-

Home page
-
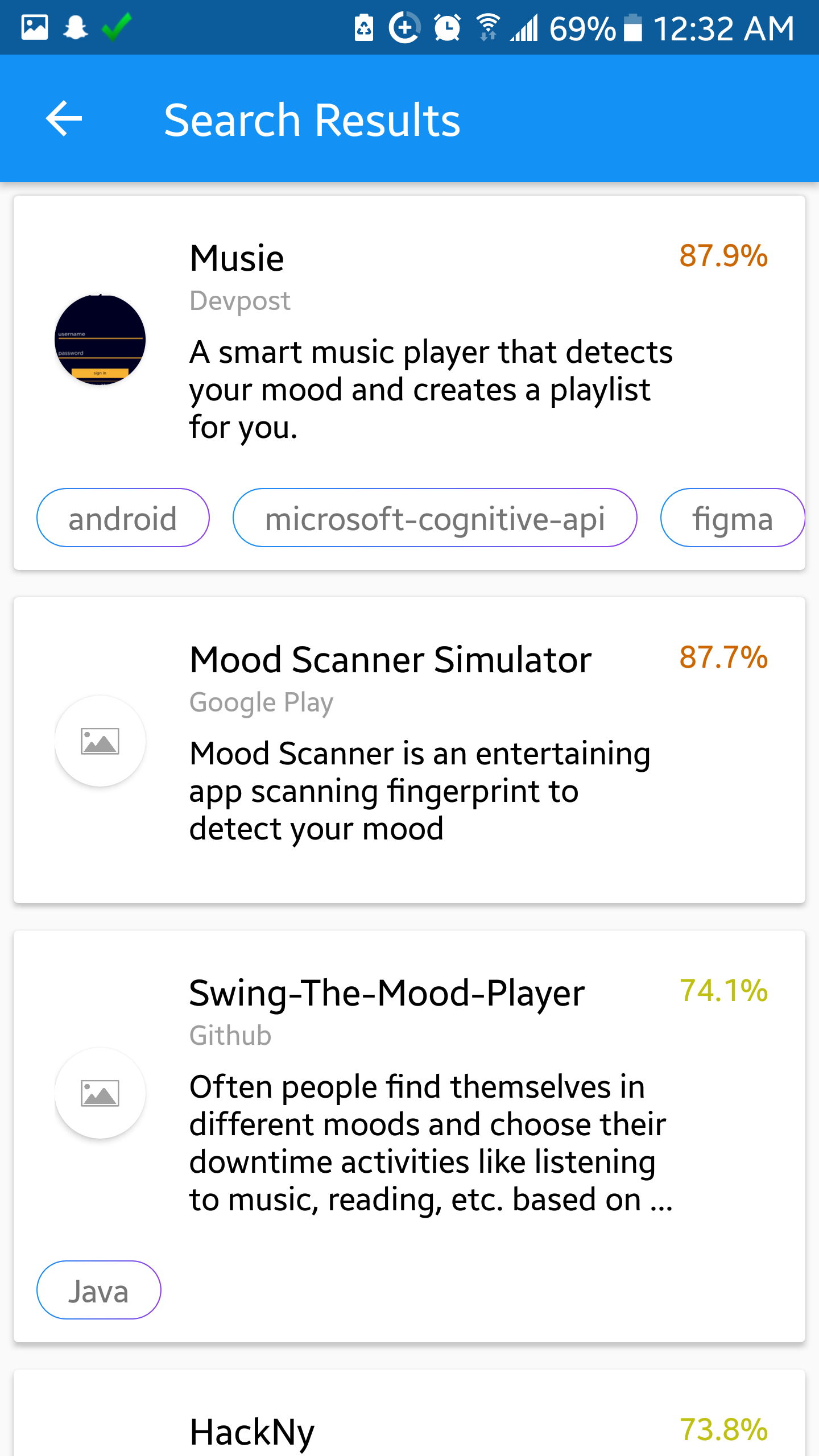
Search results for "app that detects your mood"
-

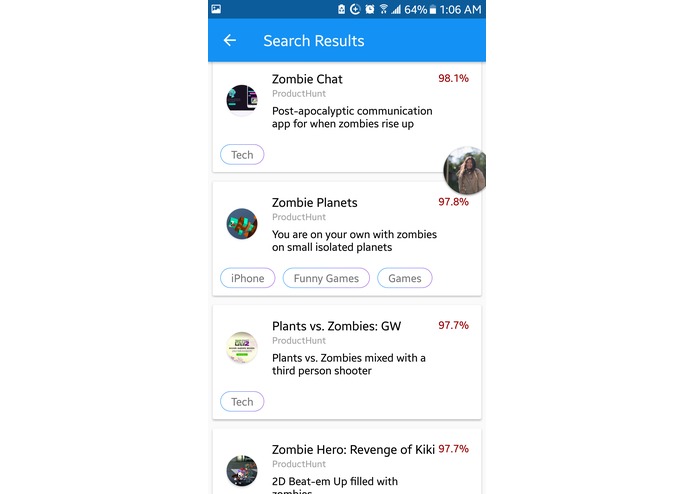
How many different zombie games can you come up with?


Inspiration
During our brainstorming phase, we cycled through a lot of useful ideas that later turned out to be actual products on the market or completed projects. After four separate instances of this and hours of scouring the web, we finally found our true calling at QHacks: building a solution that determines whether an idea has already been done before.
What It Does
Our application, called Hack2, is an intelligent search engine that uses Machine Learning to compare the user’s ideas to products that currently exist. It takes in an idea name and description, aggregates data from multiple sources, and displays a list of products with a percent similarity to the idea the user had. For ultimate ease of use, our application has both Android and web versions.
How We Built It
We started off by creating a list of websites where we could find ideas that people have done. We came up with four sites: Product Hunt, Devpost, GitHub, and Google Play Store. We then worked on developing the Android app side of our solution, starting with mock-ups of our UI using Adobe XD. We then replicated the mock-ups in Android Studio using Kotlin and XML.
Next was the Machine Learning part of our solution. Although there exist many machine learning algorithms that can compute phrase similarity, devising an algorithm to compute document-level similarity proved much more elusive. We ended up combining Microsoft’s Text Analytics API with an algorithm known as Sentence2Vec in order to handle multiple sentences with reasonable accuracy. The weights used by the Sentence2Vec algorithm were learned by repurposing Google's word2vec ANN and applying it to a corpus containing technical terminology (see Challenges section). The final trained model was integrated into a Flask server and uploaded onto an Azure VM instance to serve as a REST endpoint for the rest of our API.
We then set out to build the web scraping functionality of our API, which would query the aforementioned sites, pull relevant information, and pass that information to the pre-trained model. Having already set up a service on Microsoft Azure, we decided to “stick with the flow” and build this architecture using Azure’s serverless compute functions. After finishing the Android app and backend development, we decided to add a web app to make the service more accessible, made using React.
Challenges We Ran Into
From a data perspective, one challenge was obtaining an accurate vector representation of words appearing in quasi-technical documents such as Github READMEs and Devpost abstracts. Since these terms do not appear often in everyday usage, we saw a degraded performance when initially experimenting with pretrained models. As a result, we ended up training our own word vectors on a custom corpus consisting of “hacker-friendly” vocabulary from technology sources. This word2vec matrix proved much more performant than pretrained models.
We also ran into quite a few issues getting our backend up and running, as it was our first using Microsoft Azure. Specifically, Azure functions do not currently support Python fully, meaning that we did not have the developer tools we expected to be able to leverage and could not run the web scraping scripts we had written. We also had issues with efficiency, as the Python libraries we worked with did not easily support asynchronous action. We ended up resolving this issue by refactoring our cloud compute functions with multithreaded capabilities.
What We Learned
We learned a lot about Microsoft Azure’s Cloud Service, mobile development and web app development. We also learned a lot about brainstorming, and how a viable and creative solution could be right under our nose the entire time. On the machine learning side, we learned about the difficulty of document similarity analysis, especially when context is important (an area of our application that could use work)
What’s Next for Hack2
The next step would be to explore more advanced methods of measuring document similarity, especially methods that can “understand” semantic relationships between different terms in a document. Such a tool might allow for more accurate, context-sensitive searches (e.g. learning the meaning of “uber for…”). One particular area we wish to explore are LSTM Siamese Neural Networks, which “remember” previous classifications moving forward.






Log in or sign up for Devpost to join the conversation.