-
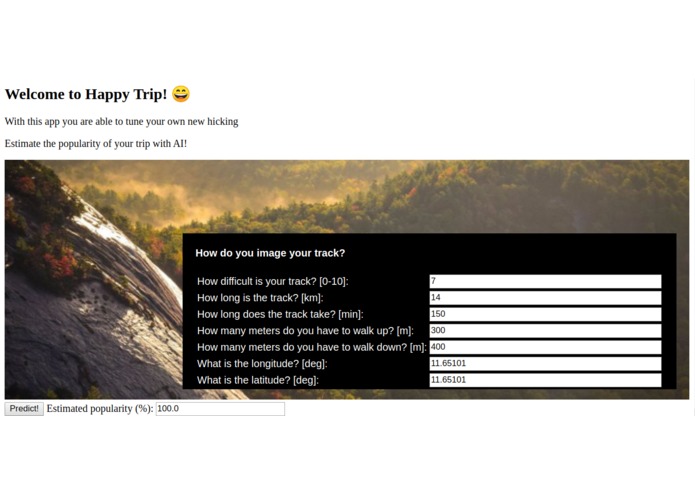
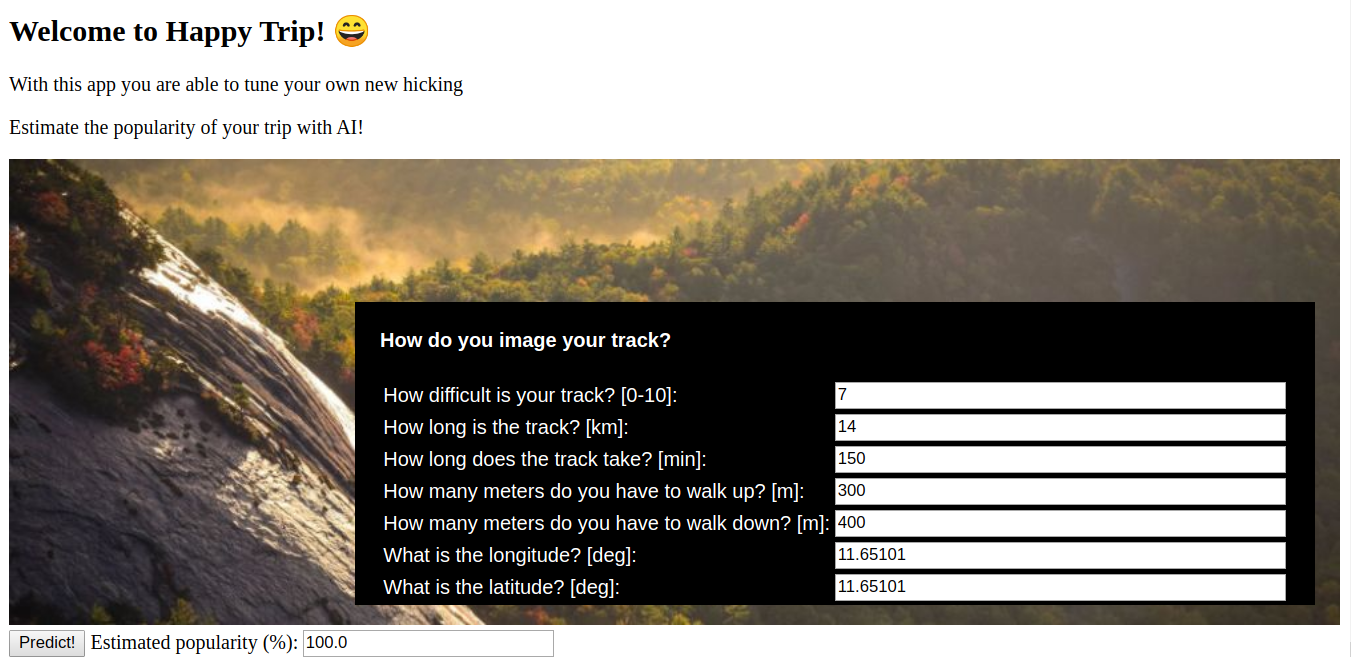
Screenshot of the web app
-
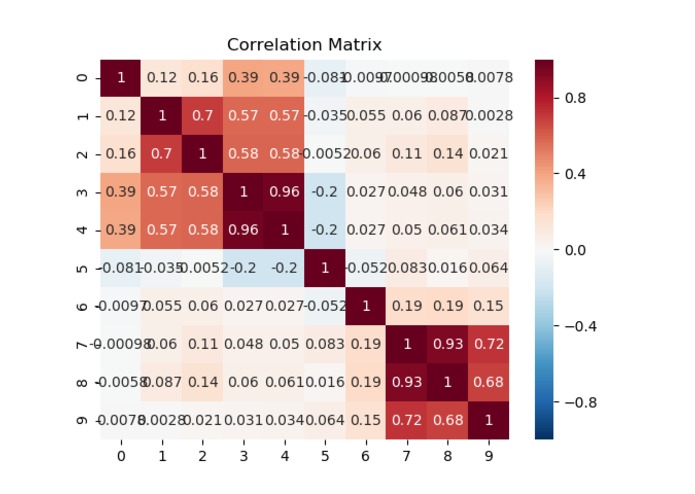
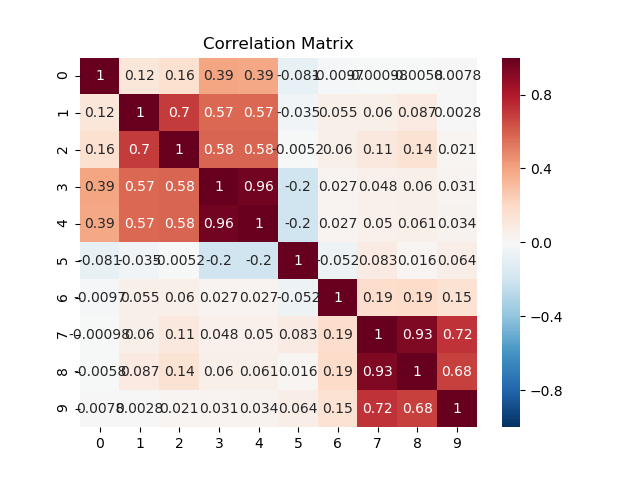
Correlation matrix of different tourism features such as difficulty, length of activity, the climb and descent in physical activities
-

Data distribution of features such as difficulty, length of trip

Inspiration
Tourist numbers are unpredictable, which leads to a poor experience for tourists in popular areas. In the peak periods, main attractions are packed and uncomfortable while in the lean period, they are empty. This leads to underutilization of tourist spaces. This also make its hard for local companies to build and manage facilities. We unlock insights from historial and current tourist data to improve the tourist experience.
What it does
Predicts tourist footfall, outdooractive page views and page clicks based on facilities present there, difficulty of activities and so on. This is used as feedback for tourism agencies and local governments to improve the tourist experience, and also by tourists to avoid crowded spots.
How I built it
Scrape tourist popularity measures from the outdooractive.com website, and tourist facility information using their Data API. Train machine learning models on this data to then predict the popularity of a tourist spot given its features.
Challenges I ran into
Fast web scraping, machine learning model tuning
Accomplishments that I'm proud of
Built a minimum viable product (MVP) with about 8 hours of effort. Used the Outdooractive API and learnt about web scraping
What I learned
New technologies and the kind of data that is present in the tourism industry, how to scrape websites. Implemented linear regression from scratch in Numpy
What's next for HappyTrip
Use more kinds of data from the outdooractive API and other sources such as Google Maps, Google review to improve the accuracy of prediction

Log in or sign up for Devpost to join the conversation.