Inspiration
A stroke or aphasia takes the words, not the person. Someone can know exactly what they want to say and be unable to get it out, and the "solution" on offer is a five-figure device with a months-long insurance fight and a stranger's robotic voice. The same thought-to-word gap is lived every day by minimally verbal autistic people. We wanted to give that back, for free, in a browser, in the person's own voice, and to keep them the author of every word.
What it does
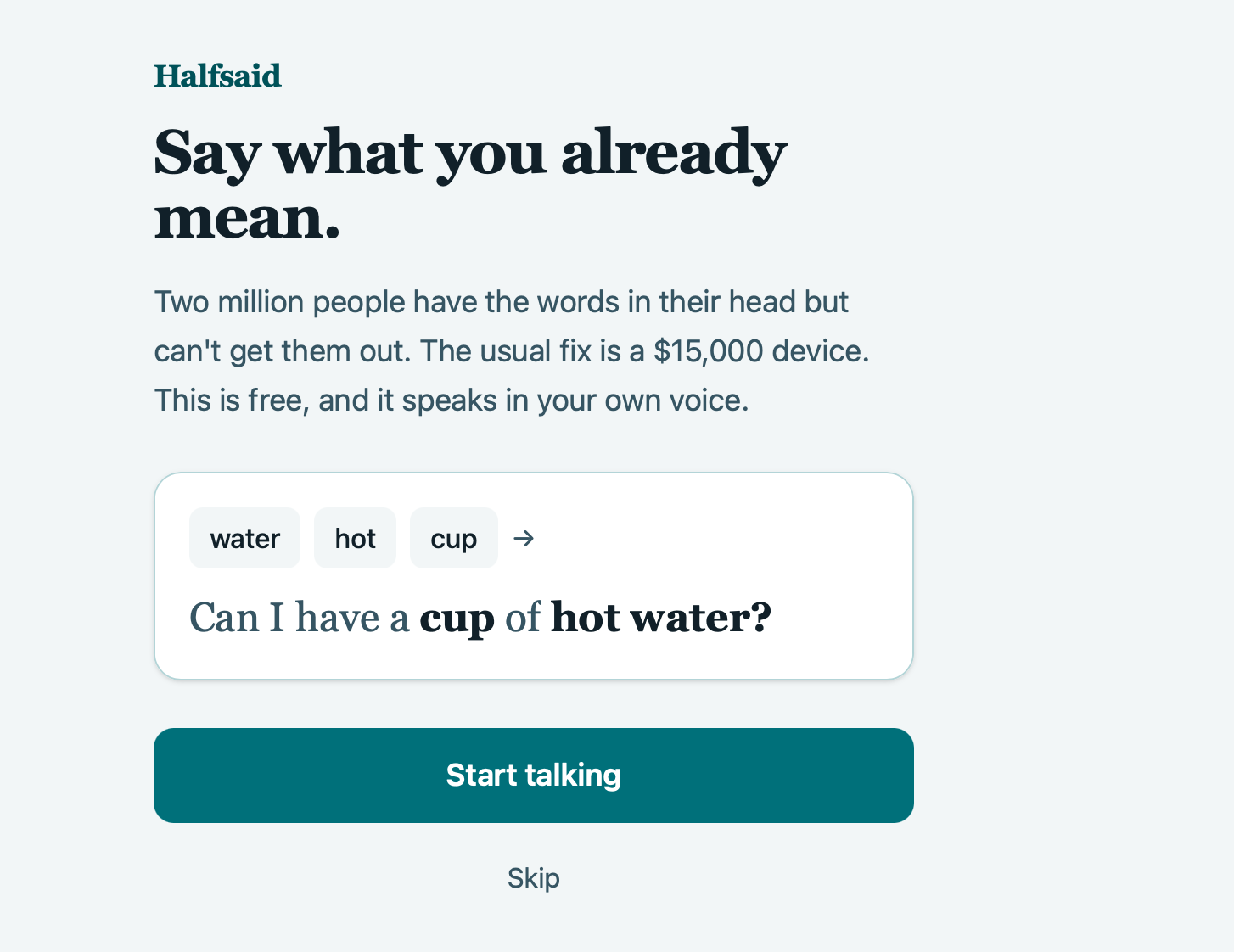
You tap a few broken word-fragments, water · hot · cup, and Halfsaid
reconstructs the short sentence you already mean, "Can I have a cup of hot
water?", then speaks it aloud.
- You watch it assemble. The sentence builds word-by-word on screen: the words you tapped stand as bold pillars, the connective words the AI added fill the gaps in lighter ink. You literally see the bridge being built, and you stay the author, confirming or rejecting a guess in one tap.
- It speaks in your own voice, cloned from a short old recording, not a robot.
- It knows your world. A gentle, caregiver-friendly setup records the people, places, and needs in your life so reconstructions are grounded in who you are.
- It hears the room. A partner mic transcribes the question someone asked you so your sentence answers it directly.
- It works offline and installs to your home screen, because a person needs to communicate even when the wifi doesn't.
Designed for the cognition it serves: huge targets, no timers, high contrast, keyboard and switch access, reduced-motion respected.
How we built it
- Frontend: SvelteKit (Svelte 5 runes) + Tailwind v4, an installable, offline-capable PWA, deployed on Vercel.
- Backend: a small Hono API on Fly.io that holds the model keys. Three endpoints: reconstruct, speak, clone.
- Reconstruction: OpenRouter (model-agnostic) turns telegraphic fragments into faithful first-person sentences, with the user's profile passed as inert, injection-safe context, never as instructions.
- Voice: ElevenLabs for text-to-speech and Instant Voice Clone.
- Partner mic: the Web Speech API.
- The "watch it assemble" moment is a custom component that classifies each word as the user's own fragment versus the AI's connective glue and animates them in.
Challenges we ran into
- Keeping the human the author: the AI must propose, never decide, and a wrong guess has to be rejectable in a single tap. The color-coded assembly is what makes that visible.
- Treating the personal profile as untrusted data so a caregiver's note can never be obeyed as a prompt.
- Making the whole thing degrade gracefully: no key, no signal, denied mic, unsupported browser, every path still lets the person speak.
- Splitting the keys onto a separate backend so the browser never sees them.
Accomplishments that we're proud of
A genuinely usable, end-to-end communication tool, free in a browser, that out of the box does what a $15,000 device does and adds the one thing it cannot: your own voice. Every surface works, on a phone, offline.
What we learned
How much of accessibility is restraint, not features: big targets, no timers, plain language, and never making the person wait or guess. And that the most moving AI moment is not the AI talking, it is the AI getting out of the way so a person can.
What's next for Halfsaid
Real-time streamed assembly, a richer phrasebook that learns over time, switch and eye-gaze input, and getting it into the hands of a speech-language pathologist and real users to learn what we got wrong.
Built With
- claude
- fly.io
- openrouter
- python
- svelete
- tailwindcss

Log in or sign up for Devpost to join the conversation.