-

-

ASL Working with the B Character
-

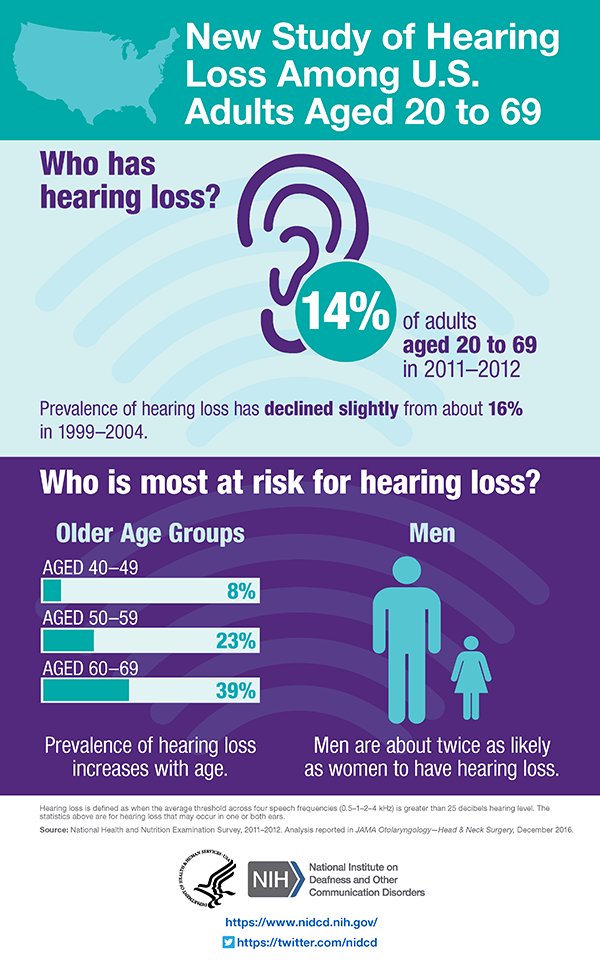
Hearing Loss Data
-

Website Landing


Inspiration
We wanted to empower over 466 million people with disabling hearing loss across the world to be independent for their daily communication needs. Additionally, we wanted to use technology to bridge this increasing digital gap through empowering them to solve their own problems by contributing to a global ASL Dataset
How it works
First, we build a dataset that is capable of capturing videos for ASL Translations. Then, we are able to use such videos combined with Deep learning to automatically guess the sign almost immediately.
Our development process
We used data from Kaggle to develop a Convolutional Neural Network in Tensorflow to recognize signs in real time. After achieving a high accuracy (85%) using various techniques such as dropout and batch normalization we decided to go one step beyond. The main problem of DL models is how they tend to overfit towards the train set. We developed a platform capable of generating a bigger dataset using Django and Videoask in order to make ASL mapping much more resilient and thus, accurate in a wide variety of environments. of various American Sign Language. We also tried some masking implementations with openCV to be able to track hands automatically from videos but it was unfeasible without OpenPose.
Challenges
Learning Django well enough to launch a web-page, applying all sorts of tricks to our CNN to improve its performance from 49% to 85% and moving into more complex -and computationally expensive- DL models. Creating the right framework and pipeline to be able to feed new videos recorded in the platform to our existing model.
Accomplishments
Being able to classify the sign languages with an accuracy of 85% and creating a pipeline to allow anyone to upload their own signs and get benchmarked on it.
What we learned
Using CNN's together with video classification, failing to do openCV, all sorts of typeform tricks and how to code a website in Django.
What is next for us
Creating the biggest ASL Sign dataset by fostering collaboration, improving the accuracy, adding support for additional languages and shifting from signs to complete words (more complex due to the movement) and making OpenCV detect the bounding box automatically.





Log in or sign up for Devpost to join the conversation.