-
-
-
-
architecture diagram
-
-
Running in Google Cloud
-
Sessions in Firestore
-
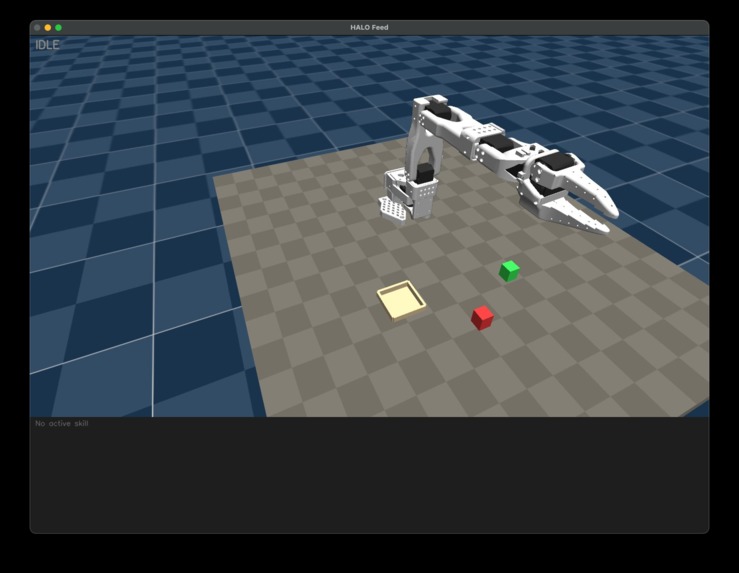
-
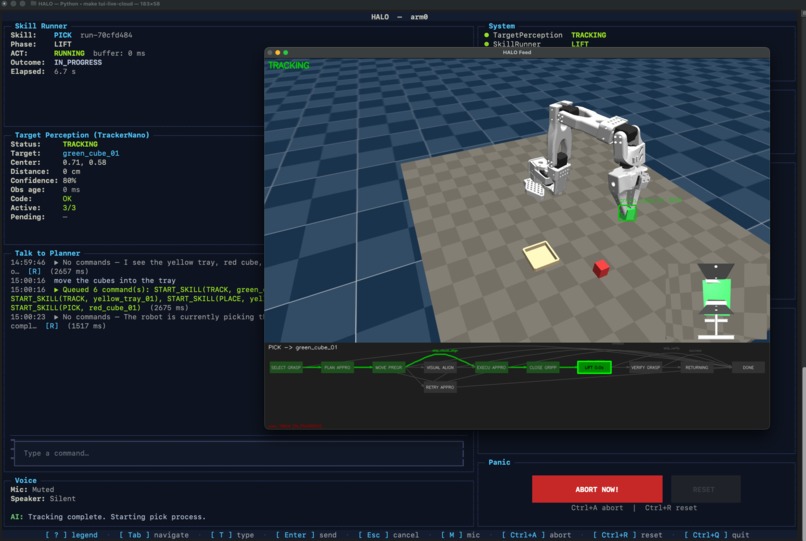
-
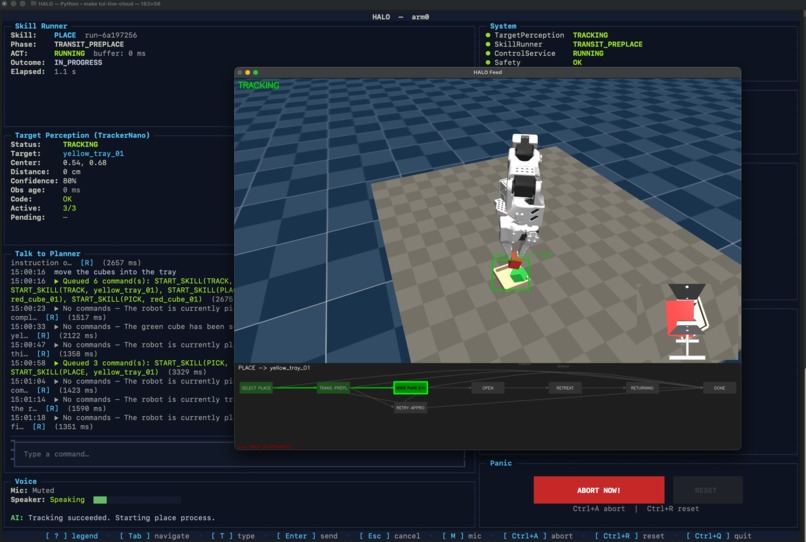
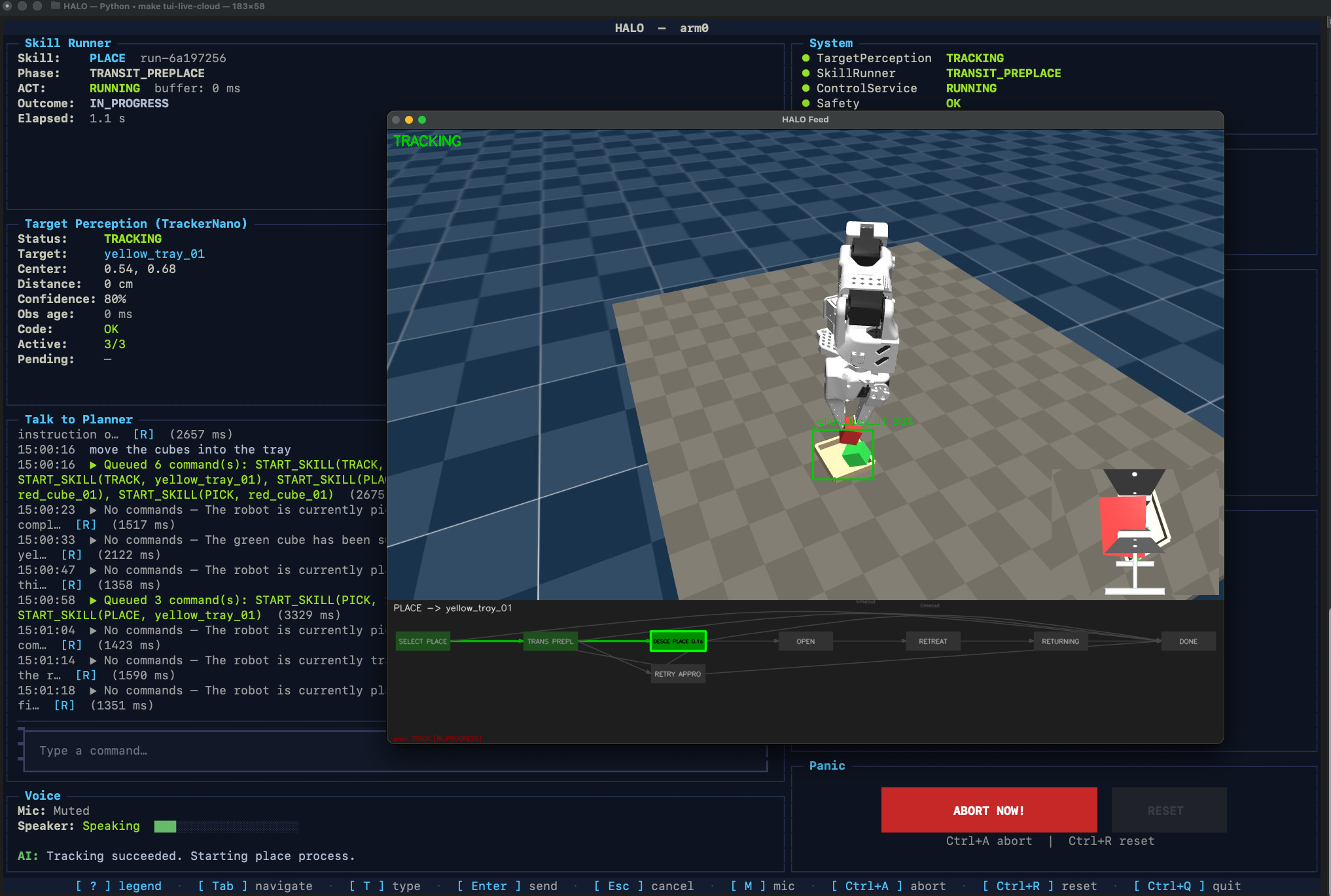
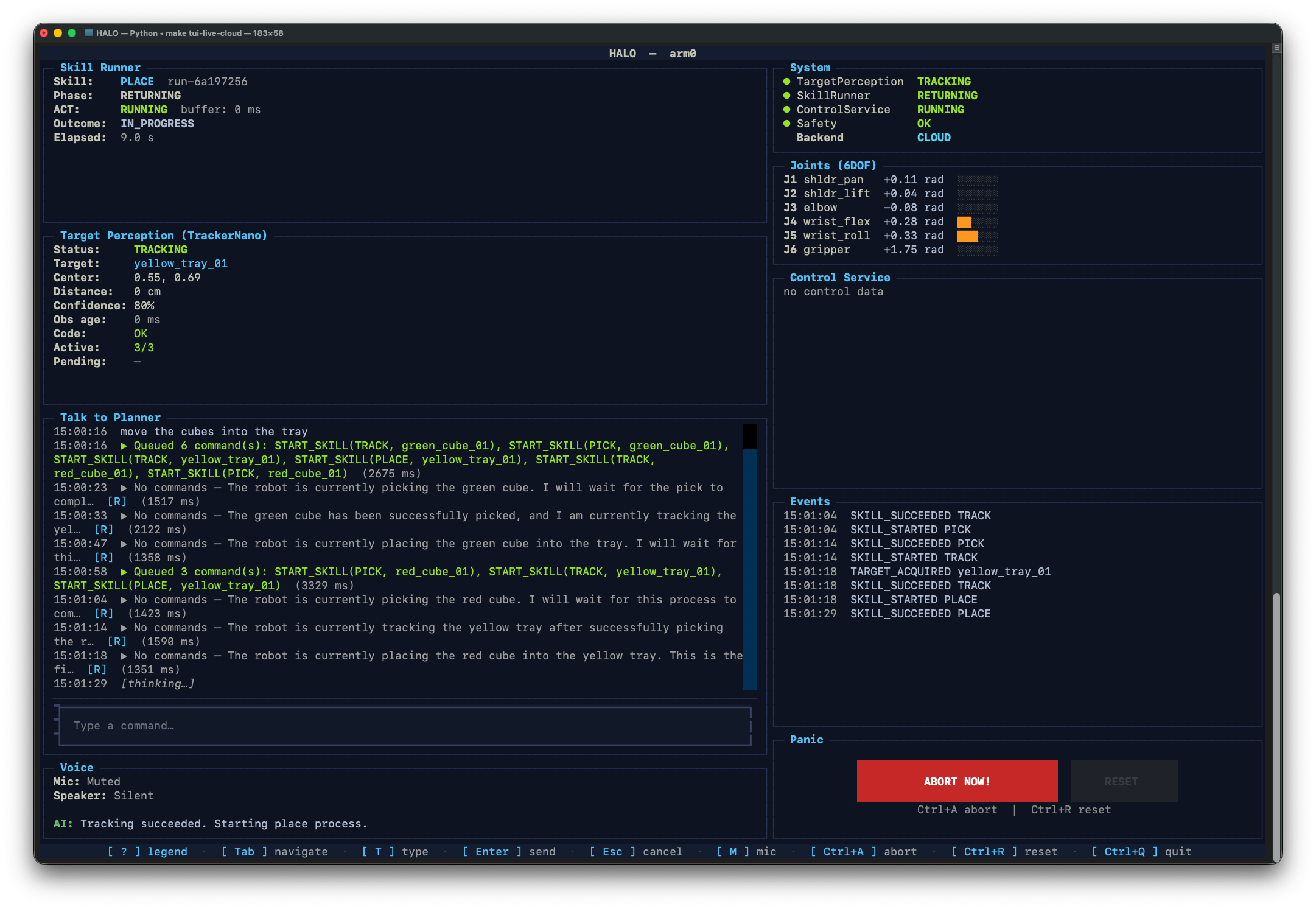

Inspiration
Most robot-agent demos still work in stop-and-go mode: the robot moves, waits for the AI to think, and only then continues. That makes the interaction feel unnatural and breaks continuous control.
Vision-Language-Action (VLA) models approach the problem from the other side by mapping perception and language directly to actions. That is promising for learned low-level behavior, but it does not by itself address live conversation, interruption handling, high-level task orchestration, or reliable failover in a deployed robot system.
We wanted a middle path: a live multimodal robot agent that keeps moving while the AI thinks, while still supporting natural voice interaction and explicit task planning. That led us to build HALO — Hierarchical Adaptive LLM-Operated Robot — a manipulation system that separates conversation, planning, and perception from real-time control.
What it does
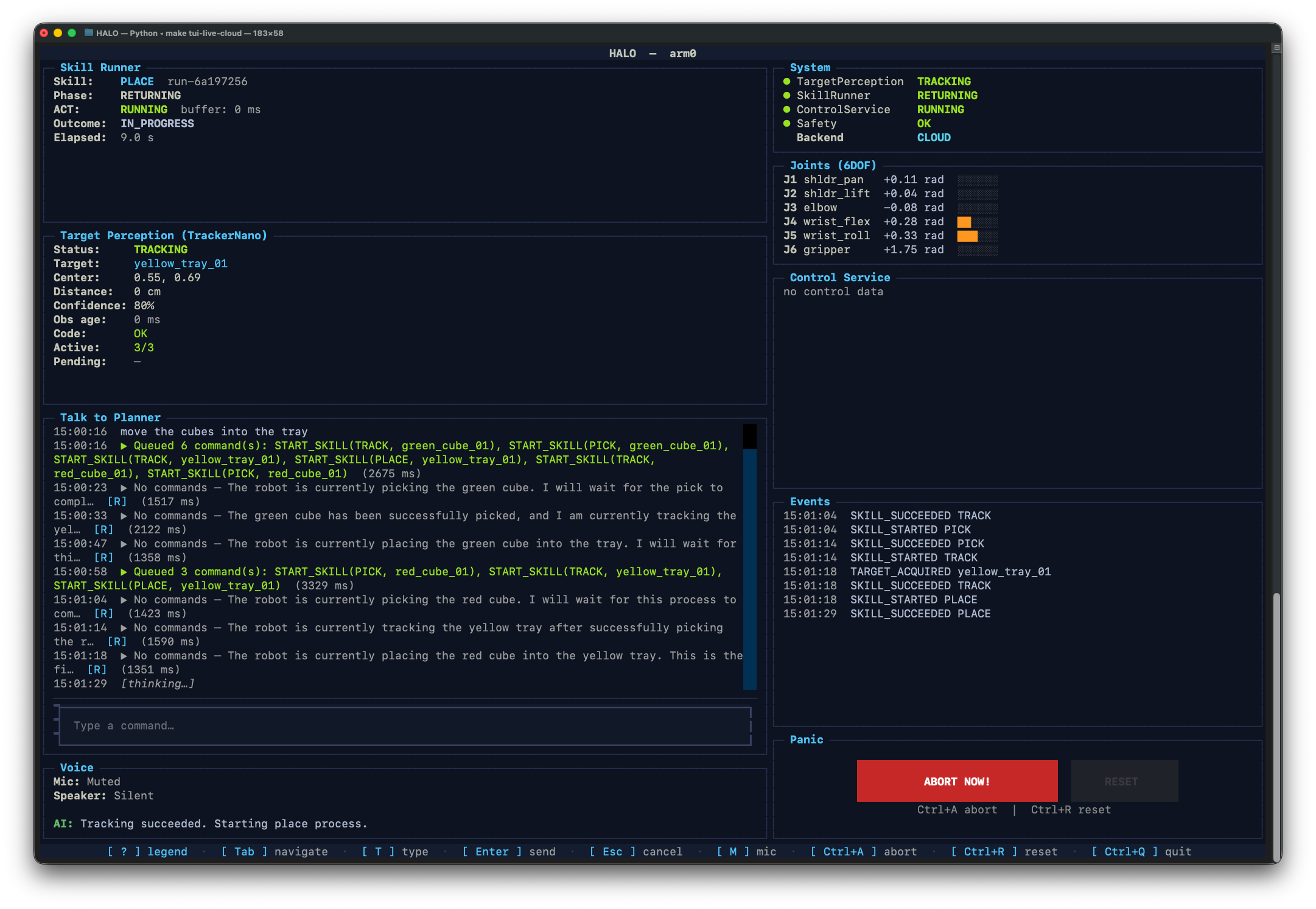
HALO is a robotic manipulation system with a conversational voice interface and autonomous skill orchestration, built for continuous control rather than stop-and-wait execution.
Instead of treating the robot as a single prompt loop, HALO splits its brain into three parts:
- The Live Agent uses the Agent Development Kit (ADK) Gemini Live API Toolkit (Bidi-streaming) to handle voice interaction, narration, intent capture, and barge-in.
- The Planner is an LLM planner built with the Agent Development Kit (ADK), using a Reason + Act (ReAct) planning loop that turns operator intent into high-level actions and orchestrates robot skills asynchronously.
- The Vision-Language Model (VLM) / Perception layer handles scene understanding and target perception off the critical path, so vision latency does not block motion.
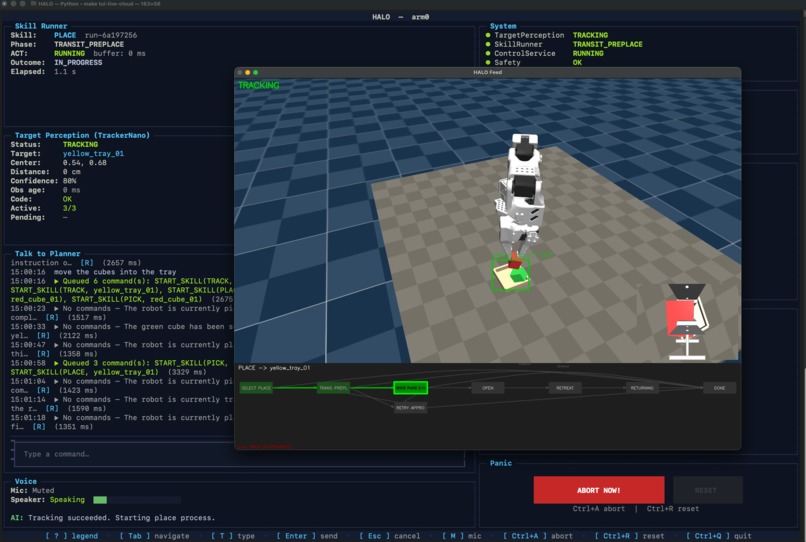
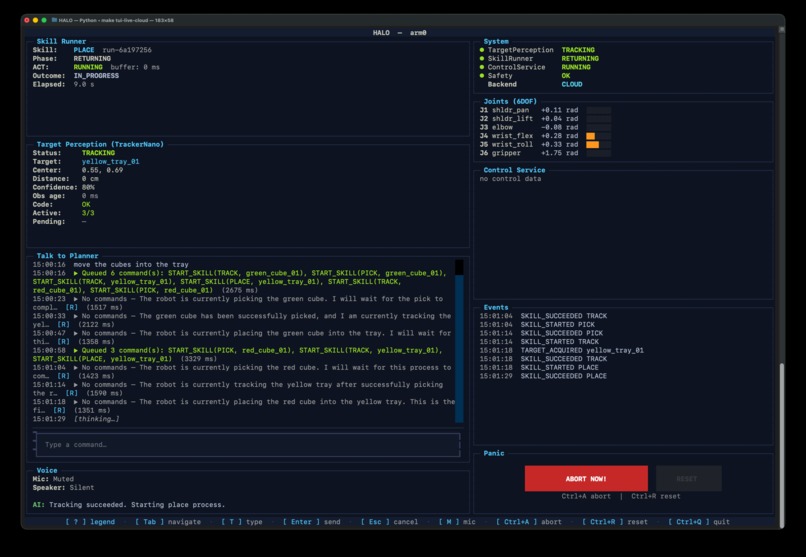
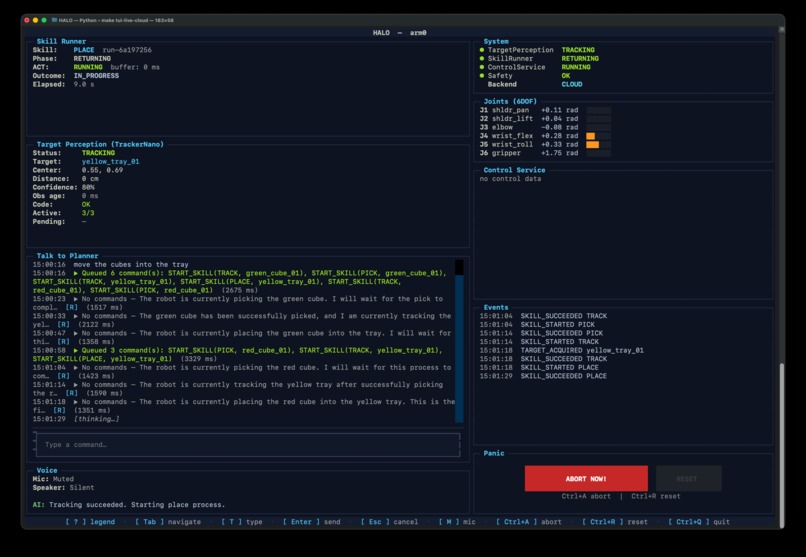
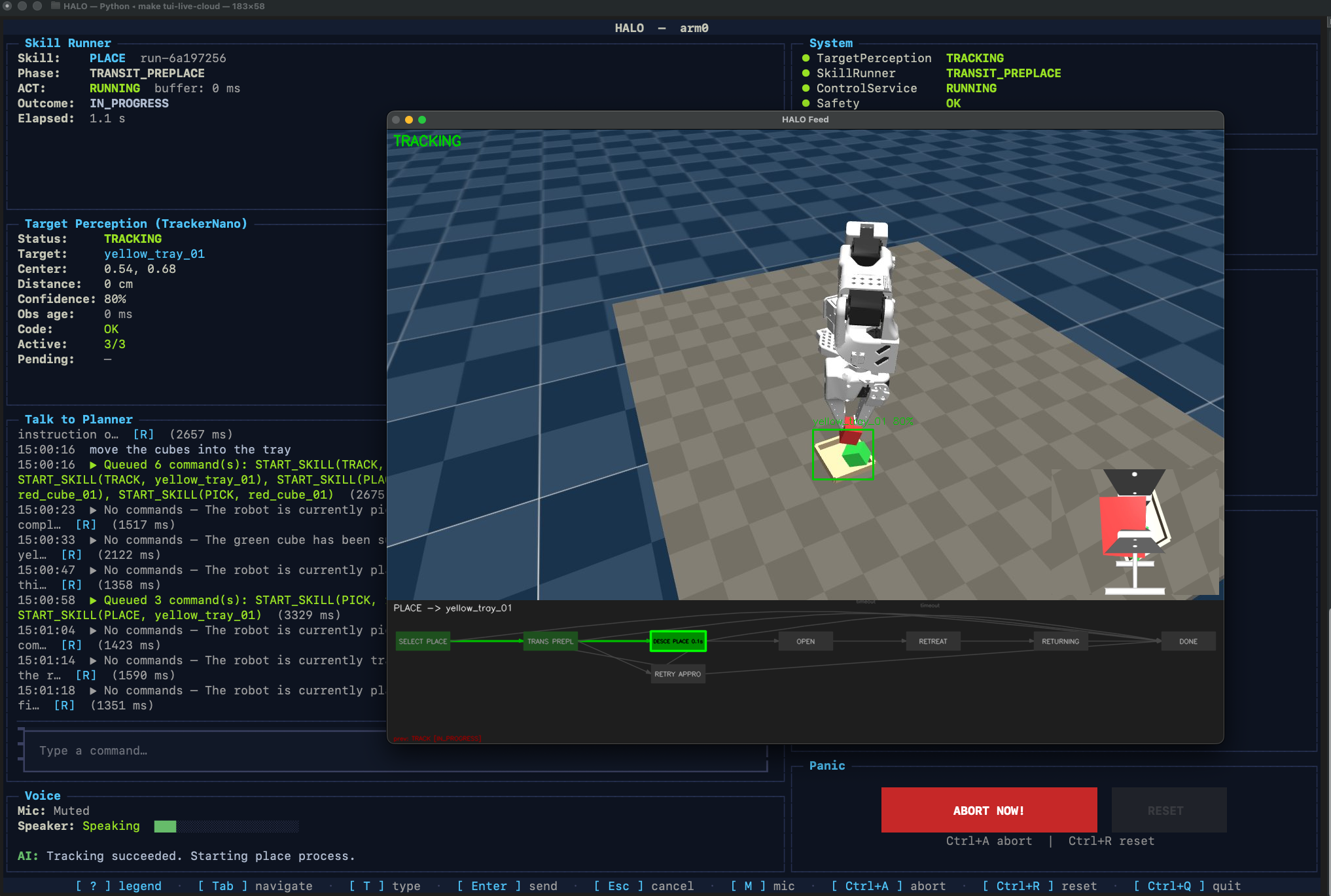
In practice, this means HALO can listen, narrate, plan, and update perception while the robot keeps moving under fast local control. Perception and control run machine-to-machine at up to 100 Hz, while the conversational and planning layers stay outside the timing-critical loop. That means motion continuity and physical safety are not bottlenecked by network latency or large language model (LLM) inference time.
How we built it
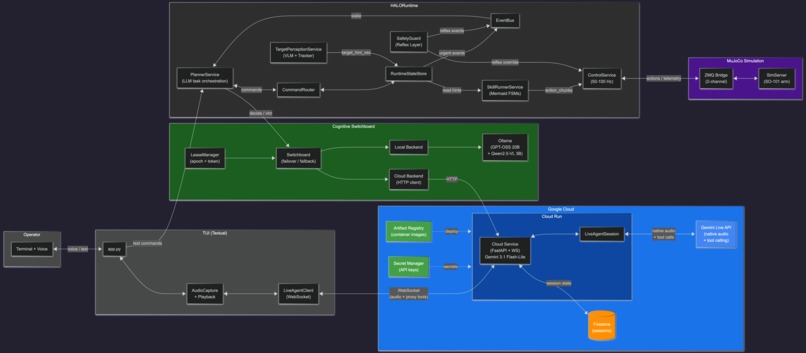
HALO combines cloud reasoning, local execution, and deterministic control into one architecture.
Live voice interaction with Gemini Live API We used the Gemini Live API via ADK with StreamingMode.BIDI for the conversational layer. This gives HALO a persistent live session for bidirectional audio, real-time transcription, narration, and interruption handling without stitching together separate automatic speech recognition (ASR) and text-to-speech (TTS) systems.
Asynchronous planning with ADK The Planner was built as an LLM agent with ADK, using a ReAct planning loop. It reasons over lightweight abstractions such as scene state, target distance, and confidence instead of raw motor telemetry, then triggers robot actions asynchronously without entering the real-time control loop.
Separate perception from planning HALO keeps fast tracking local and runs VLM scene understanding asynchronously. The Planner consumes compact, current state while control keeps running independently. This keeps perception useful without letting vision-model latency block motion.
Proxy-tool architecture Gemini runs in the cloud, but the freshest robot state exists locally. To bridge that gap, we built a proxy-tool architecture: the cloud agent calls tool stubs, those calls are intercepted, sent over WebSockets, and executed locally against the live robot state.
Visual finite-state machine (FSM) engine Physical skills such as pick, place, and track are authored as Mermaid
stateDiagram-v2graphs. At startup, these are parsed into immutable execution graphs, making skill progression and recovery deterministic and independent of the LLM.
Challenges we ran into
The perception gap Vision-language models can take hundreds of milliseconds to even seconds to interpret a scene, but the robot needs much faster updates to stay responsive. We solved this with frame-buffer replay: while the VLM runs asynchronously, a ring buffer stores incoming frames. Once the VLM returns a target, the tracker replays through the buffered frames so the robot does not lose continuity during the inference window.
Preventing split-brain failovers A real robot cannot simply stop because Wi-Fi drops. HALO can fail over from the cloud backend to a local backend running Ollama with
gpt-oss:20bfor planning andqwen2.5vl:3bfor perception. The hard part was preventing delayed cloud commands from colliding with local ones. We solved that with a LeaseManager that stamps every command with an epoch token, instantly invalidating stale commands from the inactive backend.Keeping long live sessions responsive Long-running sessions accumulate transcripts, tool histories, and state updates. We built a context-compaction layer that summarizes older context while preserving the most recent turns, so the agent stays responsive without losing task awareness.
Accomplishments that we're proud of
- Building a robot stack where motion continues smoothly even when LLM or VLM latency spikes.
- Routing cloud-based Gemini interactions to a local hardware controller over WebSockets with no operator-visible lag.
- Creating a robust cloud/local failover path between Google Cloud Run and the local machine, backed by an append-only ContextStore journal for state synchronization.
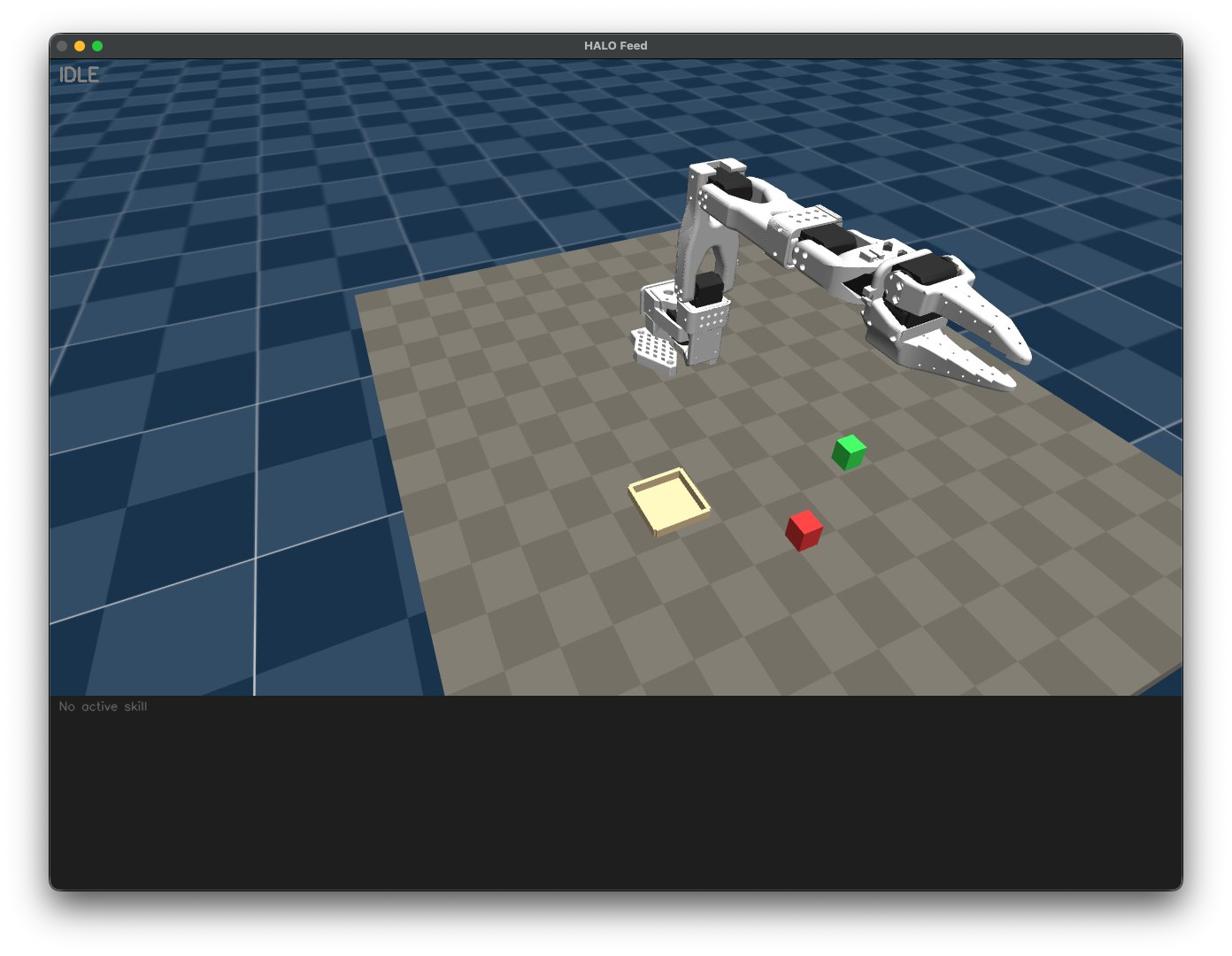
- Validating the architecture in MuJoCo on the SO-ARM101 development target.
What we learned
Architecture matters more than model size. A smaller, faster planner with the right abstractions is often more useful than a larger model exposed to raw telemetry.
Robotics systems must be designed for failure. Network drops, perception latency, and grasp failures are not edge cases. They are normal operating conditions that need explicit fallback paths.
LLMs do not belong in the hot path. The moment inference sits inside the timing-critical loop, you no longer have a robust system. You have a fragile demo.
What's next for HALO
HALO is currently validated in MuJoCo with the SO-ARM101 development target. The next step is deploying the same pipeline to physical hardware.
We also plan to extend the simulation data pipeline into a demonstration-generation workflow for future imitation learning, using teacher-generated episodes from simulation to train faster low-level policies for real-world manipulation.

Log in or sign up for Devpost to join the conversation.