-
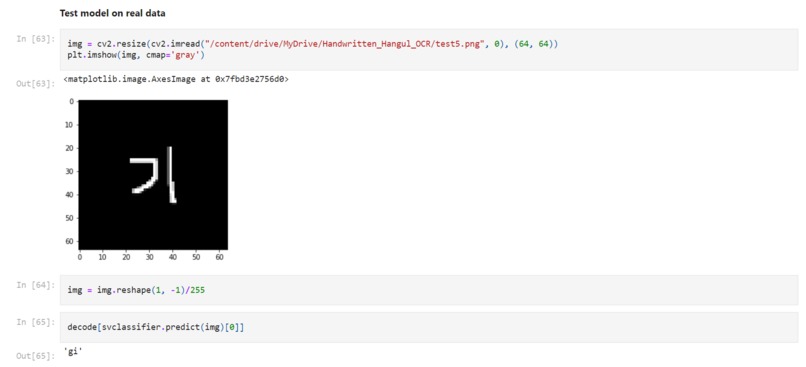
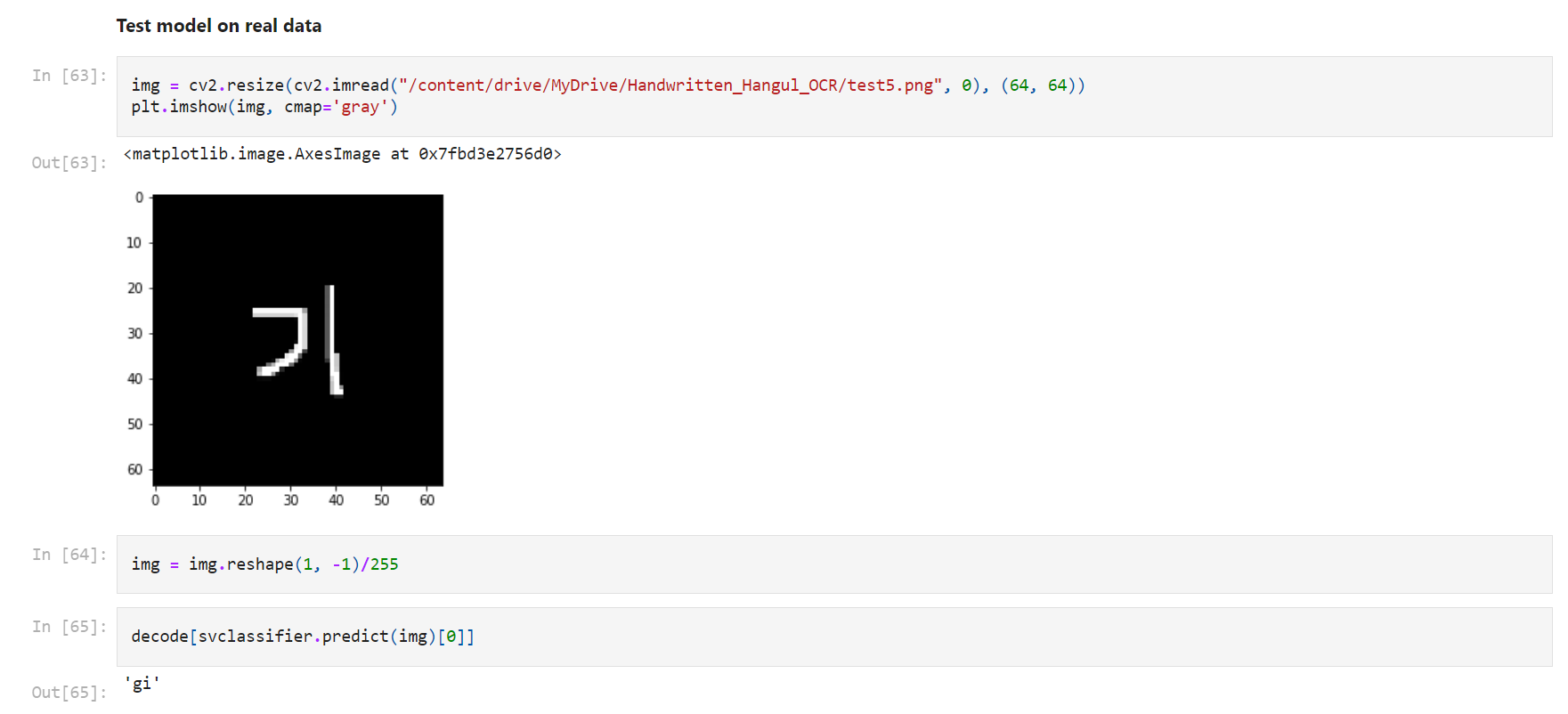
Testing model on real data
Inspiration
Korean language
What it does
It takes an image of a Korean character as an input and classifies it by using SVM classifier.
How we built it
I have used SVM to train the model and have used accuracy and confusion matrix to evaluate the model.
Challenges we ran into
Depending upon the train and test data, the accuracy of the model changes.
Accomplishments that we're proud of
Current accuracy of model - 92.22%
What we learned
Using image dataset and creating proper data
What's next for Handwritten Hangul OCR
Improving the model accuracy

Log in or sign up for Devpost to join the conversation.