-

-

Drag and drop audio file
-
Two simple metrics


Most people converse with others every day. The conversation experiences can be vastly different because people communicate and react to other people differently - some are more engaging; some are more reserved; some are more assertive; some are more passive... When we think about these conversation experiences, there are those that we feel particularly good about. There are also those that make us cringe.
It is very exciting for us to build a tool that helps us analyze, visualize and understand conversations. If we can understand how we communicate, then we can find ways to improve. This way, people who are scared of conversations can take steps to overcome the barriers and contribute their thoughts and ideas; people who scare other people away from conversations can find out problems and improve.
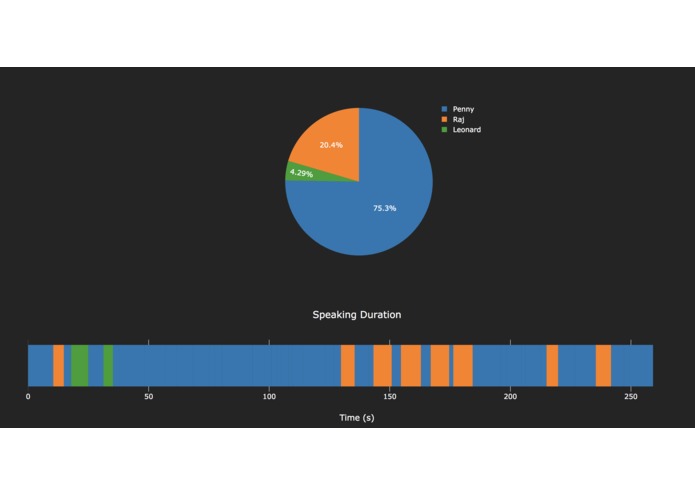
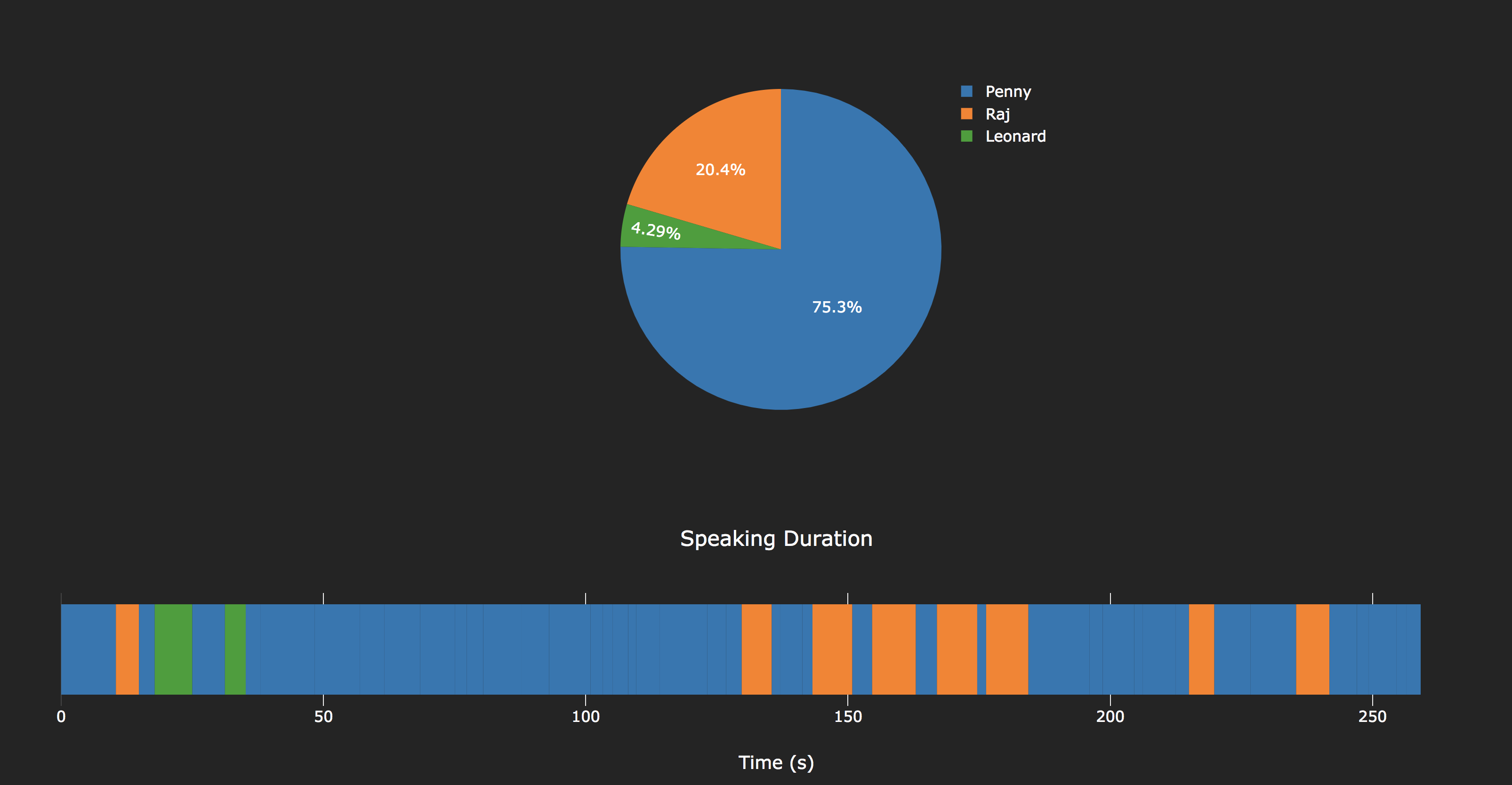
This analytical tool has huge application in the business world too. Imagine if you are an organization, you will be able to see graph representations of metrics that are of interest to you. One useful metrics can be different levels of engagement from different individuals or collective groups/teams. It can be measured by duration and frequency of speech.
In this hackathon, we built a prototype web application that demonstrates how the application can take an audio recording uploaded by user, run speaker recognition algorithms on it, and build graphs for two basic metrics: 1. duration of speech in percentile for each participant in the conversation. 2. Who spoke during which time frame of the meeting - Speaker vs Time.
For this prototype, we demonstrated analysis for an audio clip from the Big Bang Theory TV series. We also collected audio clips totaling one minute for each speaker from the show for training the speaker models. We did not showcase the training phase, which involves building a gmm model for each speaker. The prototype displays result built from running speaker recognition on the audio clip. The actual analysis takes around 3 minutes to run and we used cached result.
There were many challenges in this project:
- Find a speaker recognition library that is easy to use. Since we decided to build the web server with python, we were looking for API's and python libraries that we could use. There were not many options. Some speaker recognition libraries are not well documented. Some are too low level to use for hackathon.
- We found out that the training phase is important. With more training, we got better result.
- It was exciting for us to work on different tasks and combine them to make the final product - we set up frontend and backend separately, photoshopped some nice UI, trained the models and combined them!




Log in or sign up for Devpost to join the conversation.