



🧠 HandSpeaker: Project Story
🌍 Inspiration
Communication between deaf or hard-of-hearing individuals and non-signers remains a major barrier in everyday interactions. While sign language is rich and expressive, most existing digital solutions rely on static gesture recognition, which fails to capture the true nature of sign language.
Sign language is inherently spatiotemporal: meaning depends not only on hand shape, but also on motion, trajectory, and timing. This limitation inspired us to rethink the problem:
What if we could move beyond static gesture classification and enable systems to understand motion as language?
With the rise of AR devices like Spectacles, which provide real-time hand tracking, we saw an opportunity to build a more natural, real-time, and scalable solution.
💡 What We Built
We built HandSpeaker, a real-time sign language translation system powered by AR-based hand tracking and dynamic gesture understanding.
Our system supports:
- Static gesture recognition (frame-based)
- Dynamic gesture recognition (trajectory-based)
- Real-time translation output (text / speech via WebSocket)
- Data collection and annotation pipeline for future AI training
Instead of relying on RGB images or depth sensors, our system directly operates on:
3D hand joint transforms (position + rotation)
This allows us to bypass traditional computer vision pipelines and focus on structured motion understanding.
⚙️ How We Built It
1. Real-time Hand Tracking (AR Input)
We use AR Spectacles to capture:
- 3D joint positions
- joint rotations
- continuous hand motion streams
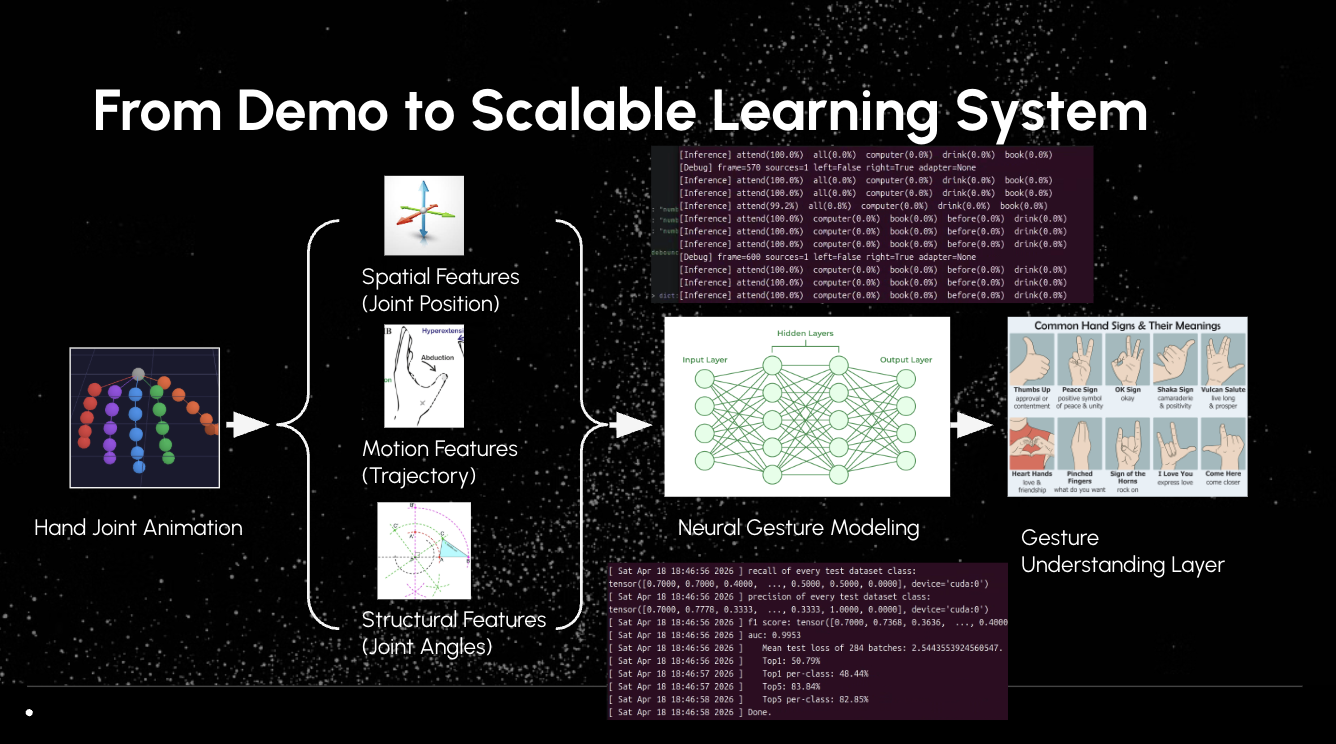
2. Feature Extraction
We decompose hand motion into three key feature types:
- Spatial Features: joint positions
- Motion Features: trajectory and velocity
- Structural Features: joint angles
This creates a rich representation of hand movement.
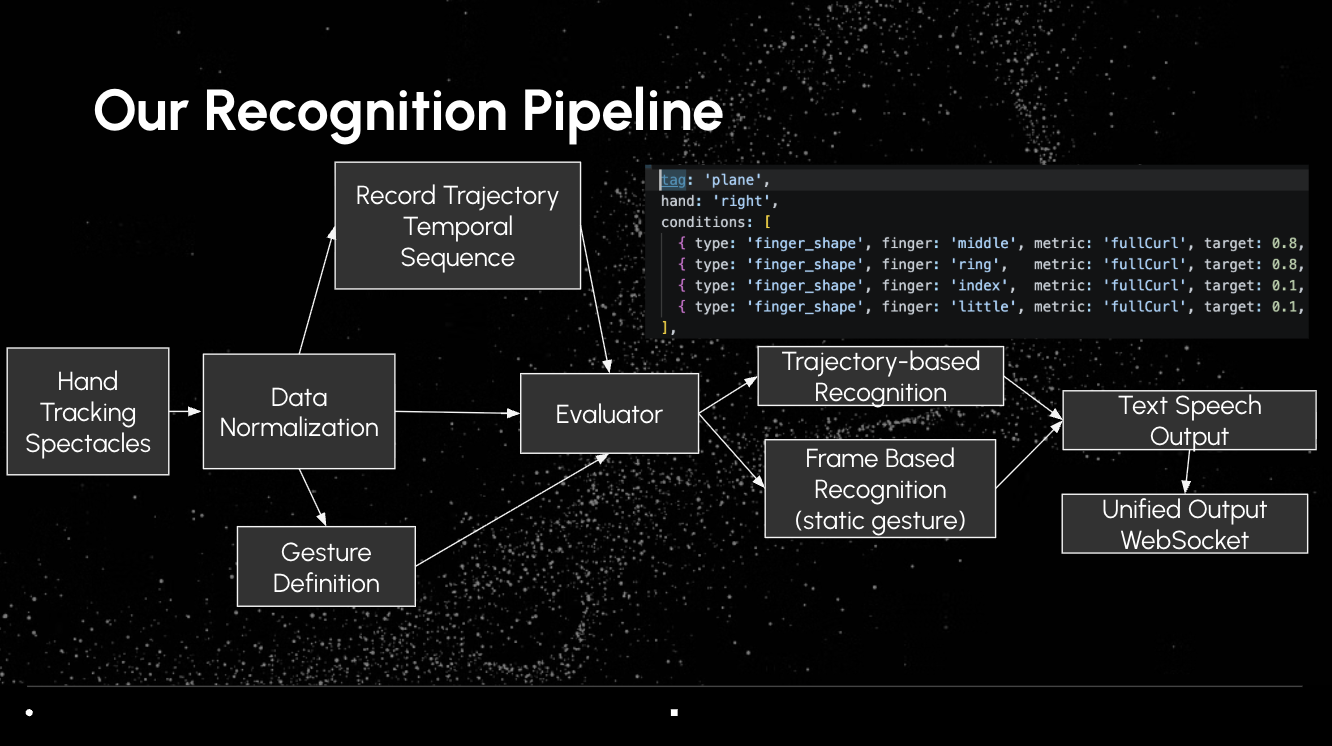
3. Unified Gesture Recognition
Instead of separating static and dynamic gestures at the system level, we treat all gestures as temporal sequences:
- Static gestures → short sequences
- Dynamic gestures → longer trajectories
We then apply a lightweight recognition pipeline (rule-based + extendable to ML models) to classify gestures.
4. Real-time Output System
Recognized gestures are sent via WebSocket to:
- a frontend interface
- text or speech output modules
This enables low-latency interaction.
5. Data Collection & Annotation Pipeline
To make the system scalable, we built a full data pipeline:
User Gesture → 3s Recording → Upload → Preview → Label → Dataset
Our web interface allows:
- gesture playback (timeline visualization)
- manual labeling
- dataset management
This transforms user interaction into training-ready data.
🚧 Challenges We Faced
1. Static vs Dynamic Gesture Representation
Most existing systems treat gestures as single frames.
We had to rethink recognition as a sequence problem, not a classification problem.
2. Temporal Segmentation
Detecting when a gesture starts and ends is non-trivial.
We introduced trigger-based recording and fixed-length capture (3s) to simplify this.
3. Lack of Training Data
There is no readily available dataset for 3D hand joint trajectories.
We solved this by building our own data collection and annotation system.
4. Real-time Constraints
We needed the system to be:
- fast
- responsive
- stable in live demo conditions
So we used lightweight recognition methods instead of heavy models.
📚 What We Learned
- Gesture recognition is not just a vision problem, but a spatiotemporal modeling problem
- Structured 3D data (joint transforms) can significantly simplify the pipeline
- Building a data pipeline is as important as building the model itself
- For real-world interaction, latency and robustness matter more than model complexity
🚀 Future Work
We plan to extend HandSpeaker into a full learning system:
- Replace rule-based recognition with:
- LSTM / Transformer models
- LSTM / Transformer models
- Expand from word-level to sentence-level translation
- Incorporate:
- facial expressions
- body pose
- facial expressions
- Enable continuous, unsegmented sign language understanding
🎯 Conclusion
HandSpeaker is not just a gesture recognition demo.
It is a step toward:
understanding motion as language
By combining AR input, trajectory-based modeling, and a scalable data pipeline, we move closer to real-time, natural communication between signers and non-signers.
Built With
- typescript
- websocket


Log in or sign up for Devpost to join the conversation.