

Handtrack.js: A library for prototyping hand detection/tracking applications
Existing research suggest that exploring the use of the human body (e.g. hands) as an input device can lead to more natural interaction and increased engagement. However, most systems that implement so called "body as input device" often require custom sensor and SDKs that are challenging to integrate with widely used (but resource constrained) environments like the browser. The focus on the browser, and Javascript is particularly important as Javascript continues to be the most accessible and most widely used language (see the 2020 Github Octoverse survey).

Handtrack.js aims to address this issue by providing a Javascript library that web developers (or designers) can easily use in detecting hands within images.
import * as handTrack from 'handtrackjs';
const model = await handTrack.load()
const predictions = await model.detect(img)
// img can be a html img, video or canvas tag.
For each prediction, handtrack.js returns a dictionary containing bounding box coordinates, class labels and confidence score for all identified hand poses.
//predictions
[
{
"class": 2,
"label": "closed",
"score": "0.71",
"bbox": [
170.54356634616852,
68.90409886837006,
204.50245141983032,
213.6879175901413
]
}
]
Handtrack.js is also customizable via a parameters argument to update its defaults.
const modelParams = {
flipHorizontal: false,
imageScaleFactor: 1,
maxNumBoxes: 20,
scoreThreshold: 0.6, // boxes below this threshold are not rendered
modelType: "ssd320fpnlite",
modelSize: "fp16", // base fp16 or int8 ... large, medium, small
bboxLineWidth: "2", // draw box width
fontSize: 14,
};
const model = await handTrack.load(modelParams)
Handtrack.js also comes with a set of helpful functions. E.g. to capture video content and draw/render predictions as styled bounding boxes on a provided canvas element
handTrack.startVideo(video).then(function (status) {
console.log("video started", status);
if (status) {
const predictions = await model.detect(video);
model.renderPredictions(predictions, canvas, context, video);
}
});
A complete list of helper methods provided by handtrack.js are listed below:
model.getFPS(): get FPS calculated as number of detections per second.model.renderPredictions(predictions, canvas, context, mediasource): draw bounding box (and the input mediasource image) on the specified canvas.predictionsare an array of results from thedetect()method.canvasis a reference to a html canvas object where the predictions should be rendered,contextis the canvas 2D context object,mediasourcea reference to the input frame (img, video, canvas etc) used in the prediction (it is first rendered, and the bounding boxes drawn on top of it).model.getModelParameters(): returns model parameters.model.setModelParameters(modelParams): updates model parameters withmodelParamsdispose(): delete model instancestartVideo(video): start webcam video stream on given video element. Returns a promise that can be used to validate if user provided video permission.stopVideo(video): stop video stream.
It provides as a useful wrapper to allow you prototype hand/gesture based interactions in your web applications without the need to understand the underlying machine learning models.
Impact and Use Cases
Handtrack.js goes beyond training/optimizing a set of models for object detection, to providing a clean set of abstracts to enable developers prototype hand detection/tracking use case. Some of these use cases include:
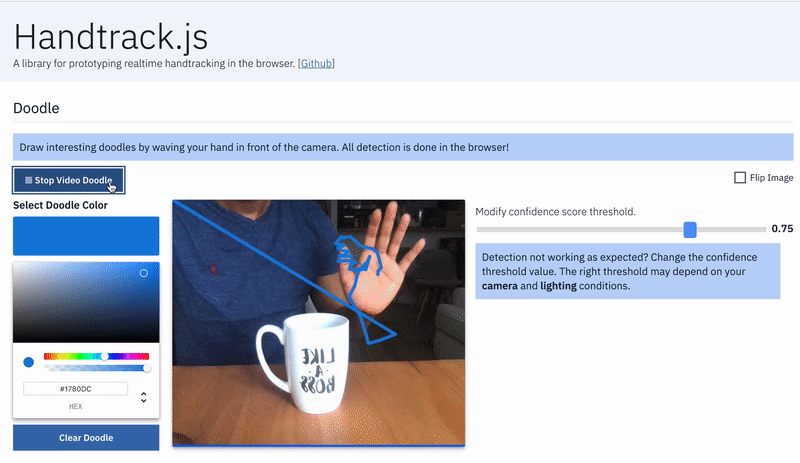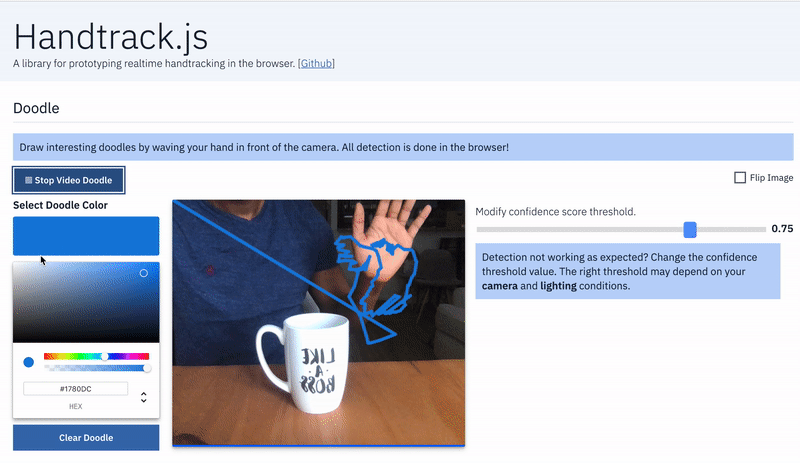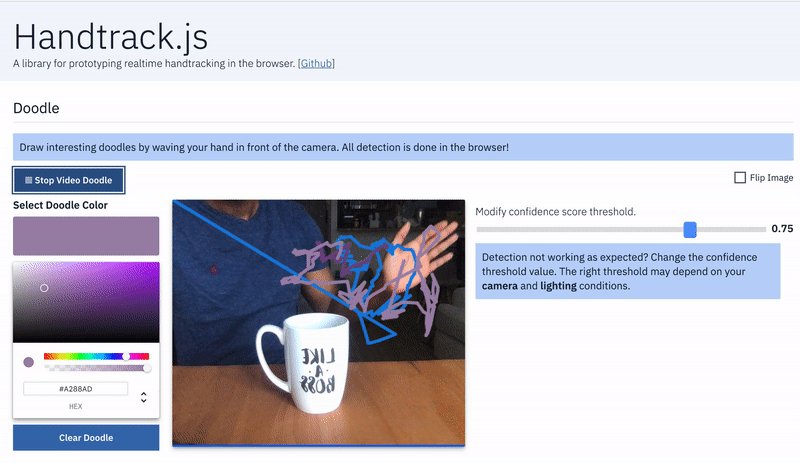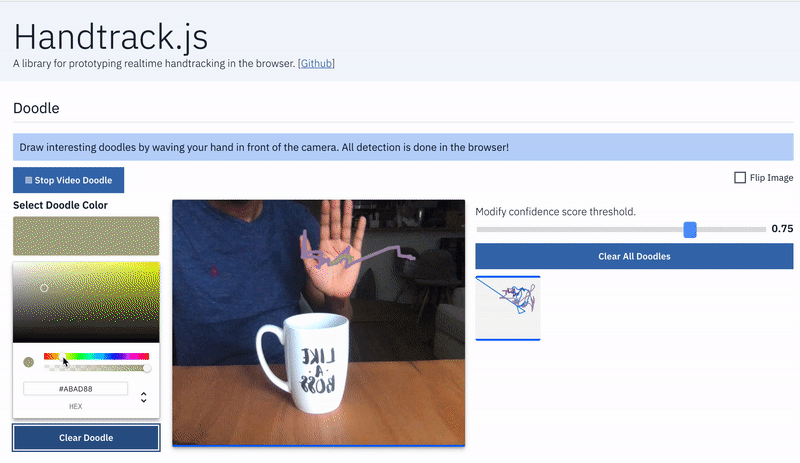
- Hand as Input Device: Game controls: map hand position to game controls
- Accessiblity: detect hands with handtrack.js and subsequently match each hand to sign language poses
- Behaviour tracking: E.g. measuring/tracking the effective use of hands as presenters deliver presentations on stage, or tracking handss to notify users when they touch their face (covid related behaviour tracking.)
So far, the library has 2400 stars on github, is used by > 154 projects on Github and has been downloaded over 15,400 times.
Handtrack.js will be continuously improved with advances in deep learning models and make these advances available to a wide set of developers.
New Version of Handtrack.js - What is New?
An earlier version of handtrack.js was created before this hackathon which has been significantly revised. Below are some limitations of the previous version which have now been addressed:
- Dataset: The previous version of handtrack.js was trained using the Egohands dataset (4800 images). This dataset contained polygon annotations of hands (converted to bounding boxes) captured from an egocentric viewpoint (user wearing a Google glass headset and recording their point of view). An important challenge here is that this dataset does properly cover the viewpoint of a user facing a webcam (the primary viewpoint in a desktop machine).
- Hand pose labels: The previous version of handtrack.js only provided a single hand label - hand. It did not distinguish between any canonical set of hand positions (e.g. open, closed, pointing etc). While understanding the location of hands is already useful, it is challenging to prototype control sequences with only a single state.
- Model load time: The previous model weights were 18.5mb sharded across 5 files. Loading these files incurred some delay which
- Model accuracy: The previous model struggle to distinguish between faces and hands. Given that there were no annotations on face, the model just does not have sufficient discriminant signal to correctly separate face from other labels.
Below are a key list of updates that have been implemented as part of this hackathon:
- New dataset curation: A completely new dataset (~2000 images, 6000 labels) has been curated. The current version is focused on the viewpoint of a user facing a webcam. Details on data collection are listed below. Note that the dataset is not released (mostly because it contains personal information on the participants and effort is still underway to extract a subset that is free of PII).
- New labels: Following extensive review of the usecases for an earlier version of handtrack.js (e.g. game controls, detect face touching to minimize covid spread etc), a new set of hand pose labels have been curated:
- Open: All fingers are extended in an open palm position. This represents an open hand which can be the drop mode of a drag and drop operation.
- Closed: All fingers are contracted in a ball in a closed fist position. The closed hand is similar to the drag mode for a drag and drop operation.
- Pinch: The thumb and index finger are are together in an picking gesture. This can also double as a grab or drag mode in a drag and drop operation.
- Point: Index finger is extended in a pointing gesture.
- Face: To help disambiguate between the face and hands, and to also enable face tracking applications in the same library, a face label is also added.
- Open: All fingers are extended in an open palm position. This represents an open hand which can be the drop mode of a drag and drop operation.
- Reduced Model size: In this version, experiments are conducted with multiple object detection model architectures (SSD FPN lite, CenterNets, EfficientDet) and with multiple input image sizes. Currently an SSD MobileNet v2, FPN lite model with input size 320x320px is being used and results in a model size of 12MB. Further, this model has been fp16 and int8 quantized with comparable results yield model sizes of 7MB and 3MB respectively. This results in an overall faster load time and better user experience.
- Model Accuracy: Early testing shows the new model to be more accurate for the front facing web cam viewpoint detection. The inclusion of face labels also reduces the earlier face misclassifications
- Javascript Library: The handtrack.js library has been updated fix issues with correct input image resolutions, upgrade the underlying tensorflowjs models, provide more customization options (e.g. use of small medium or large base models)
Azure ML
Azure Machine Learning is used to enable the handtrack.js workflow in the following ways:

- ML Assisted Data Labeling: The Azure ML data labeling tool is used to label > 2000 images.
- Azure AutoML: This feature is is used to rapidly train an early version of the model which is used in prelabelling images and also used in finetuning the data collection process.
- Azure ML Notebooks: Are used to train multiple versions of the model, and export model targets in python and javascript for use in handtrack.js.
How we built it

Handtrack.js frames the task of detecting/tracking hands as an object detection problem (for a given image, predict the bounding box location of objects and their class names). Consequently, object detection models are explored in solving the task. The high level overview of the process is structured as follows:
- Data Collection and Annotation: The goal here was to collect data that supports a set of hand pose requirements (defined above). In addition, there was a focus on collecting data that mirrors the envisioned use case scenario (user facing a webcam under varied lighting conditions).
Model Training: Pipeline for training a set of object detection model architectures ( ssdMobileNet320fpnlite, ssdMobileNet640fipnlite, efficientdet512d0, and CenterNetMobileNet512). The Tensorflow Object Detection API was used to bootstrap these experiments, starting with pretrained model check points which were then finetuned on our custom data.
Model Evaluation: Pipeline for comparatively evaluating all of the trained model architectures on a test subset of the annotated data.
Model Export: Multi stage pipeline to export each trained model. First export the trained model checkpoints to the Tensorflow Saved Model Format (Python) and then to quantize the models and export to Tensorflow.js web model format.
Library Design, Testing: The web models are rolled into a javascript library which is bundled using parcel.js (hosted on npm and served over a cdn). A set of tests and demos are then used to rigorously test out the capabilities of library.
Accomplishments that we're proud of
- Solving Tensorflow API version issues required to successfully convert object detection models from checkpoints to javascript web model format.
- Creating an automated pipeline to enable low touch model retraining.
- New videos (of participants with various hand poses) are added to a storage bucket.
- Train sample generator. Converts videos into videos at 2 frames per second.
- Each frame is then written to an azure bucket
- Azure labeller automatically monitors this bucket for new data points and survaces them for labelling
- Script fetches label json from ML azure
- Labelled data is converted into train test, validation sets and written to a bucket
- Train/test/validation is converted into Tensorflow records .. the format required for use with the Tensorflow object detection model and written to a storage bucket
- Model training scripts use these output files to automatically train multiple model sizes . Currently the focus is on ssdMobileNet320fpnlite, ssdMobileNet640fipnlite, efficientdet512d0, and CenterNetMobileNet512.
- Automatic eval script evaluates the produced checkpoints
- Model export .. converts each of these saved model files to Tensorflow.js compatible models which can be used in the browser. Overall, this pipeline has been extremely useful in achieving substantial improvements to and iterations over the model within a short amount of time:
- Automated export of web model which are imported into test/demo code
- Multiple images, videos and live videos are used to test the model
- New data (videos) covering failure modes are curated/collected. They are then converted to image frames and uploaded to azure blob storage where they are automatically prelabelled and then finetuned
- Model is retrained with new data and exported.
- Creating a complete new dataset to to support a new set of hand poses. Currently this includes … .Data collection will be continuous (and possible due to the automated pipeline above) with the goal of addressing observed deficits in tracking as the model is used.
- Completely redesigned the handtrack.js demo page
- Improved user experience to ensure image and video aspect ratio is maintainedd
- Rewrite the demo to use React hooks
What we learned
- Writing ML pipelines for automating ML processes
- Working with the Azure ML Assisted Lebeling tool
- Rebuilding the front end demo for improved user experience. I used React, React Hooks, Tailwindcss for layout and parcel.js.
What's next for Handtrack.js : Real Time Handtracking in the Browser
- Further model optimization. The current best performing model in the benchmark (ssd mobilenet fpnlite 320) is still not fast enough. While usable at ~10 FPS on a 2018 macbook pro, a 30 FPS frame rate is the current target. To achieve this, a few things are being done
- Revise the current model graph e.g. extract non max suppression ops from the model graph and perform that on CPU backend instead of GPU shaders
- Explore CenterNets - an anchor free object detection model model architecture which is faster.
- Library Documentation:
- Create additional example apps that demonstrate "body as input device" interaction e.g. with applications in accessible interfaces for individuals with impairments.
- Community blog post series that covers the end to end experience building and optimizing an object detection model for a custom use case. The following posts are currently being worked on:
- Data collection and annotation with Azure ML Labeling
- Transfer learning for Object Detection with the Tensorflow Object Detection API
- Optimizing Tensorflow models (quantization, pruning)
Built With
- machine-learning
- python
- tensorflowjs





Log in or sign up for Devpost to join the conversation.