also proud of our team’s quick ability to learn how to and develop a LLM application, whilst it being our first time working with this type of technology. We were able to effectively learn how to create LLM applications, structure ours, and deliver a seamless user experience and product within the short timeframe of two days.
What we learned
This was all of our team’s first time creating an LLM application. Harbour is a language service centered around dialogue. With the goal of fostering a realistic connection with users, we dove into technologies centered on receiving, processing, and delivering data, as well as a fluid user experience. Specifically, we learned how to efficiently deliver required prompts to the OpenAI API in order to refine and receive the intended answer, and also how to effectively create prompts the LLM can easily understand and follow through with, to prevent unintended features or mistakes.
We also gained experience with Next.js by building a React framework for full stack development and structuring backend to process frontend requests. On the front end, we learned how to integrate React design and components with Next.js.
What's next for Harbour
Now that we’ve completed the MVP and some nice to have features, we would like to further improve Harbour by including more unique features and functionality.
One main feature of Harbour currently is the unique, almost life-like situations and experiences that the user can go through to practice their language abilities. We would like to further improve our prompt engineering to continue creating more depth in our scenarios for the users to practice with. For example, we’d like to include more levels of difficulty in our scenarios, for different levels of learners to effectively learn. This could mean including more levels of vocabulary, grammar, and sentence structure difficulty. Additionally, we would like to improve the situations to include more variety, such as creating different personalities. For example, different situations could be creating personalities that can have avid political debates, or speak to the user in a professional workplace manner.
One fun idea we’d like to implement in future versions is integrating famous personalities into Harbour. From strolling Hogwarts while chatting with Harry Potter to heating it up in the kitchen with Gordon Ramsay, who could resist talking with their favourite characters, all whilst developing their ability to speak in another language?
Built With
- github
- google-cloud
- langchain
- next.js
- openai
- react
- tailwind
- typescript









Log in or sign up for Devpost to join the conversation.