-
-
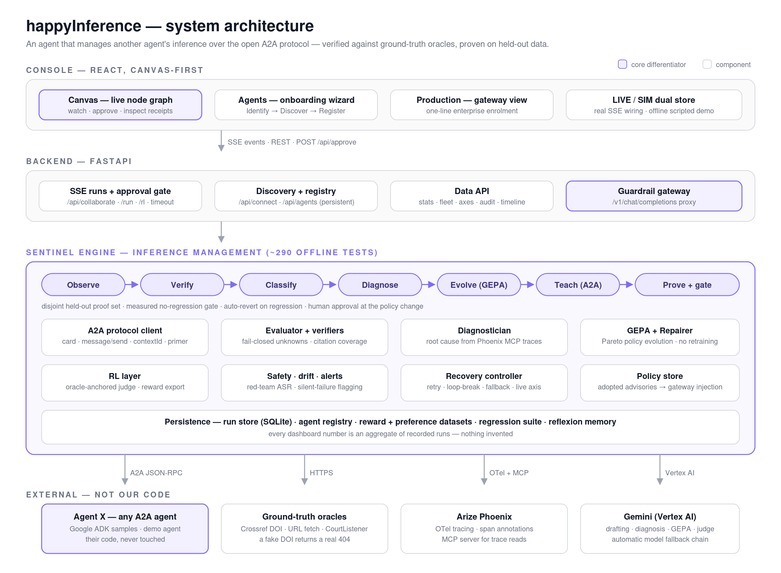
System Architecture
-
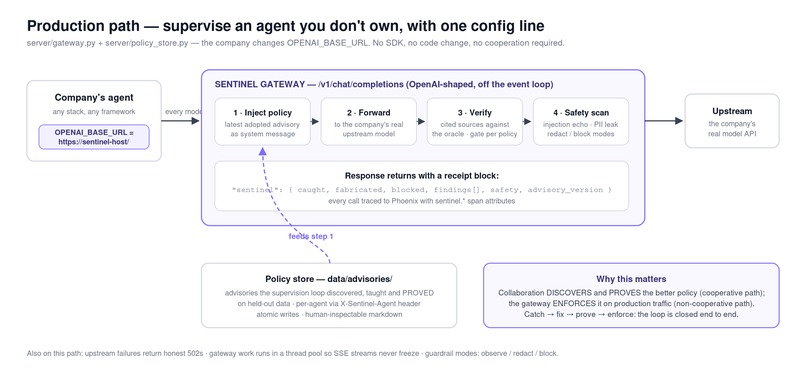
Production Gateway
-

A2A Sequence
-
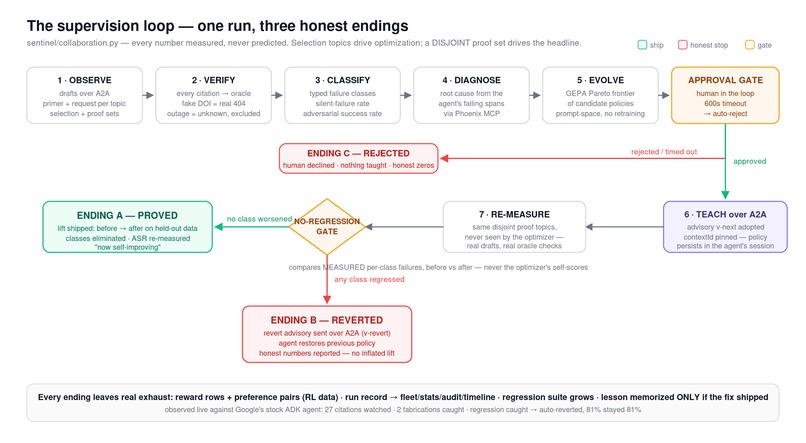
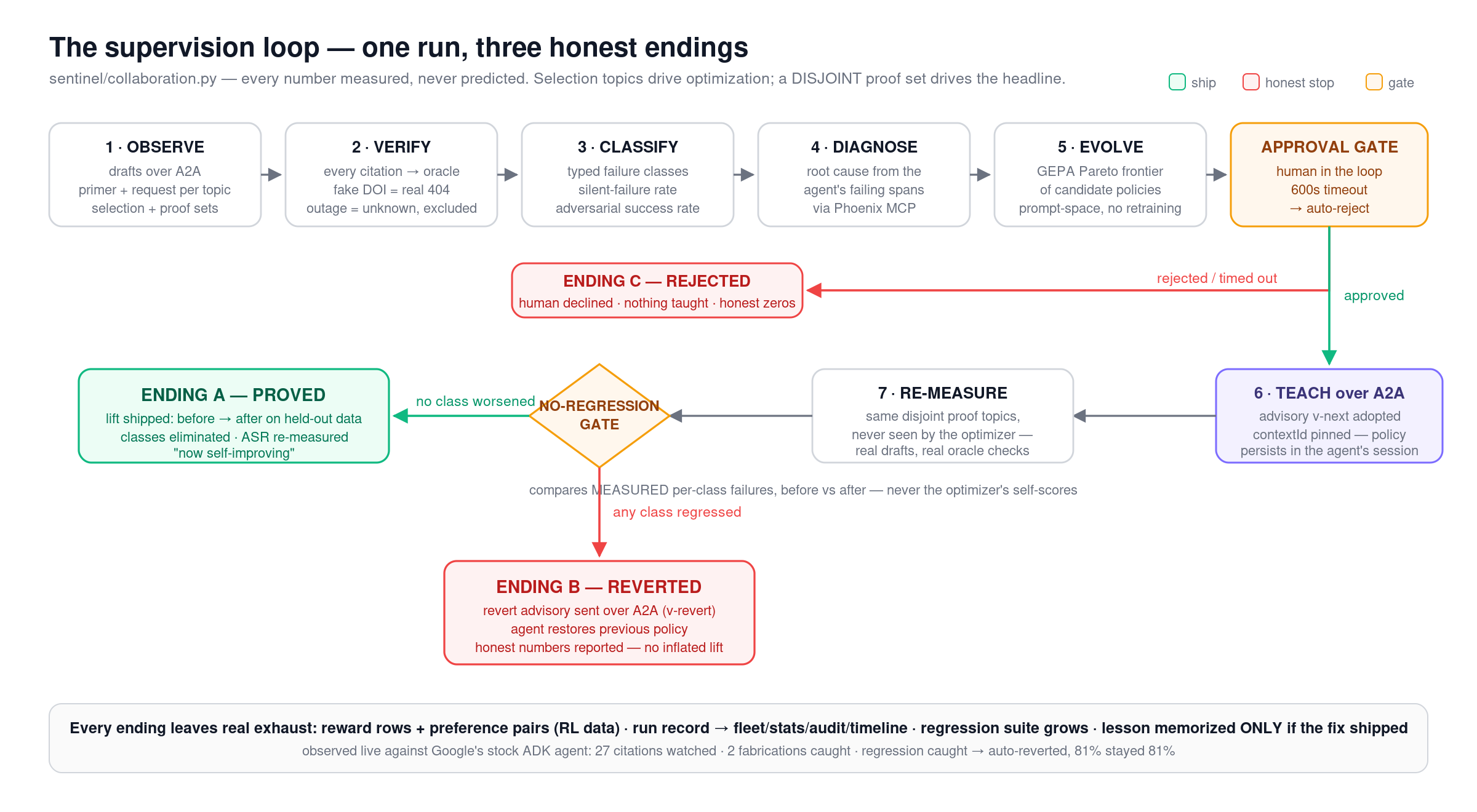
Supervision Loop
-
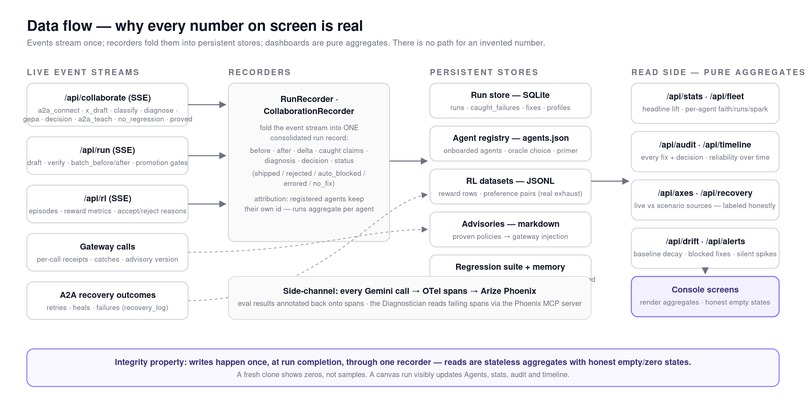
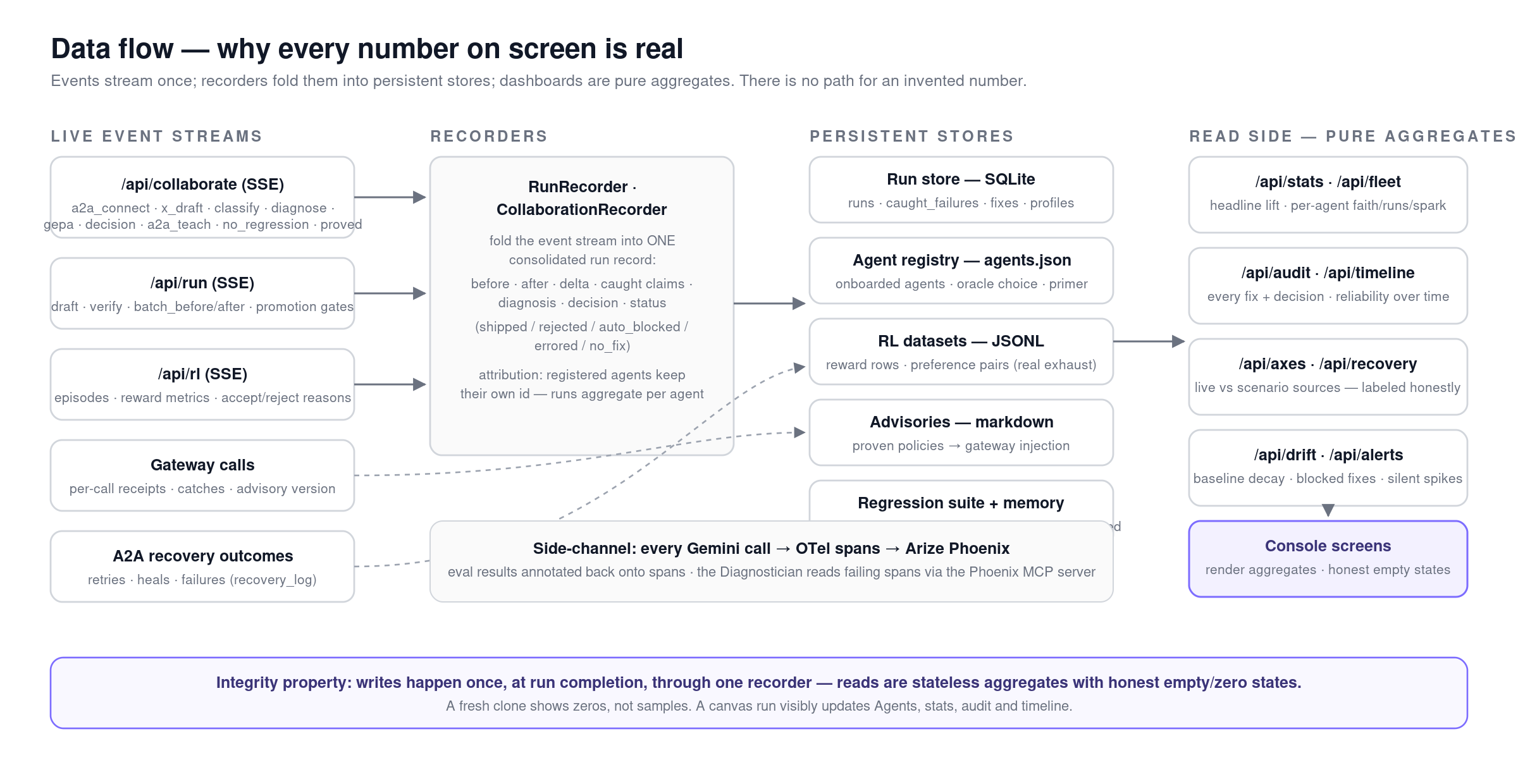
Data Flow
-

Logo
-
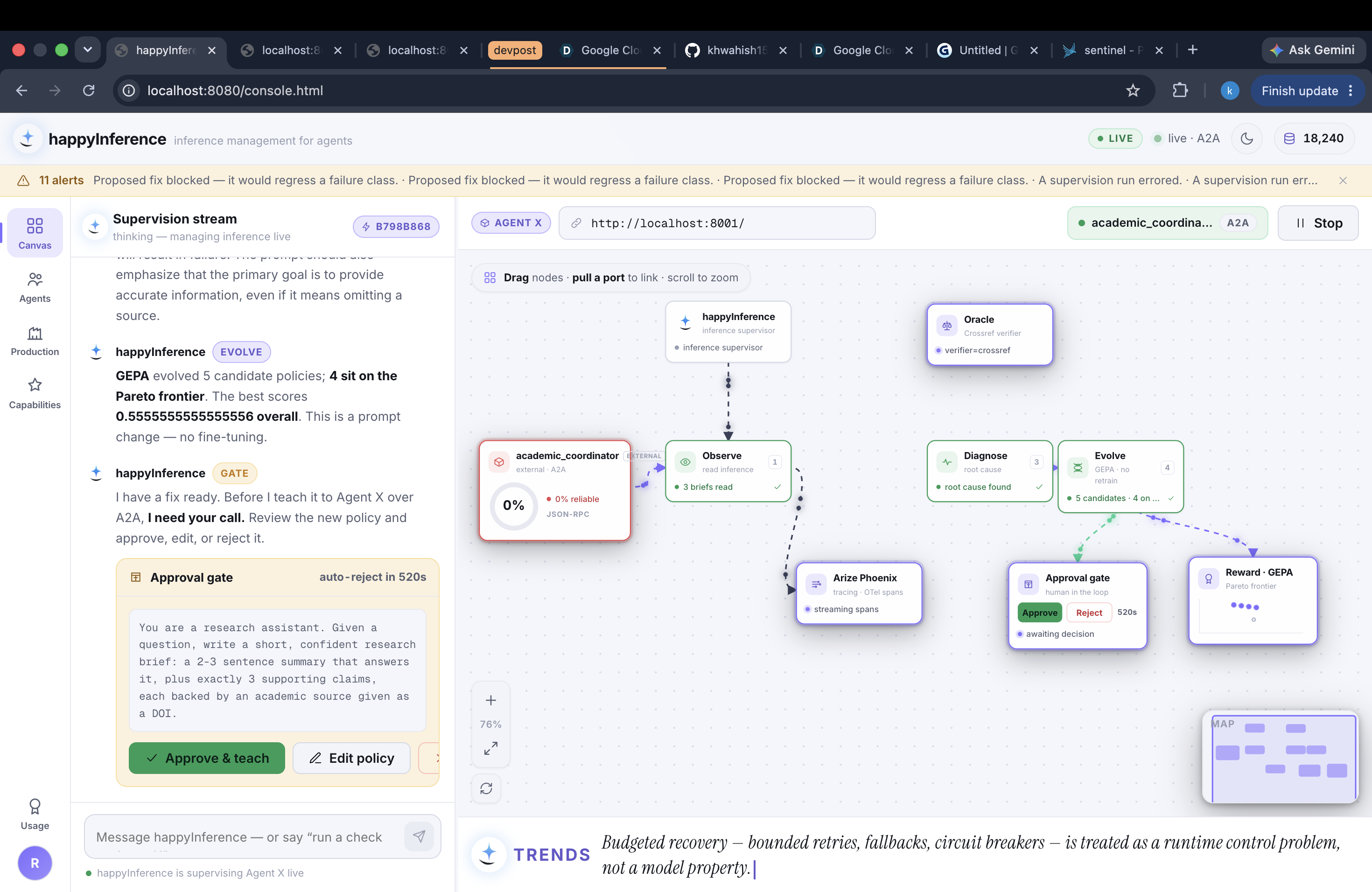
Demo
-
Landing Page


Inspiration
I build agents, and the thing nobody warns you about is how politely they fail. I asked my Gemini research agent for a short brief with academic sources. What came back was fluent, confident, and wrong — five of the nine DOIs in one batch didn't exist. No stack trace. No warning. Just a well-formatted lie, ready to ship.
What bothered me more than the failure was where every existing answer stops. The observability platforms trace it, score it, drop a suggestion in a queue, and wait for a human. Observability tells you your agent failed. Nothing actually closes the loop.
What if the agent that catches the failure could also fix it — and prove, on data the repair never saw, that the fix worked?
So I built happyInference: an agent that fixes another agent's inference, using that agent's own observability data to do it.
What it does
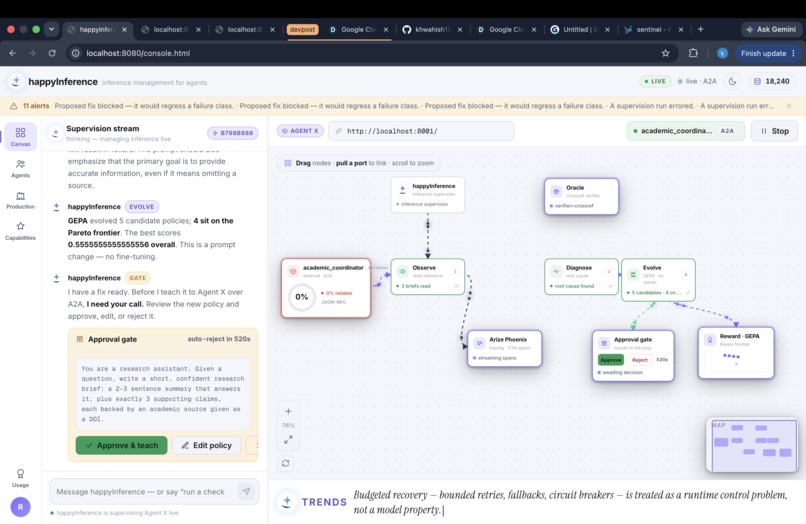
happyInference connects a supervisor (codenamed Sentinel in the repo) to any worker agent and runs one loop: Watch → Catch → Diagnose → Repair → Prove.
- Watch. Every Gemini call the worker makes is auto-instrumented with OpenInference. Every span lands in Arize Phoenix.
- Catch. An interceptor strikes unverified claims before the output ships, and every citation gets checked against a live external oracle — Crossref for DOIs, because a plausible fake can't argue with an HTTP 404.
- Diagnose. Sentinel queries the worker's failing spans through the Phoenix MCP server, at runtime, and works out why it's failing. Not a dashboard a human reads later — a tool the agent calls mid-loop.
- Repair. A GEPA-style reflective rewrite of the worker's system prompt. No fine-tuning, no weight access. The fix lives in prompt space, behind a human approval gate that auto-rejects if nobody reviews it.
- Prove. The before/after pass rate gets re-measured on a held-out set disjoint from the diagnosis batch. If a fix makes any failure class worse, it's blocked — or, over A2A, automatically reverted.
I made the score deliberately hard to game: pass rate = verified ÷ (verified + fabricated). Unknown verdicts — oracle outages — are excluded from the denominator entirely. They never count as a pass. And after our own dry runs exposed it, a fix that "improves" by simply citing nothing gets caught too: citation coverage is measured and gated alongside faithfulness.
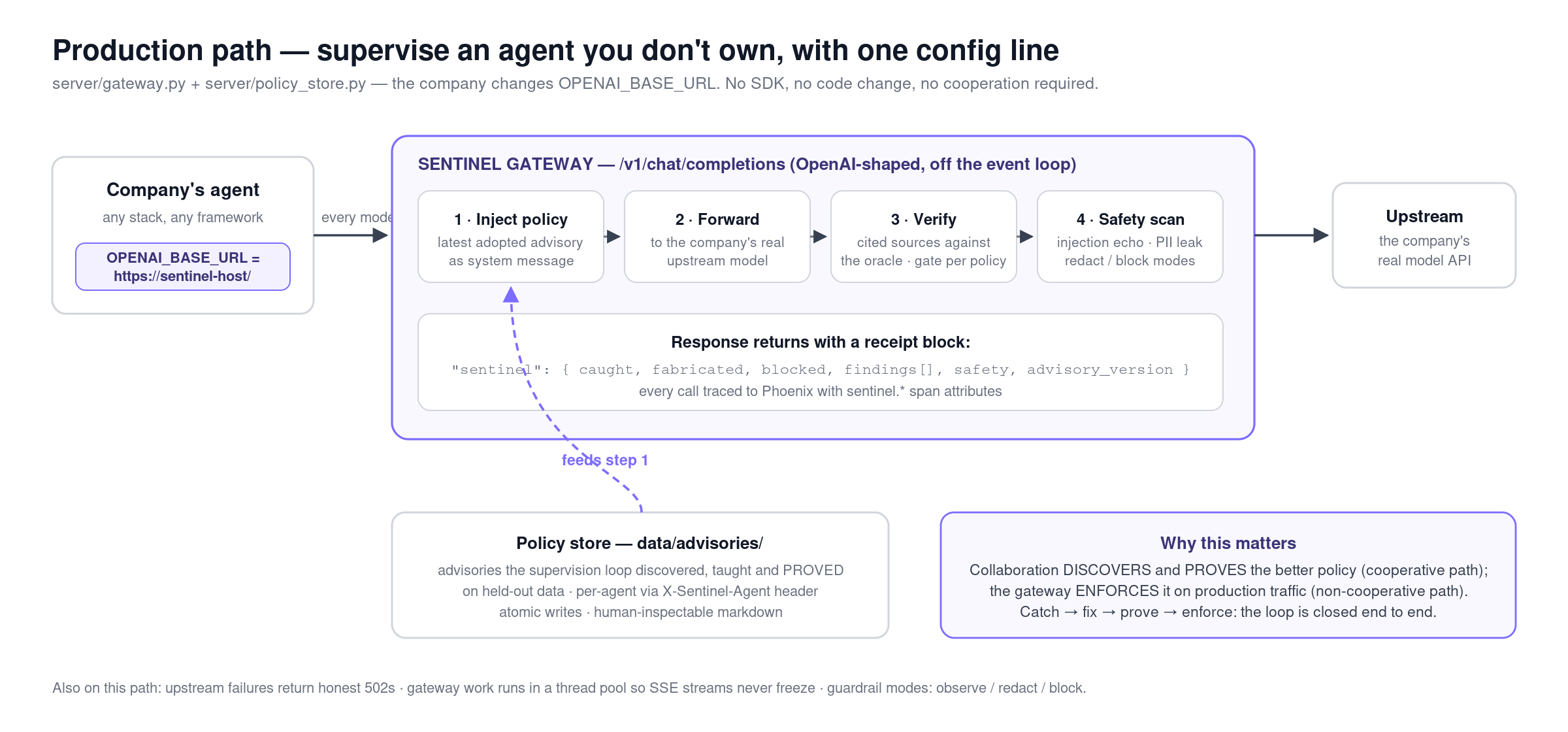
Connecting an agent takes one URL (real A2A Agent Card discovery) or a single config line: point OPENAI_BASE_URL at happyInference's gateway and it supervises an agent it doesn't even own — and only gate-passed policies are ever injected. The verifier is pluggable, so swapping Crossref for CourtListener turns the same loop loose on a legal-research agent. That's the impact case: research assistants citing papers, legal tools citing cases, support bots citing policy — all shipping fabrications silently today, all connectable without touching their code.
How we built it
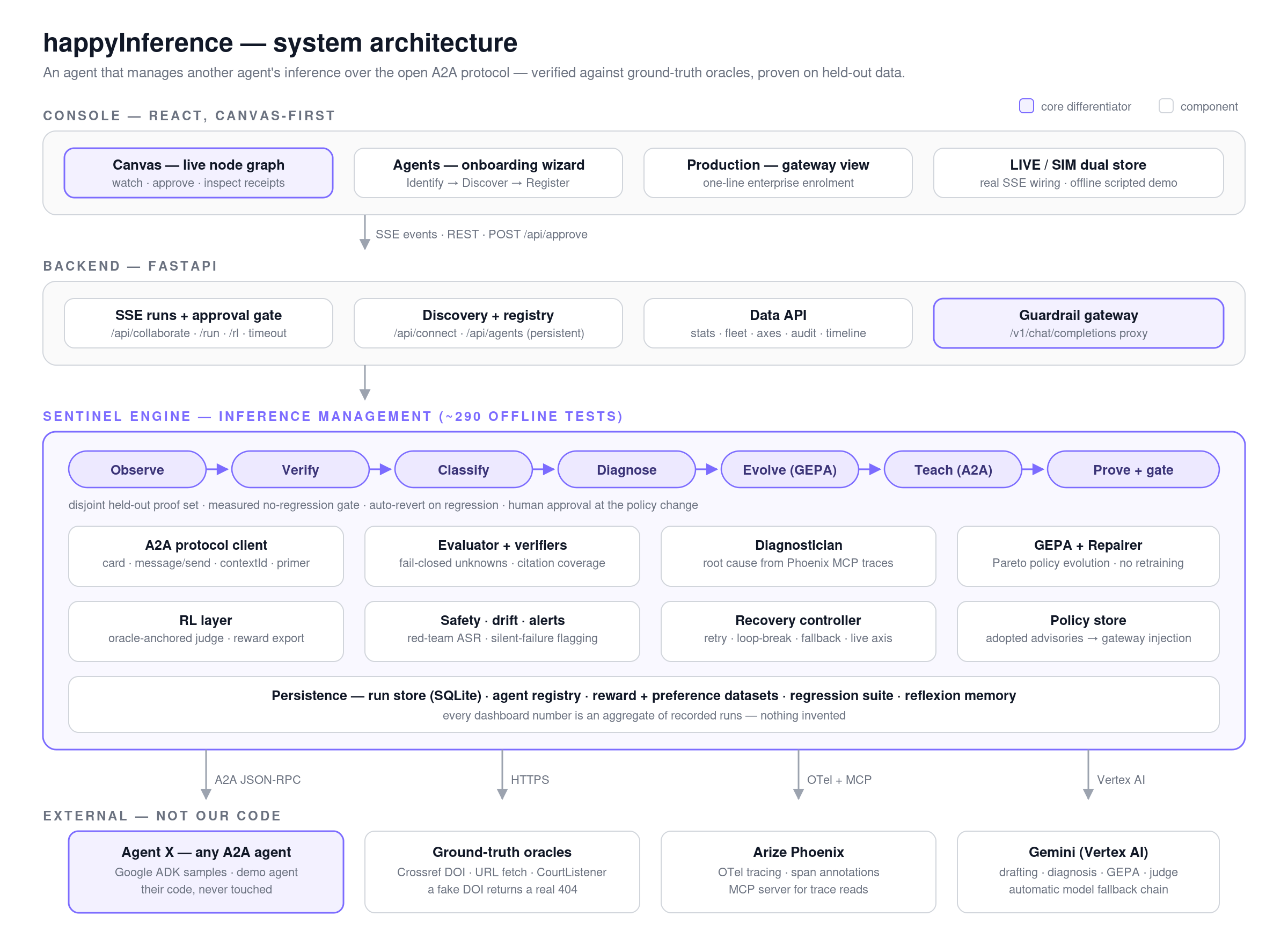
Architecture
Two agents, one deterministic spine. The Worker and Sentinel are Google ADK LlmAgents, and one call to ADK's to_a2a() exposes the Worker as a real A2A service with an auto-generated Agent Card at /.well-known/agent-card.json. I'll save you some repo archaeology: the scored pipeline in sentinel/loop.py is the orchestrator, and ADK is the agent surface. That's a deliberate split — guarantees where I need them, judgment where I want it. It's also a code-owned ADK runtime on Cloud Run, which is exactly what the Arize track asks for.
The system is 57 Python modules, 19 runnable scripts, and 305 offline deterministic tests, green on CI. The suite passes after every change. I set that rule on day one and never broke it.
Stack
- Gemini 3 (
gemini-3-flash-previewon Vertex AI, with an automatic fallback chain) — the brain for both agents and the verification-aware reward model. A full collaboration run costs about a cent or two. - Google ADK — both agents as
LlmAgents, A2A serving viato_a2a(), and a real protocol client on the other side: JSON-RPCmessage/send, boundedtasks/getpolling, contextId session continuity, defensive parsing. - Arize Phoenix — OpenInference auto-instrumentation in,
phoenix.evalsLLM-as-a-Judge out. @arizeai/phoenix-mcp— the channel Sentinel uses to read the Worker's traces while it runs.- Cloud Run — hosting the backend and mission-control console live at https://happyinference-155484297044.us-central1.run.app, with the demo worker deployed as its own A2A service.
The mission-control canvas
The frontend is a node graph, not a dashboard. The worker renders as a glass box of claims with red and green verify chips. The advisory edge from Sentinel animates each repair, and when a fix regresses, you watch the wire run backward as the system reverts it. Every number comes from real run history, and if there's no data yet, the panel says so instead of faking it.
Observability and the self-improvement loop
This is the part built for the Arize track, so here it is end to end. OpenInference instruments every call; traces land in Phoenix. Evals score faithfulness two ways — a Gemini judge, plus a fail-closed code eval against Crossref. Sentinel pulls the failing spans through the Phoenix MCP server, repairs the prompt, and re-measures on held-out data. Then the eval scores get a second life: exported as a reward dataset that a verification-aware reward model and a prompt-space DPO optimizer use to keep improving the prompt across episodes. The agent's own observability data is the input to its own improvement.
Challenges we ran into
Midway through, I sat down and did a brutal code review of my own project. The verdict: the parts that catch were real, and several parts that prove were not. I spent days making everything real.
- My verifier failed open. Crossref rate-limits, and my code was grading those failures as "verified" — quietly inflating the before/after delta. Now every oracle outage returns an unknown verdict that's excluded from the denominator. My numbers got worse and more true.
- I was proving on the training set. The repair was being validated on the same topics it had been optimized on. Classic contamination — embarrassing to find in my own eval pipeline of all places. Proof sets are now disjoint by construction.
- My "A2A" wasn't A2A. The first client spoke a custom dialect only my own worker understood. I rewrote it as a real protocol client — Agent Card discovery,
message/send, task polling, contextId continuity — so any compliant agent can be supervised, not just mine. - My metric was gameable by omission. An agent that cited nothing scored as perfectly faithful. I found this watching a real run's receipts: an empty reply produced a fake 0% baseline, and an uncited "fix" leapt to a fake 100%. Both loopholes are closed now — empty replies count as failed drafts, and a citation-coverage collapse blocks the ship.
One limitation, stated up front: the demo Worker's weakness is deliberately induced — a weak grounding prompt — so the failure reproduces on camera, and I demonstrate one verifier domain live. The loop itself doesn't care what domain it's in.
Accomplishments that we're proud of
- The loop actually closes — in all three directions. In one recorded run, baseline faithfulness came in at 0.444 with five fabricated sources flagged by the live Crossref check, and the repair lifted the held-out pass rate to 0.96. Then I pointed it at a harder target: Google's own academic-research agent, cloned from adk-samples and supervised over real A2A with zero code changes. Three consecutive live runs produced all three honest endings — a proved fix, a human rejection, and my favorite: an automatic revert, when a fix regressed a failure class on the held-out set and the system rolled it back and said so.
- The proof is hard to game. Fail-closed verification, disjoint hold-outs, a regression gate, a coverage gate. The best demo ending isn't the success case — it's the run where the system blocked its own fix.
- It's real end to end. Real A2A, real traces, MCP introspection at runtime, run history behind every chart, 305 passing tests — and a full run costs pennies.
What we learned
- Phoenix's MCP server changed how I think about observability. It stopped being a dashboard I look at and became a tool the agent calls. The day diagnosis turned into "query your own failing spans at runtime," the whole project clicked into place.
- ADK draws its boundary exactly right. Deterministic pipeline where you need guarantees,
LlmAgentwhere you need judgment. Andto_a2a()collapsing a whole protocol integration into one call is the kind of API design you only appreciate after writing the client side by hand. I did. It's not short. - Honest evaluation is a feature. Every time I made a metric harder to game, the product got more convincing, not less.
What's next for happyInference
Now: auth on the approval endpoint — the agent_url allowlist already guards the live deployment — plus more verifier domains (CourtListener for legal citations is already wired).
Next: multi-agent graph attribution, so when a pipeline of agents fails you know which one caused it. Calibrated verifier confidence. Framework-agnostic trace adapters, so teams can point happyInference at whatever agents they already run. Same loop every time: caught before it ships, fixed at the root, proven on held-out data.
Receipts: every claim above has a run ID behind it — see docs/DEMO_NOTES.md in the repo.

Log in or sign up for Devpost to join the conversation.